Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Filtraggio dei dati per Amazon RDS Integrazioni Zero-ETL
Le integrazioni Zero-ETL di Amazon RDS supportano il filtro dei dati, che consente di controllare quali dati vengono replicati dal database Amazon RDS di origine al data warehouse di destinazione. Invece di replicare l’intero database, puoi applicare uno o più filtri per includere o escludere selettivamente delle tabelle specifiche. Ciò consente di ottimizzare le prestazioni di archiviazione e query assicurando che vengano trasferiti solo i dati pertinenti. Attualmente, il filtro è limitato a livello di database e tabella. Il filtro a livello di colonna e riga non è supportato.
Il filtro dei dati può essere utile se desideri:
-
Unire determinate tabelle da due o più database di origine diversi e non hai bisogno dei dati completi da ciascun database.
-
Risparmiare sui costi eseguendo analisi che utilizzano solo un sottoinsieme di tabelle anziché un intero parco di database.
-
Filtrare le informazioni sensibili, come numeri di telefono, indirizzi o dettagli delle carte di credito, da determinate tabelle.
Puoi aggiungere filtri di dati a un'integrazione zero-ETL utilizzando AWS Management Console, the AWS Command Line Interface (AWS CLI) o l'API Amazon RDS.
Se l’integrazione ha come destinazione un cluster con provisioning, per utilizzare il filtro dei dati è necessario che il cluster utilizzi la patch 180 o una versione successiva.
Argomenti
Formato di un filtro dei dati
Puoi definire diversi filtri per una singola integrazione. Ogni filtro include o esclude tutte le tabelle di database esistenti e future che corrispondono a uno dei modelli nell’espressione di filtro. Le integrazioni Zero-ETL di Amazon RDS utilizzano la sintassi del filtro Maxwell
Ogni filtro contiene i seguenti elementi:
| Elemento | Description |
|---|---|
| Tipo di filtro |
Un tipo di filtro |
| Espressione filtro |
Un elenco di modelli separato da virgole. Le espressioni devono utilizzare la sintassi del filtro Maxwell |
| Pattern |
Un modello di filtro nel formato NotaPer RDS per MySQL, le espressioni regolari sono supportate sia nel nome del database sia in quello della tabella. Per RDS per PostgreSQL, le espressioni regolari sono supportate solo nel nome dello schema e della tabella, non in quello del database. Non è possibile includere filtri o elenco elementi non consentiti a livello di colonna. Una singola integrazione può avere un massimo di 99 modelli totali. Nella console, è possibile inserire modelli all’interno di una singola espressione di filtro o distribuirli tra diverse espressioni. Un singolo modello non può superare i 256 caratteri. |
Importante
Se selezioni un database di origine RDS per PostgreSQL, è necessario specificare almeno un modello di filtro dei dati. Come minimo, il modello deve includere un singolo database (database-name.*.*
