Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un cluster database Babelfish per Aurora PostgreSQL
Babelfish for Aurora PostgreSQL è supportato su tutte le versioni supportate di Aurora PostgreSQL, 13 e successive.
Puoi usare AWS Management Console o the AWS CLI per creare un cluster Aurora PostgreSQL con Babelfish.
Nota
In un cluster Aurora PostgreSQL, il nome del database babelfish_db è riservato a Babelfish. Creare il proprio database “babelfish_db” su Babelfish per Aurora PostgreSQL impedisce ad Aurora di eseguire correttamente il provisioning di Babelfish.
Per creare un cluster con Babelfish in esecuzione con AWS Management Console
-
Apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
e scegli Crea database. 
-
Per Scegli un metodo di creazione del database, procedi in uno dei seguenti modi:
-
Per specificare opzioni dettagliate del motore, scegli Standard create (Creazione standard).
-
Per utilizzare opzioni preconfigurate che supportano le best practice per un cluster Aurora, scegli Creazione semplice.
-
-
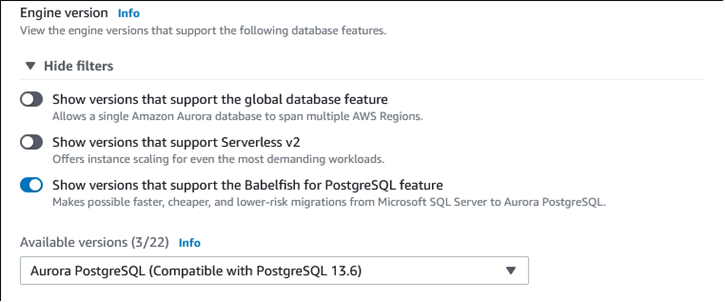
Per Tipo di motore scegli Aurora (compatibile con PostgreSQL).
-
Per Versioni disponibili, scegli una versione Aurora PostgreSQL. Per ottenere le funzionalità di Babelfish più recenti, scegli la versione principale di Aurora PostgreSQL più alta. Babelfish è supportato su tutte le versioni supportate di Aurora PostgreSQL, 13 e successive.
-
In Templates (Modelli), seleziona il modello che corrisponde al proprio caso d'uso.
-
Per Identificatore cluster di database, inserisci un nome che puoi facilmente trovare in seguito nell'elenco dei cluster di database.
-
Per Master username (Nome utente master), immetti un nome utente amministratore. Il valore predefinito per Aurora PostgreSQL è
postgres. Puoi accettare il valore predefinito o scegliere un nome diverso. Ad esempio, per seguire la convenzione di denominazione utilizzata nei database SQL Server, puoi immetteresa(amministratore di sistema) per Master username (Nome utente Master).Se non crei un utente chiamato
sain questo momento, puoi crearne uno in un secondo momento con la tua scelta del cliente. Dopo aver creato l'utente, utilizza il comandoALTER SERVER ROLEper aggiungerlo al gruppo (ruolo)sysadminper il cluster.avvertimento
Il nome utente master deve sempre utilizzare caratteri minuscoli, altrimenti il cluster di database non può connettersi a Babelfish tramite la porta TDS.
-
Per Master password (Password master), crea una password complessa e confermala.
-
Per le opzioni che seguono, fino alla sezione Impostazioni di Babelfish,specifica le impostazioni del cluster di database. Per informazioni su ciascuna impostazione, consulta Impostazioni per cluster di database Aurora.
-
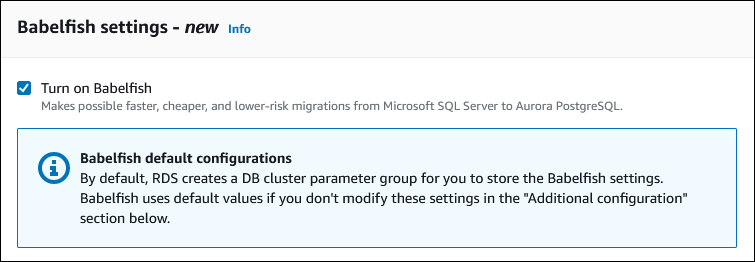
Per rendere disponibile la funzionalità Babelfish, seleziona la casella Turn on Babelfish (Attiva Babelfish).
