Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un rapporto di valutazione multiserver in AWS Schema Conversion Tool
Per determinare la migliore direzione di destinazione per l'intero ambiente, create un rapporto di valutazione multiserver.
Un rapporto di valutazione multiserver valuta più server in base all'input fornito per ogni definizione dello schema che desideri valutare. La definizione dello schema contiene i parametri di connessione al server di database e il nome completo di ogni schema. Dopo aver valutato ogni schema, AWS SCT produce un rapporto di valutazione riepilogativo e aggregato per la migrazione del database tra più server. Questo rapporto mostra la complessità stimata per ogni possibile obiettivo di migrazione.
È possibile utilizzarlo AWS SCT per creare un rapporto di valutazione multiserver per i seguenti database di origine e destinazione.
| Database di origine | Database di destinazione |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Database SQL di Azure |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Analisi di Azure Synapse |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 per z/OS |
Edizione compatibile con Amazon Aurora MySQL (Aurora MySQL), edizione compatibile con Amazon Aurora PostgreSQL (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish per Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Esecuzione di una valutazione multiserver
Utilizzare la procedura seguente per eseguire una valutazione multiserver con. AWS SCT Non è necessario creare un nuovo progetto in per eseguire una valutazione AWS SCT multiserver. Prima di iniziare, assicurati di aver preparato un file con valori separati da virgole (CSV) con i parametri di connessione al database. Inoltre, assicurati di aver installato tutti i driver di database necessari e di aver impostato la posizione dei driver nelle impostazioni. AWS SCT Per ulteriori informazioni, consulta Installazione dei driver JDBC per AWS Schema Conversion Tool.
Per eseguire una valutazione multiserver e creare un rapporto di riepilogo aggregato
-
In AWS SCT, scegli File, Nuova valutazione multiserver. Viene visualizzata la finestra di dialogo Nuova valutazione multiserver.
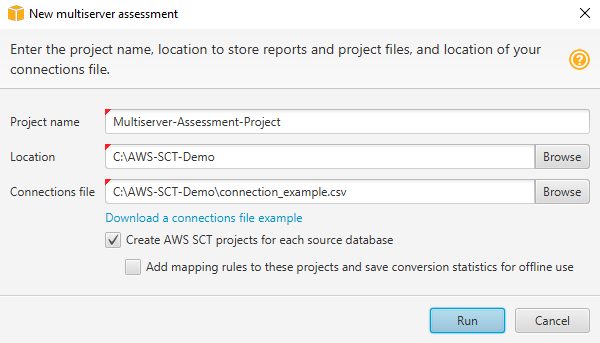
-
Scegli Scarica un esempio di file di connessioni per scaricare un modello vuoto di un file CSV con i parametri di connessione al database.
-
Inserisci i valori per il nome del progetto, la posizione (per archiviare i report) e il file di connessione (un file CSV).
-
Scegli Crea AWS SCT progetti per ogni database di origine per creare automaticamente progetti di migrazione dopo aver generato il rapporto di valutazione.
-
Con l'opzione Crea AWS SCT progetti per ogni database di origine attivata, puoi scegliere Aggiungi regole di mappatura a questi progetti e salvare le statistiche di conversione per l'utilizzo offline. In questo caso, AWS SCT aggiungerà regole di mappatura a ciascun progetto e salverà i metadati del database di origine nel progetto. Per ulteriori informazioni, consulta Utilizzo della modalità offline in AWS Schema Conversion Tool.
-
Scegli Esegui.
Viene visualizzata una barra di avanzamento che indica il ritmo di valutazione del database. Il numero di motori di destinazione può influire sulla durata della valutazione.
-
Scegli Sì se viene visualizzato il seguente messaggio: L'analisi completa di tutti i server di database potrebbe richiedere del tempo. Vuoi procedere?
Al termine del rapporto di valutazione multiserver, viene visualizzata una schermata che lo indica.
-
Scegli Apri rapporto per visualizzare il rapporto di valutazione riassuntivo aggregato.
Per impostazione predefinita, AWS SCT genera un rapporto aggregato per tutti i database di origine e un rapporto di valutazione dettagliato per ogni nome di schema in un database di origine. Per ulteriori informazioni, consulta Individuazione e visualizzazione dei report.
Con l'opzione Crea AWS SCT progetti per ogni database di origine attivata, AWS SCT crea un progetto vuoto per ogni database di origine. AWS SCT crea inoltre rapporti di valutazione come descritto in precedenza. Dopo aver analizzato questi rapporti di valutazione e scelto la destinazione di migrazione per ogni database di origine, aggiungi i database di destinazione a questi progetti vuoti.
