Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Aggiungere un Regione AWS a un database globale di Amazon Aurora
È possibile utilizzare la procedura seguente per aggiungere un ulteriore cluster secondario a un database globale esistente. È inoltre possibile creare un database globale da un cluster Aurora DB autonomo utilizzando questa procedura per aggiungere la prima AWS regione secondaria.
Un database globale Aurora necessita di almeno un cluster Aurora DB secondario in un cluster Aurora DB diverso Regione AWS dal cluster Aurora DB primario. È possibile collegare fino a 10 cluster di database secondari a un Database globale Aurora. Ripeti la procedura seguente per ogni nuovo cluster di database secondario. Per ogni cluster di database secondario aggiunto al database globale Aurora, ridurre di un'unità il numero di repliche Aurora consentite nel cluster di database primario.
Ad esempio, se il Database globale Aurora dispone di 10 Regioni secondarie, il cluster di database primario può avere solo 5 repliche Aurora (anziché 15). Per ulteriori informazioni, consulta Requisiti di configurazione di un database globale Amazon Aurora.
Il numero di repliche Aurora (istanze di lettura) nel cluster di database primario determina il numero di cluster database secondari che è possibile aggiungere. Il numero di istanze di lettura nel cluster database primario più il numero di cluster secondari potrebbe essere pari a 15. Ad esempio, se esistono 14 istanze di lettura nel cluster di database primario e un cluster secondario, non è possibile aggiungere un altro cluster secondario al database globale.
Nota
Per Aurora MySQL versione 3, quando crei un cluster secondario, assicurati che il valore di lower_case_table_names corrisponda al valore nel cluster primario. Questa impostazione è un parametro del database che influisce sul modo in cui il server gestisce la distinzione tra maiuscole e minuscole. Per ulteriori informazioni sui parametri di database, vedi Gruppi di parametri per Amazon Aurora.
Quando crei un cluster secondario, ti consigliamo di utilizzare la stessa versione del motore database per il primario e il secondario. Se necessario, aggiorna il primario in modo che abbia la stessa versione del secondario. Per ulteriori informazioni, consulta Compatibilità del livello di patch per switchover e failover gestiti tra regioni.
Per aggiungere un Regione AWS a un database globale Aurora
Accedi a AWS Management Console e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel riquadro di navigazione di AWS Management Console, scegli Database.
-
Scegliere il database globale Aurora che richiede un cluster di database Aurora secondario. Assicurarsi che il cluster di database Aurora primario sia
Available. -
Per Azioni, scegli Aggiungi AWS regione.
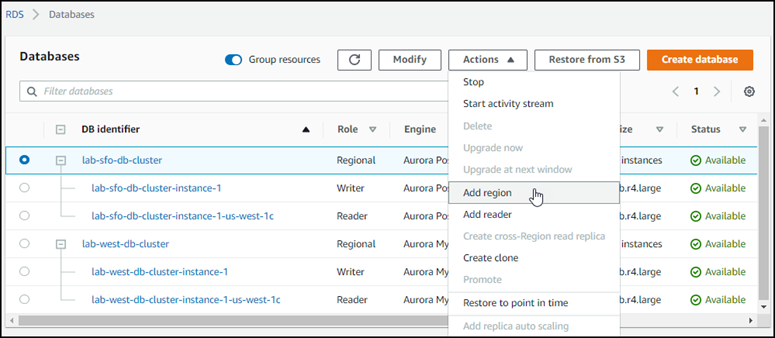
-
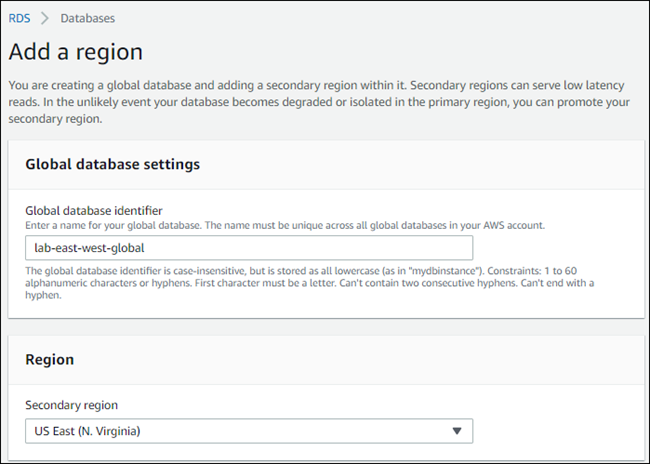
Nella pagina Aggiungi una regione, scegli la secondaria Regione AWS.