-
Per Gruppo di parametri del cluster database, procedere in uno dei seguenti modi:
-
Scegliere Crea nuovo per creare un nuovo gruppo di parametri con Babelfish attivato.
-
Scegliere Scegli esistente per utilizzare un gruppo di parametri esistente. Se si utilizza un gruppo esistente, assicurarsi di modificare il gruppo prima di creare il cluster e aggiungere valori per i parametri Babelfish. Per informazioni sull'estensione dei parametri consulta Impostazioni del gruppo di parametri del cluster database per Babelfish.
Se si utilizza un gruppo esistente, specificare il nome del gruppo nella casella che segue.
-
-
Per Database migration mode (Modalità di migrazione del database), scegliere una delle seguenti opzioni:
-
Database singolo per eseguire la migrazione di un singolo database di SQL Server.
In alcuni casi, potresti migrare più database utente insieme, con il tuo obiettivo finale una migrazione completa a Aurora PostgreSQL nativa senza Babelfish. Se le applicazioni finali richiedono schemi consolidati (un singolo schema
dbo), assicurarsi di consolidare innanzitutto i database di SQL Server in un singolo database SQL Server. Quindi effettuare la migrazione a Babelfish usando la modalità Database singolo. -
Database multipli per eseguire la migrazione di più database di SQL Server (provenienti da una singola installazione di SQL Server). La modalità di database multipli non consolida più database che non provengono da una singola installazione di SQL Server. Per ulteriori informazioni sulla migrazione di più database, consulta Utilizzo di Babelfish con un singolo database o più database.
Nota
A partire da Aurora PostgreSQL 16, per impostazione predefinita viene scelta la modalità Database multipli come modalità di migrazione del database.

-
-
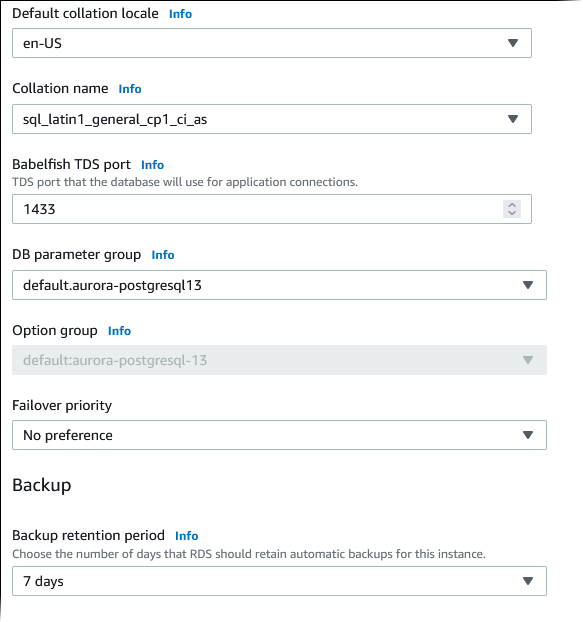
Per Localizzazione raccolta predefinita, immetti le impostazioni internazionali del server. Il valore predefinito è
en-US. Per informazioni dettagliate sulle raccolte consulta Informazioni sulle regole di confronto in Babelfish per Aurora PostgreSQL.. -
Per il campo Collation name (Nome raccolta), inserisci le regole di confronto predefinite. Il valore predefinito è
sql_latin1_general_cp1_ci_as. Per informazioni dettagliate, consulta Informazioni sulle regole di confronto in Babelfish per Aurora PostgreSQL.. -
Per DB parameter group (Gruppo di parametri database), scegli un gruppo di parametri o fai in modo che Aurora crei un nuovo gruppo per te con impostazioni predefinite.
-
Per Failover priority (Priorità failover), seleziona una priorità di failover per l'istanza. Se non specifichi alcun valore, l'impostazione predefinita è
tier-1. Questa priorità determina l'ordine di promozione delle repliche durante il ripristino da un errore dell'istanza primaria. Per ulteriori informazioni, consulta Tolleranza ai guasti di un cluster DB Aurora. -
Per Backup retention period (Tempo di conservazione del backup), scegli l'arco di tempo (da 1 a 35 giorni), nel quale Aurora conserverà le copie di backup del database. Puoi utilizzare le copie di backup per operazioni di ripristino point-in-time (PITR) del database al secondo. Il periodo di conservazione predefinito è 60 giorni.