L’immagine seguente mostra la struttura dei filtri dei dati di RDS per MySQL nella console:
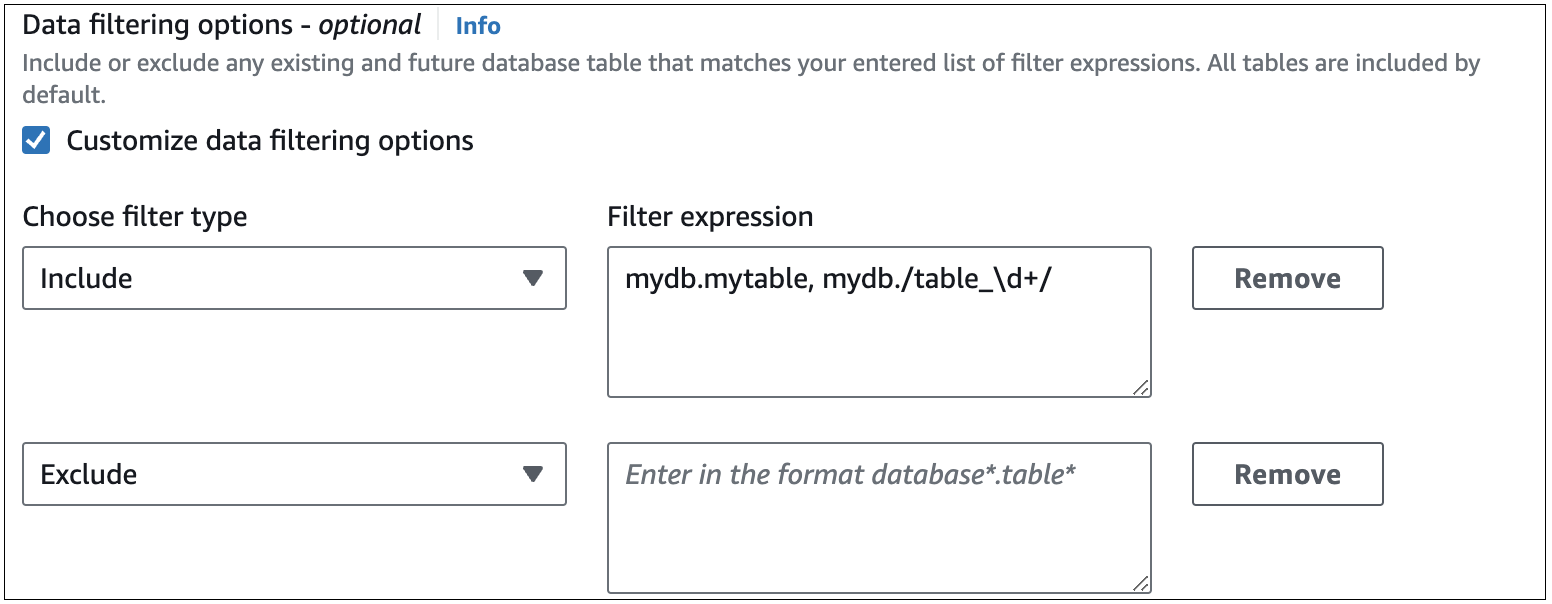
Importante
Non includere informazioni riservate, sensibili o di identificazione personale nei modelli di filtro.
Filtri di dati in AWS CLI
Quando si utilizza AWS CLI per aggiungere un filtro dati, la sintassi è leggermente diversa da quella della console. È necessario assegnare un tipo di filtro (Include o Exclude) a ciascun modello singolarmente, in modo da non poter raggruppare diversi modelli in un unico tipo di filtro.
Ad esempio, nella console puoi raggruppare i seguenti modelli separati da virgola in un’unica istruzione Include:
RDS per MySQL
mydb.mytable,mydb./table_\d+/
RDS per PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
Tuttavia, quando si utilizza il AWS CLI, lo stesso filtro dati deve avere il seguente formato:
RDS per MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS per PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Logica dei filtri
Se non specifichi alcun filtro dei dati nell’integrazione, Amazon RDS presuppone un filtro predefinito include:*.*, che replica tutte le tabelle nel data warehouse di destinazione. Tuttavia, se aggiungi almeno un filtro, la logica predefinita passa a exclude:*.*, che esclude tutte le tabelle per impostazione predefinita. Ciò consente di definire in modo esplicito quali database e tabelle includere nella replica.
Ad esempio, se definisci il filtro seguente:
'include: db.table1, include: db.table2'
Amazon RDS valuta il filtro come indicato di seguito:
'exclude:*.*, include: db.table1, include: db.table2'
Pertanto, Amazon RDS esegue la replica di table1 e table2 dal database denominato db al data warehouse di destinazione.
Precedenza dei filtri
Amazon RDS valuta i filtri dei dati nell’ordine specificato. In AWS Management Console, elabora le espressioni di filtro da sinistra a destra e dall'alto verso il basso. Un secondo filtro o un modello individuale che segue il primo può sovrascriverlo.
Ad esempio, se il primo filtro è Include books.stephenking, include solo la tabella stephenking del database books. Tuttavia, se aggiungi un secondo filtro Exclude books.*, questo sostituisce il primo. Ciò impedisce che le tabelle dell’indice books vengano replicate nel data warehouse di destinazione.
Quando si specifica almeno un filtro, la logica parte presupponendo exclude:*.* per impostazione predefinita, che esclude automaticamente tutte le tabelle dalla replica. Come best practice, definisci i filtri dal più ampio al più specifico. Inizia con una o più istruzioni Include per specificare i dati da replicare, quindi aggiungi i filtri Exclude per rimuovere selettivamente determinate tabelle.
Lo stesso principio si applica ai filtri definiti utilizzando AWS CLI. Amazon RDS valuta questi modelli di filtro nell’ordine in cui li specifichi, quindi un modello potrebbe sovrascrivere quello specificato in precedenza.