Non puoi sceglierne uno Regione AWS che abbia già un cluster Aurora DB secondario per lo stesso database globale Aurora. Inoltre, non può essere la stessa regione del cluster database Aurora primario.
Nota
I database globali Babelfish per Aurora PostgreSQL funzionano nelle Regioni secondarie solo se i parametri che controllano le preferenze di Babelfish sono attivati in tali Regioni. Per ulteriori informazioni, consulta Impostazioni del gruppo di parametri del cluster database per Babelfish
-
Completa i campi rimanenti per il cluster Aurora secondario nella nuova regione AWS . Queste sono le stesse opzioni di configurazione di qualsiasi istanza del cluster database Aurora, ad eccezione della seguente opzione solo per i database globali Aurora basati su Aurora MySQL–:
Abilita l'inoltro in scrittura di replica in lettura – Questa impostazione facoltativa consente ai cluster database secondari del database Aurora globale di inoltrare le operazioni di scrittura al cluster primario. Per ulteriori informazioni, consulta Utilizzo dell'inoltro di scrittura in un database globale Amazon Aurora.

Scegli Aggiungi AWS regione.
Dopo aver aggiunto la regione al database globale di Aurora, puoi vederla nell'elenco dei database AWS Management Console come mostrato nello screenshot.
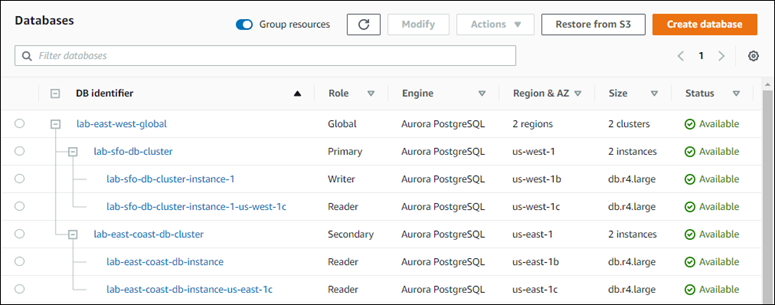
Per aggiungere un secondario Regione AWS a un database globale Aurora
Per aggiungere un cluster secondario al database globale utilizzando la CLI, è necessario disporre già dell’oggetto container del cluster globale. Se non hai già eseguito il comando create-global-cluster, consulta la procedura CLI in Creazione di un database globale Amazon Aurora.
-
Utilizzare il comando CLI
create-db-clustercon il nome (--global-cluster-identifier) del database globale Aurora. Per gli altri parametri, effettuare le seguenti operazioni: Perché
--region, scegli una regione Regione AWS diversa da quella della tua regione principale Aurora.-
Scegli i valori specifici per i parametri
--enginee--engine-version. Questi valori sono gli stessi di quelli del cluster database Aurora primario nel database globale Aurora. Per un cluster crittografato, specifica il tuo primario Regione AWS come quello
--source-regionper la crittografia.
Nell'esempio seguente viene creato un nuovo cluster di database Aurora e viene collegato a un database globale Aurora come cluster di database Aurora secondario di sola lettura. Nell'ultimo passaggio, viene aggiunta un'istanza database Aurora al nuovo cluster di database Aurora.
Per Linux, macOS o Unix:
aws rds --regionsecondary_region\ create-db-cluster \ --db-cluster-identifiersecondary_cluster_id\ --global-cluster-identifierglobal_database_id\ --engineaurora-mysql | aurora-postgresql\ --engine-versionversionaws rds --regionsecondary_region\ create-db-instance \ --db-instance-classinstance_class\ --db-cluster-identifiersecondary_cluster_id\ --db-instance-identifierdb_instance_id\ --engineaurora-mysql | aurora-postgresql
Per Windows:
aws rds --regionsecondary_region^ create-db-cluster ^ --db-cluster-identifiersecondary_cluster_id^ --global-cluster-identifierglobal_database_id_id^ --engineaurora-mysql | aurora-postgresql^ --engine-versionversionaws rds --regionsecondary_region^ create-db-instance ^ --db-instance-classinstance_class^ --db-cluster-identifiersecondary_cluster_id^ --db-instance-identifierdb_instance_id^ --engineaurora-mysql | aurora-postgresql
Per aggiungerne uno nuovo Regione AWS a un database globale Aurora con l'API RDS, esegui l'operazione CreateDBCluster. Specificare l'identificatore del database globale esistente utilizzando il parametro GlobalClusterIdentifier.
