Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Multi-AZ Implementazioni di cluster DB per Amazon RDS
Una distribuzione di cluster Multi-AZ DB è una modalità di distribuzione semisincrona e ad alta disponibilità di Amazon RDS con due istanze DB di replica leggibili. Un cluster Multi-AZ DB ha un'istanza DB writer e due istanze DB di lettura in tre zone di disponibilità separate all'interno della stessa. Regione AWS Multi-AZ I cluster DB offrono un'elevata disponibilità, una maggiore capacità per i carichi di lavoro di lettura e una latenza di scrittura inferiore rispetto alle Multi-AZ implementazioni di istanze DB.
È possibile importare dati da un database locale a un cluster Multi-AZ DB seguendo le istruzioni riportate in. Importazione dei dati in un database Amazon RDS per MySQL con tempo di inattività ridotto
È possibile acquistare istanze DB riservate per un cluster Multi-AZ DB. Per ulteriori informazioni, consulta Istanze DB riservate per un cluster Multi-AZ DB.
Il supporto varia a seconda delle versioni specifiche di ciascun motore di database e a seconda delle Regioni AWS. Per ulteriori informazioni sulla disponibilità della versione e della regione di Amazon RDS con cluster Multi-AZ DB, consulta. Regioni e motori DB supportati per cluster Multi-AZ DB in Amazon RDS
Argomenti
Disponibilità delle classi di istanze per i cluster DB Multi-AZ
Connessione automatica di una risorsa di AWS elaborazione e di un cluster Multi-AZ DB per Amazon RDS
Aggiornamento della versione del motore di un cluster Multi-AZ DB per Amazon RDS
Riavvio di un cluster Multi-AZ DB e di lettura di istanze DB per Amazon RDS
Configurazione della replica logica PostgreSQL con cluster DB per Amazon RDS Multi-AZ
Utilizzo delle repliche di lettura del cluster Multi-AZ DB per Amazon RDS
Configurazione della replica esterna da cluster Multi-AZ DB per Amazon RDS
Importante
Multi-AZ I cluster DB non sono uguali ai cluster Aurora DB. Per ulteriori informazioni sull'utilizzo di cluster di database Aurora, consulta la Guida per l'utente di Amazon Aurora.
Disponibilità delle classi di istanze per i cluster DB Multi-AZ
Multi-AZ Le distribuzioni di cluster DB sono supportate per le seguenti classi di istanze DB: db.c6gddb.m5d,db.m6gd,,db.m6id,db.m6idn,db.m8gd,db.r5d,db.r6gd, db.r6iddb.r6idn, db.r8gd e. db.x2iedn
Nota
Le classi di istanza c6gd sono le uniche che supportano le dimensioni dell’istanza medium.
Per maggiori informazioni sulle classi di istanza database, consulta Classi di istanze database.
Multi-AZ Architettura del cluster DB
Con un cluster Multi-AZ DB, Amazon RDS replica i dati dall'istanza Writer DB su entrambe le istanze DB Reader utilizzando le funzionalità di replica native del motore DB. Quando viene apportata una modifica all'istanza database di scrittore, viene inviata a ciascuna istanza database di lettura.
Multi-AZ Le implementazioni di cluster DB utilizzano la replica semisincrona, che richiede il riconoscimento da parte di almeno un'istanza DB di lettura per eseguire una modifica. Non viene richiesta la conferma dell'avvenuta esecuzione o dell'avvenuto commit degli eventi in tutte le repliche.
Le istanze database di lettore fungono da target di failover automatici e servono anche il traffico di lettura per aumentare il throughput di lettura delle applicazioni. Se si verifica un'interruzione sull'istanza database di scrittura, RDS gestisce il failover su una delle istanze database di lettura. RDS esegue questa operazione in base a quale istanza database di lettura ha il ritardo di replica più recente.
Il Multi-AZ diagramma seguente mostra un cluster DB.
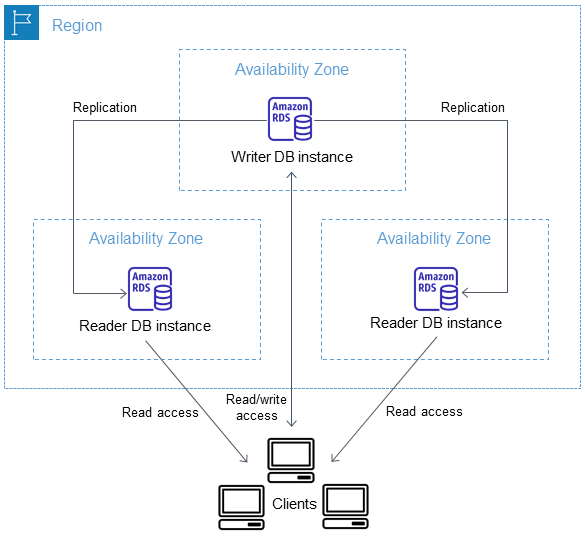
Multi-AZ I cluster DB in genere hanno una latenza di scrittura inferiore rispetto alle implementazioni di istanze Multi-AZ DB. Consentono inoltre l'esecuzione di carichi di lavoro di sola lettura su istanze database di lettura. La console RDS mostra la zona di disponibilità dell'istanza database di scrittore e le zone di disponibilità delle istanze database del lettore. È possibile utilizzare anche il comando CLI describe-db-clusters o l’operazione API DescribeDBClusters per trovare queste informazioni.