-
Selezionare Copy tags to snapshots (Copy tag a snapshot) per copiare i tag dell'istanza database in uno snapshot DB quando si crea uno snapshot.
Nota
Quando si ripristina un cluster di database da uno snapshot, non viene ripristinato come cluster di database Babelfish per Aurora PostgreSQL. È necessario attivare i parametri che controllano le preferenze di Babelfish nel gruppo di parametri del cluster di database per abilitare nuovamente Babelfish. Per ulteriori informazioni sui parametri di Babelfish, consulta Impostazioni del gruppo di parametri del cluster database per Babelfish.
-
Scegliere Enable encryption (Abilita crittografia) per attivare la crittografia a riposo (crittografia dello storage Aurora) per questo cluster database.
-
Scegliere Enable Performance Insights (Abilita Performance Insights)per attivare Amazon RDS Performance Insights.
-
Scegliere Enable Enhanced monitoring (Abilita monitoraggio avanzato) per avviare la raccolta di parametri in tempo reale per il sistema operativo su cui viene eseguito il cluster di database.
-
Scegli il log PostgreSQL per pubblicare i file di registro su Amazon Logs. CloudWatch
-
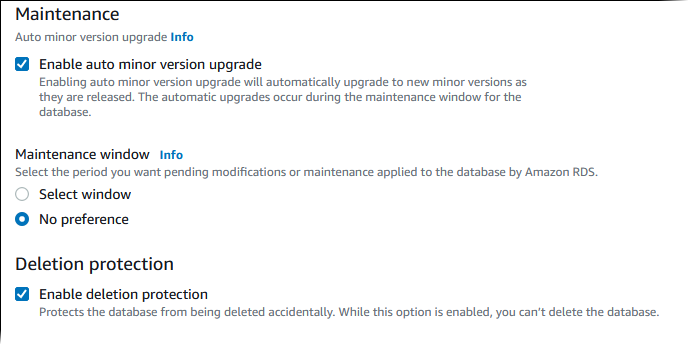
Scegliere Enable auto minor version upgrade (Abilita aggiornamento automatico versione secondaria) per aggiornare automaticamente il cluster Aurora DB quando è disponibile un aggiornamento di versione secondaria.
-
Per Maintenance window (Finestra di manutenzione), eseguire le seguenti operazioni:
-
Per scegliere un orario per fare apportare modifiche o far eseguire la manutenzione da Amazon RDS, scegliere Select window (Seleziona finestra).
-
Per eseguire la manutenzione di Amazon RDS in un momento non programmato, scegliere No preference (Nessuna preferenza).
-
-
Selezionare la casella Enable deletion protection (Abilita protezione da eliminazione) per proteggere il database dall'eliminazione accidentale.
Se si attiva questa funzione, non è possibile eliminare direttamente il database. Al contrario, è necessario modificare il cluster di database e disattivare questa funzione prima di eliminare il database.
-
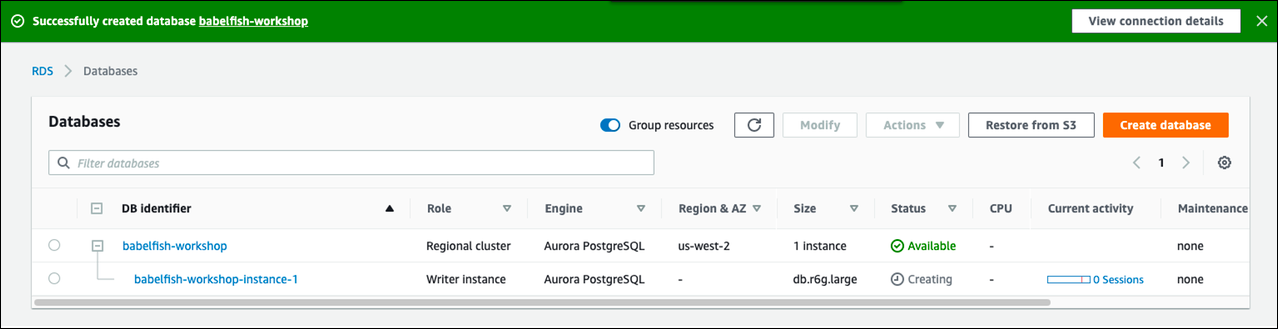
Scegliere Crea database.