Esempi di RDS per MySQL
Gli esempi seguenti mostrano come funziona il filtro dei dati per le integrazioni Zero-ETL di RDS per MySQL:
-
Includi tutti i database e tutte le tabelle:
'include: *.*' -
Includi tutte le tabelle all’interno del database
books:'include: books.*' -
Escludi tutte le tabelle denominate
mystery:'include: *.*, exclude: *.mystery' -
Includi due tabelle specifiche all’interno del database
books:'include: books.stephen_king, include: books.carolyn_keene' -
Includi tutte le tabelle del database
books, ad eccezione di quelle contenenti la sottostringamystery:'include: books.*, exclude: books./.*mystery.*/' -
Includi tutte le tabelle del database
books, ad eccezione di quelle che iniziano conmystery:'include: books.*, exclude: books./mystery.*/' -
Includi tutte le tabelle del database
books, ad eccezione di quelle che terminano conmystery:'include: books.*, exclude: books./.*mystery/' -
Includi tutte le tabelle del database
booksche iniziano contable_, ad eccezione di quella denominatatable_stephen_king. Ad esempio,table_moviesotable_booksverrebbe replicato, matable_stephen_kingnon verrebbe replicato.'include: books./table_.*/, exclude: books.table_stephen_king'
RDS per PostgreSQL esempi
Gli esempi seguenti mostrano come funziona il filtro dei dati per le integrazioni Zero-ETL di RDS per PostgreSQL:
-
Includi tutte le tabelle all’interno del database
books:'include: books.*.*' -
Escludi tutte le tabelle denominate
mysterynel databasebooks:'include: books.*.*, exclude: books.*.mystery' -
Includi una tabella all’interno del database
booksnello schemamysterye una tabella nel databaseemployeenello schemafinance:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Includi tutte le tabelle del database
bookse dello schemascience_fiction, ad eccezione di quelle contenenti la sottostringaking:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Includi tutte le tabelle del database
books, ad eccezione di quelle con un nome di schema che inizia consci:'include: books.*.*, exclude: books./sci.*/.*' -
Includi tutte le tabelle del database
books, ad eccezione di quelle nello schemamysteryche termina conking:'include: books.*.*, exclude: books.mystery./.*king/' -
Includi tutte le tabelle del database
booksche iniziano contable_, ad eccezione di quella denominatatable_stephen_king. Ad esempio,table_moviesnello schemafictionetable_booksnello schemamysteryvengono replicati, matable_stephen_kingnon verrà replicato in nessuno dei due schemi:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Esempi di RDS per Oracle
Gli esempi seguenti mostrano come funziona il filtro dei dati per le integrazioni Zero-ETL di RDS per Oracle:
-
Includi tutte le tabelle all’interno del database books:
'include: books.*.*' -
Escludi tutte le tabelle denominate mystery nel database books:
'include: books.*.*, exclude: books.*.mystery' -
Includi una tabella all’interno del database books nello schema mystery e una tabella nel database employee nello schema finance:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Includi tutte le tabelle dello schema mystery nel database books:
'include: books.mystery.*'
Considerazioni sulla distinzione tra lettere maiuscole e minuscole
Oracle Database e Amazon Redshift gestiscono le lettere maiuscole e minuscole del nome oggetto in modo diverso. Ciò influisce sia sulla configurazione del filtro dei dati sia sulle query di destinazione. Tenere presente quanto segue:
-
Oracle Database memorizza i nomi di database, schemi e oggetti con le lettere maiuscole, a meno che non vengano esplicitamente inseriti tra virgolette nell’istruzione
CREATE. Ad esempio, se si creamytable(senza virgolette), il dizionario dei dati Oracle memorizza il nome della tabella comeMYTABLE. Se metti il nome dell’oggetto tra virgolette, il dizionario dei dati mantiene le lettere minuscole. -
Zero-ETL i filtri di dati fanno distinzione tra maiuscole e minuscole e devono corrispondere esattamente alle maiuscole e minuscole dei nomi degli oggetti così come appaiono nel dizionario dei dati Oracle.
-
Le query di Amazon Redshift utilizzano per impostazione predefinita i nomi di oggetti in minuscolo, a meno che non vengano esplicitamente inseriti tra virgolette. Ad esempio, una query di
MYTABLE(senza virgolette) cercamytable.
Tieni presente le differenze tra maiuscole e minuscole quando crei il filtro Amazon Redshift ed esegui query sui dati.
Creazione di un’integrazione con lettere maiuscole
Quando crei una tabella senza specificare il nome tra virgolette doppie, il database Oracle memorizza il nome in lettere maiuscole nel dizionario dei dati. Ad esempio, puoi creare MYTABLE utilizzando una delle istruzioni SQL elencate di seguito.
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Poiché non hai citato il nome della tabella nelle istruzioni precedenti, il database Oracle memorizza il nome dell’oggetto in lettere maiuscole, ossia MYTABLE.
Per replicare questa tabella su Amazon Redshift, è necessario specificare il nome in lettere maiuscole nel filtro dei dati del comando create-integration. Il nome del Zero-ETL filtro e il nome del dizionario dei dati Oracle devono corrispondere.
