Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Deadlock distribuiti in Aurora PostgreSQL Limitless Database
In un gruppo di shard del database, possono verificarsi dei deadlock tra le transazioni distribuite tra router e shard diversi. Ad esempio, vengono eseguite due transazioni distribuite simultanee che si estendono su due shard, come illustrato nella figura seguente.
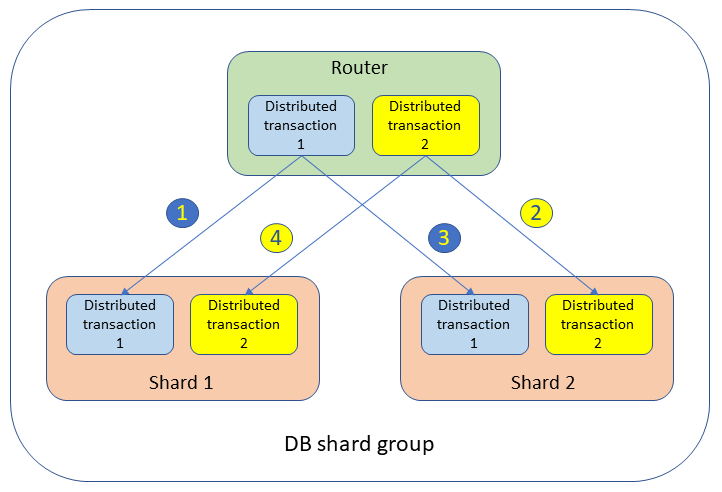
Le transazioni bloccano le tabelle e creano eventi di attesa nei due shard come segue:
-
Transazione distribuita 1:
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';Questo contiene un blocco sullo shard 1.
-
Transazione distribuita 2:
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';Questo contiene un blocco sullo shard 2.
-
Transazione distribuita 1:
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';La transazione distribuita 1 è in attesa sullo shard 2.
-
Transazione distribuita 2:
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';La transazione distribuita 2 è in attesa sullo shard 1.
In questo scenario, né lo shard 1 né lo shard 2 vedono il problema: la transazione 1 è in attesa della transazione 2 sullo shard 2 e la transazione 2 è in attesa della transazione 1 sullo shard 1. Da un punto di vista globale, la transazione 1 è in attesa della transazione 2 e la transazione 2 è in attesa della transazione 1. Questa situazione in cui due transazioni su due shard diversi sono in attesa l’una dell’altra viene chiamata deadlock distribuito.
Aurora PostgreSQL Limitless Database è in grado di rilevare e risolvere automaticamente i deadlock distribuiti. Un router del gruppo di shard del database riceve una notifica quando una transazione attende troppo a lungo per acquisire una risorsa. Il router che riceve la notifica inizia a raccogliere le informazioni necessarie da tutti i router e gli shard all’interno del gruppo di shard del database. Il router procede quindi a terminare le transazioni che partecipano a un deadlock distribuito, finché le altre transazioni nel gruppo di shard del database non possono procedere senza essere bloccate l’una dall’altra.
Viene visualizzato il seguente errore quando la transazione fa parte di un deadlock distribuito e viene quindi interrotta dal router:
ERROR: aborting transaction participating in a distributed deadlock
Il parametro del cluster di database rds_aurora.limitless_distributed_deadlock_timeout imposta il tempo di attesa di ogni transazione su una risorsa prima di notificare al router di verificare la presenza di un deadlock distribuito. È possibile aumentare il valore del parametro se il carico di lavoro è meno soggetto a situazioni di deadlock. Il valore predefinito è 1000 millisecondi (1 secondo).
Il ciclo di deadlock distribuito viene pubblicato nei log di PostgreSQL quando viene rilevato e risolto un deadlock tra nodi. Le informazioni su ogni processo che fa parte del deadlock includono quanto segue:
-
Nodo coordinatore che ha avviato la transazione
-
ID della transazione virtuale (xid) della transazione sul nodo coordinatore, nel formato
backend_id/backend_local_xid -
L’ID della sessione distribuita della transazione