Puoi trovare il tuo nuovo database configurato per Babelfish nell'elenco Database. La colonna Status (Stato) visualizza Available (Disponibile) quando la distribuzione è completata.
Quando si crea un Babelfish per Aurora PostgreSQL; utilizzando il AWS CLI, è necessario passare al comando il nome del gruppo di parametri del cluster DB da utilizzare per il cluster. Per ulteriori informazioni, consulta Prerequisiti per i cluster di database.
Prima di poter utilizzare il AWS CLI per creare un cluster Aurora PostgreSQL con Babelfish, procedi come segue:
-
Seleziona l'URL dell'endpoint dall'elenco dei servizi all'indirizzo Endpoint e quote di Amazon Aurora.
-
Creare gruppo di parametri del cluster di database Per ulteriori informazioni sui gruppi di parametri, consultare Gruppi di parametri per Amazon Aurora.
-
Modificare il gruppo di parametri, aggiungendo il parametro che attiva Babelfish.
Per creare un cluster Aurora PostgreSQL DB con Babelfish utilizzando il AWS CLI
Gli esempi che seguono utilizzano il nome utente master predefinito, postgres. Sostituisci in base alle esigenze con il nome utente creato per il cluster database, ad esempio sa o qualsiasi nome utente scelto se non è stato accettato il valore predefinito.
-
Per creare un gruppo di parametri.
Per Linux, macOS o Unix:
aws rds create-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --db-parameter-group-familyaurora-postgresql14\ --description"description"Per Windows:
aws rds create-db-cluster-parameter-group ^ --endpoint-urlendpoint-URL^ --db-cluster-parameter-group-nameparameter-group^ --db-parameter-group-familyaurora-postgresql14^ --description"description" -
Modifica il gruppo di parametri per attivare Babelfish.
Per Linux, macOS o Unix:
aws rds modify-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot"Per Windows:
aws rds modify-db-cluster-parameter-group ^ --endpoint-urlendpoint-url^ --db-cluster-parameter-group-nameparamater-group^ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" -
Identificare il gruppo di sottoreti del database e l'ID del gruppo di sicurezza VPC per il nuovo cluster di database, quindi richiamare il comando create-db-cluster.
Per Linux, macOS o Unix:
aws rds create-db-cluster \ --db-cluster-identifiercluster-name\ --master-usernamepostgres\ --manage-master-user-password \ --engine aurora-postgresql \ --engine-version14.3\ --vpc-security-group-idssecurity-group\ --db-subnet-group-namesubnet-group-name\ --db-cluster-parameter-group-nameparameter-groupPer Windows:
aws rds create-db-cluster ^ --db-cluster-identifiercluster-name^ --master-usernamepostgres^ --manage-master-user-password ^ --engine aurora-postgresql ^ --engine-version14.3^ --vpc-security-group-idssecurity-group^ --db-subnet-group-namesubnet-group^ --db-cluster-parameter-group-nameparameter-groupIn questo esempio è specificata l'opzione
--manage-master-user-passwordper generare la password dell'utente master e gestirla in Secrets Manager. Per ulteriori informazioni, consulta Gestione delle password con Amazon Aurora and AWS Secrets Manager. In alternativa, puoi utilizzare l'opzione--master-passwordper specificare e gestire personalmente la password. -
Crea in maniera esplicita l'istanza primaria del cluster database. Utilizza il nome del cluster creato nella fase 3 per l'argomento
--db-cluster-identifierquando chiami il comando create-db-instance, come illustrato di seguito.Per Linux, macOS o Unix:
aws rds create-db-instance \ --db-instance-identifierinstance-name\ --db-instance-classdb.r6g\ --db-subnet-group-namesubnet-group\ --db-cluster-identifiercluster-name\ --engine aurora-postgresqlPer Windows:
aws rds create-db-instance ^ --db-instance-identifierinstance-name^ --db-instance-classdb.r6g^ --db-subnet-group-namesubnet-group^ --db-cluster-identifiercluster-name^ --engine aurora-postgresql