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
Per impostazione predefinita, Amazon Redshift archivia i dati in lettere minuscole. Per eseguire una query MYTABLE nel database replicato in Amazon Redshift, è necessario inserire tra virgolette il nome MYTABLE in lettere maiuscole in modo che corrisponda al nome con lettere maiuscole nel dizionario dei dati Oracle.
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
Le query elencate di seguito non utilizzano il meccanismo di inserimento tra virgolette. Tutte restituiscono un errore perché cercano una tabella Amazon Redshift denominata mytable, che utilizza il nome minuscolo per impostazione predefinita, ma la tabella è denominata MYTABLE nel dizionario dei dati Oracle.
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
Le seguenti query utilizzano il meccanismo di inserimento tra virgolette per specificare un nome con formato misto, ossia con lettere maiuscole e minuscole. Tutte le query restituiscono un errore perché cercano una tabella Amazon Redshift che non è denominata MYTABLE.
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
Creazione di un’integrazione con lettere minuscole
Nel seguente esempio alternativo, si utilizzano le virgolette doppie per memorizzare il nome della tabella in lettere minuscole nel dizionario dei dati Oracle. Crei mytable come indicato di seguito.
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Il database Oracle memorizza il nome della tabella mytable con lettere minuscole. Per replicare questa tabella su Amazon Redshift, devi specificare il mytable nome in minuscolo nel filtro dei dati. Zero-ETL
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Quando esegui una query su questa tabella nel database replicato in Amazon Redshift, puoi specificare il nome mytable in lettere minuscole. La query ha esito positivo perché cerca una tabella denominata mytable, che è il nome della tabella nel dizionario dei dati Oracle.
SELECT * FROM targetdb1."REINVENT".mytable;
Poiché Amazon Redshift utilizza per impostazione predefinita i nomi degli oggetti in lettere minuscole, anche le seguenti query riescono a trovare mytable.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
Le query indicate di seguito utilizzano il meccanismo di inserimento tra virgolette per il nome dell’oggetto. Tutte restituiscono un errore perché cercano una tabella Amazon Redshift il cui nome è diverso da mytable.
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
Creazione di una tabella con un’integrazione tra lettere maiuscole e minuscole
Nell’esempio seguente, si utilizzano le virgolette doppie per memorizzare il nome della tabella in lettere minuscole nel dizionario dei dati Oracle. Crei MyTable come indicato di seguito.
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Il database Oracle memorizza questo nome di tabella come MyTable con formato misto di lettere maiuscole e minuscole. Per replicare questa tabella su Amazon Redshift, è necessario specificare il nome con formato misto di lettere maiuscole e minuscole nel filtro dei dati.
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Quando esegui una query su questa tabella nel database replicato in Amazon Redshift, è necessario specificare il nome con formato misto di lettere maiuscole e minuscole MyTable citando il nome dell’oggetto.
SELECT * FROM targetdb1."REINVENT"."MyTable";
Poiché Amazon Redshift utilizza per impostazione predefinita i nomi degli oggetti con lettere minuscole, le seguenti query non trovano l’oggetto perché cercano il nome mytable con lettere minuscole.
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
Nota
Non è possibile utilizzare espressioni regolari nel valore del filtro per il nome di database, schemi o tabelle nelle integrazioni RDS per Oracle.
Aggiunta di filtri dei dati a un’integrazione
Puoi configurare il filtraggio dei dati utilizzando AWS Management Console l'API AWS CLI Amazon RDS o la.
Importante
Se aggiungi un filtro dopo aver creato un’integrazione, Amazon RDS lo considera come se fosse sempre esistito. Rimuove tutti i dati nel data warehouse di destinazione che non corrispondono ai nuovi criteri di filtro e risincronizza tutte le tabelle interessate.
Per aggiungere i filtri dei dati a un’integrazione Zero-ETL
Accedi a AWS Management Console e apri la console Amazon RDS all'indirizzo https://console.aws.amazon.com/rds/
. -
Nel riquadro di navigazione, scegli Zero-ETL integrazioni. Seleziona l’integrazione a cui desideri aggiungere i filtri dei dati, quindi scegli Modifica.