Importante
Per evitare errori di replica nei cluster Multi-AZ DB RDS for MySQL, consigliamo vivamente che tutte le tabelle abbiano una chiave primaria.
Gruppi di parametri per i cluster DB Multi-AZ
In un cluster Multi-AZ DB, un gruppo di parametri del cluster DB funge da contenitore per i valori di configurazione del motore che vengono applicati a ogni istanza DB del cluster Multi-AZ DB.
In un cluster Multi-AZ DB, un gruppo di parametri DB è impostato sul gruppo di parametri DB predefinito per il motore DB e la versione del motore DB. Le impostazioni del gruppo di parametri del cluster di database vengono utilizzate per tutte le istanze database nel cluster.
Per informazioni sui gruppi di parametri, consultare Utilizzo dei gruppi di parametri del cluster DB per i cluster Multi-AZ DB.
Proxy RDS con cluster Multi-AZ DB
Puoi usare Amazon RDS Proxy per creare un proxy per i tuoi cluster Multi-AZ DB. che consente alle applicazioni di creare pool delle connessioni di database e di condividerle per migliorare la capacità di dimensionamento. Ogni proxy esegue il multiplexing delle connessioni, noto anche come riutilizzo della connessione. Con il multiplexing, Server proxy per RDS esegue tutte le operazioni per una transazione utilizzando una connessione al database sottostante, RDS Proxy può anche ridurre i tempi di inattività per un aggiornamento di versione minore di un cluster Multi-AZ DB a un secondo o meno. Per ulteriori informazioni sui vantaggi di Server proxy per RDS, consulta Server proxy per Amazon RDS.
Per configurare un proxy per un cluster Multi-AZ DB, scegli Crea un proxy RDS durante la creazione del cluster. Per istruzioni su come creare e gestire gli endpoint di Server proxy per RDS, consulta Utilizzo degli endpoint Amazon RDS Proxy.
Replica lag e cluster DB Multi-AZ
Replica lag (Ritardo di replica) è la differenza di tempo tra l'ultima transazione sull'istanza database di scrittura e l'ultima transazione applicata su un'istanza database di lettura. La CloudWatch metrica Amazon ReplicaLag rappresenta questa differenza di fuso orario. Per ulteriori informazioni sulle CloudWatch metriche, consulta. Monitoraggio Amazon RDS metriche con Amazon CloudWatch
Sebbene i cluster Multi-AZ DB consentano prestazioni di scrittura elevate, possono comunque verificarsi ritardi nella replica a causa della natura della replica basata sul motore. Poiché qualsiasi failover deve prima risolvere il ritardo di replica prima di promuovere una nuova istanza database di scrittura, il monitoraggio e la gestione di questo ritardo di replica devono essere presi in considerazione.
Per i cluster DB RDS for Multi-AZ MySQL, il tempo di failover dipende dal ritardo di replica di entrambe le istanze DB Reader rimanenti. Entrambe le istanze database di lettura devono applicare transazioni non applicate prima che una di esse venga promossa a nuova istanza database di scrittura.
Per i cluster DB RDS per Multi-AZ PostgreSQL, il tempo di failover dipende dal ritardo di replica più basso delle due istanze DB Reader rimanenti. L’istanza database di lettura con il ritardo di replica minore deve applicare transazioni non applicate prima di essere promossa a nuova istanza database di scrittura.
Per un tutorial che mostra come creare un CloudWatch allarme quando il ritardo della replica supera un determinato periodo di tempo, vedi. Tutorial: creazione di un CloudWatch allarme Amazon per il ritardo di replica del cluster Multi-AZ DB per Amazon RDS
Cause comuni del ritardo di replica
In generale, il ritardo di replica si verifica quando il carico di lavoro in scrittura è troppo alto per consentire alle istanze database di lettura di applicare le transazioni in modo efficiente. Diversi carichi di lavoro possono subire ritardi di replica temporanei o continui. Di seguito sono riportati alcuni esempi di cause comuni:
-
Alta concorrenza di scrittura o aggiornamento in batch pesante sull'istanza database di scrittura, che causano il ritardo del processo di applicazione sulle istanze database di lettura.
-
Carico di lavoro in lettura pesante che utilizza risorse su una o più istanze database di lettura. L'esecuzione di query lente o di grandi dimensioni può influire sul processo di applicazione e può causare un ritardo di replica.
-
Le transazioni che modificano grandi quantità di dati o istruzioni DDL possono talvolta causare un aumento temporaneo del ritardo di replica perché il database deve mantenere l'ordine di commit.