-
In Origine, aggiungi una o più istruzioni
IncludeeExclude.La seguente immagina mostra un esempio di filtri dei dati per un’integrazione MySQL:
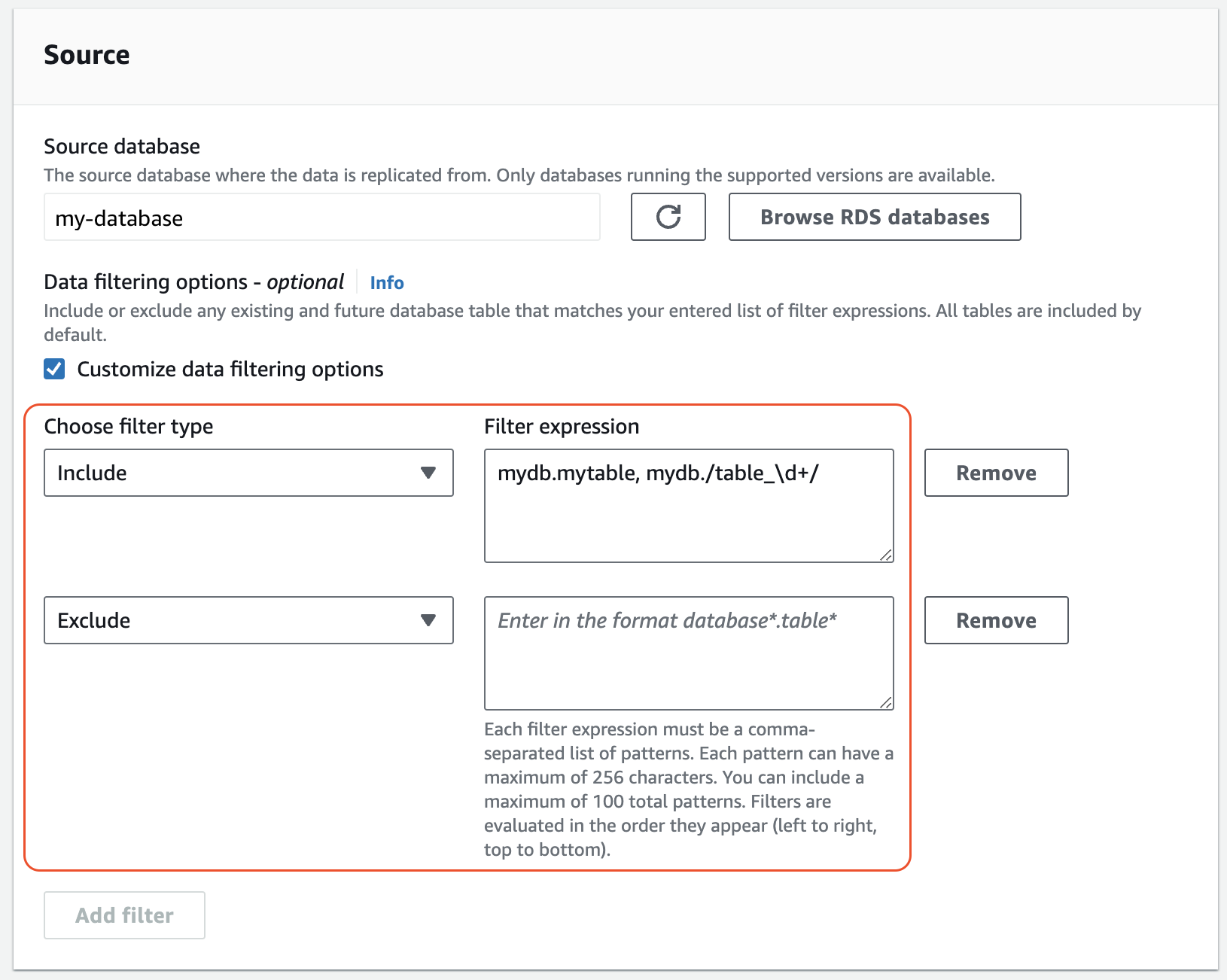
-
Una volta completate le modifiche, scegli Continua, quindi Salva modifiche.
Per aggiungere filtri di dati a un'integrazione zero-ETL utilizzando, chiamate il comando modify-integration. AWS CLI--data-filter con un elenco separato da virgola di filtri Maxwell Include e Exclude.
Esempio
Nell’esempio seguente si aggiungono modelli di filtro a my-integration.
Per Linux, macOS o Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Per Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Per modificare un'integrazione zero-ETL utilizzando l'API RDS, chiama l'operazione. ModifyIntegration Specifica l’identificatore di integrazione e fornisci un elenco separato da virgola di modelli di filtro.
Rimozione di filtri dei dati da un’integrazione
Quando rimuovi un filtro dei dati da un’integrazione, Amazon RDS rivaluta i filtri rimanenti come se il filtro rimosso non fosse mai esistito. Successivamente, replica tutti i dati precedentemente esclusi che ora soddisfano i criteri nel data warehouse di destinazione. Ciò attiva una risincronizzazione di tutte le tabelle interessate.