Mitigazione del ritardo di replica
Per i cluster Multi-AZ DB per RDS for MySQL e RDS per PostgreSQL, puoi mitigare il ritardo nella replica riducendo il carico sull'istanza DB di writer. È inoltre possibile utilizzare il controllo di flusso per ridurre il ritardo di replica. Flow control (Controllo di flusso) funziona limitando le scritture sull'istanza database di scrittura, che garantisce che il ritardo di replica non continui a crescere senza limiti. La limitazione della scrittura viene eseguita aggiungendo un ritardo alla fine di una transazione, che riduce la velocità effettiva di scrittura sull'istanza database di scrittura. Sebbene il controllo di flusso non garantisca l'eliminazione del ritardo, può contribuire a ridurre il ritardo complessivo in molti carichi di lavoro. Le seguenti sezioni forniscono informazioni sull'utilizzo del controllo di flusso con RDS for MySQL e RDS for PostgreSQL.
Mitigazione del ritardo di replica con il controllo di flusso per RDS for MySQL
Quando si utilizzano i cluster RDS for Multi-AZ MySQL DB, il controllo del flusso è attivato per impostazione predefinita utilizzando il parametro dynamic. rpl_semi_sync_master_target_apply_lag Questo parametro specifica il limite superiore desiderato per il ritardo di replica. Man mano che il ritardo di replica si avvicina a questo limite configurato, il controllo di flusso limita le transazioni di scrittura sull’istanza database di scrittura per tentare di mantenere il ritardo di replica al di sotto del valore specificato. In alcuni casi, il ritardo di replica può superare il limite specificato. Per impostazione predefinita, questo parametro è impostato su 120 secondi. Per disattivare il controllo di flusso, è necessario impostare questo parametro sul valore massimo di 86.400 secondi (un giorno).
Per visualizzare il ritardo corrente inserito dal controllo di flusso, mostra il parametro Rpl_semi_sync_master_flow_control_current_delay eseguendo la seguente query.
SHOW GLOBAL STATUS like '%flow_control%';
L'aspetto dell'output sarà simile al seguente.
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)Nota
Il ritardoviene visualizzato in microsecondi.
Quando Performance Insights è attivato per un cluster RDS for Multi-AZ MySQL DB, puoi monitorare l'evento di attesa corrispondente a un'istruzione SQL che indica che le query sono state ritardate da un controllo di flusso. Quando un ritardo è stato introdotto da un controllo di flusso, è possibile visualizzare l'evento di attesa /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond corrispondente all'istruzione SQL nel pannello di controllo di Performance Insights. Per visualizzare questi parametri, lo schema delle prestazioni deve essere attivato. Per informazioni su Performance Insights, consulta Monitoraggio del carico del DB con Performance Insights su Amazon RDS.
Mitigazione del ritardo di replica con il controllo di flusso per RDS for PostgreSQL
Quando si utilizzano cluster RDS per Multi-AZ PostgreSQL DB, il controllo del flusso viene distribuito come estensione. Attiva un dipendente in background per tutte le istanze database nel cluster di database. Per impostazione predefinita, i dipendenti in background sulle istanze database di lettura comunicano il ritardo di replica corrente con il dipendente in background sull'istanza database di scrittura. Se il ritardo supera i due minuti su qualsiasi istanza database di lettura, il dipendente in background sull'istanza database di scrittura aggiunge un ritardo alla fine di una transazione. Per controllare la soglia di ritardo, utilizza il parametro flow_control.target_standby_apply_lag.
Quando un controllo di flusso limita un processo PostgreSQL, l'evento di attesa Extension in pg_stat_activity e Performance Insights lo indica. La funzione get_flow_control_stats visualizza i dettagli sull'entità del ritardo attualmente aggiunto.
Il controllo di flusso può beneficiare della maggior parte dei carichi di lavoro OLTP (Online Transaction Processing, elaborazione di transazioni online) che hanno transazioni brevi ma altamente simultanee. Se il ritardo è causato da transazioni di lunga durata, come le operazioni in batch, il controllo di flusso non fornisce un vantaggio altrettanto forte.
È possibile disattivare il controllo di flusso rimuovendo l'estensione da shared_preload_libraries e riavviare l'istanza database.
Multi-AZ Istantanee del cluster DB
Amazon RDS crea e salva backup automatici del cluster Multi-AZ DB durante la finestra di backup configurata. RDS crea uno snapshot dei volumi di archiviazione del cluster di database eseguendo il backup dell’intero cluster anziché delle singole istanze.
Puoi anche eseguire backup manuali del tuo Multi-AZ cluster DB. Per i backup a lungo termine, si consiglia di esportare i dati degli snapshot in Amazon S3. Per ulteriori informazioni, consulta Creazione di uno snapshot del cluster Multi-AZ DB per Amazon RDS.
È possibile ripristinare un cluster Multi-AZ DB in un momento specifico, creando un nuovo cluster di Multi-AZ DB. Per istruzioni, consulta Ripristino di un cluster Multi-AZ DB a un'ora specificata.
In alternativa, è possibile ripristinare un'istantanea del cluster Multi-AZ DB in una Single-AZ distribuzione o in un'istanza Multi-AZ DB. Per istruzioni, consulta Ripristino da un'istantanea del cluster Multi-AZ DB a un'istanza DB.