Con l'opzione Aggiungi regole di mappatura a questi progetti e salva le statistiche di conversione per l'utilizzo offline, AWS SCT crea un progetto per ogni database di origine. Questi progetti includono le seguenti informazioni:
Il tuo database di origine e una piattaforma di database di destinazione virtuale. Per ulteriori informazioni, consulta Mappatura su obiettivi virtuali in AWS Schema Conversion Tool.
Una regola di mappatura per questa coppia sorgente-destinazione. Per ulteriori informazioni, consulta Mappatura dei tipi di dati.
Un rapporto di valutazione della migrazione del database per questa coppia sorgente-destinazione.
Metadati dello schema di origine, che consentono di utilizzare questo AWS SCT progetto in modalità offline. Per ulteriori informazioni, consulta Utilizzo della modalità offline in AWS Schema Conversion Tool.
Preparazione di un file CSV di input
Per fornire i parametri di connessione come input per il rapporto di valutazione multiserver, utilizzate un file CSV come mostrato nell'esempio seguente.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
L'esempio precedente utilizza un punto e virgola per separare i due nomi di schema per il database. Sales Utilizza inoltre un punto e virgola per separare le due piattaforme di migrazione del database di destinazione per il database. Sales
Inoltre, l'esempio precedente utilizza AWS Secrets Manager per connettersi al Customers database e Windows Authentication per connettersi al database. HR
È possibile creare un nuovo file CSV o scaricare un modello per un file CSV da AWS SCT e inserire le informazioni richieste. Assicurati che la prima riga del file CSV includa gli stessi nomi di colonna mostrati nell'esempio precedente.
Per scaricare un modello del file CSV di input
Inizia AWS SCT.
Scegli File, quindi scegli Nuova valutazione multiserver.
Scegli Scarica un esempio di file di connessioni.
Assicurati che il file CSV includa i seguenti valori, forniti dal modello:
-
Nome: l'etichetta di testo che aiuta a identificare il database. AWS SCT visualizza questa etichetta di testo nel rapporto di valutazione.
-
Descrizione: un valore facoltativo, in cui è possibile fornire informazioni aggiuntive sul database.
-
Secret Manager Key: il nome del segreto che memorizza le credenziali del AWS Secrets Manager database in. Per utilizzare Secrets Manager, assicurati di archiviare AWS i profili in AWS SCT. Per ulteriori informazioni, consulta Configurazione in AWS Secrets Manager AWS Schema Conversion Tool.
Importante
AWS SCT ignora il parametro Secret Manager Key se includete i parametri Server IP, Port, Login e Password nel file di input.
-
IP del server: il nome o l'indirizzo IP del Domain Name Service (DNS) del server del database di origine.
-
Porta: la porta utilizzata per connettersi al server del database di origine.
-
Nome servizio: se si utilizza un nome di servizio per connettersi al database Oracle, il nome del servizio Oracle a cui connettersi.
-
Nome del database: il nome del database. Per i database Oracle, utilizzare l'ID di sistema (SID) Oracle.
-
BigQuery path: il percorso del file chiave dell'account di servizio per il BigQuery database di origine. Per ulteriori informazioni sulla creazione di questo file, vederePrivilegi come fonte BigQuery.
-
Source Engine: il tipo di database di origine. Utilizza uno dei seguenti valori:
AZURE_MSSQL per un database SQL di Azure.
AZURE_SYNAPSE per un database di Azure Synapse Analytics.
BigQuery GOOGLE_BIGQUERY per un database.
DB2ZOS per un IBM Db2 per database. z/OS
DB2LUW per un database IBM Db2 LUW.
GREENPLUM per un database Greenplum.
MSSQL per un database Microsoft SQL Server.
MYSQL per un database MySQL.
NETEZZA per un database Netezza.
ORACLE per un database Oracle.
POSTGRESQL per un database PostgreSQL.
REDSHIFT per un database Amazon Redshift.
SNOWFLAKE per un database Snowflake.
SYBASE_ASE per un database SAP ASE.
TERADATA per un database Teradata.
VERTICA per un database Vertica.
-
Nomi degli schemi: i nomi degli schemi del database da includere nel rapporto di valutazione.
Per il database SQL di Azure, Azure Synapse Analytics, Netezza BigQuery, SAP ASE, Snowflake e SQL Server, usa il seguente formato del nome dello schema:
db_name.schema_nameSostituire con il nome
db_nameSostituire
schema_nameRacchiudi i nomi di database o schemi che includono un punto tra virgolette doppie come mostrato di seguito:.
"database.name"."schema.name"Separa più nomi di schemi utilizzando il punto e virgola come mostrato di seguito:.
Schema1;Schema2I nomi del database e dello schema fanno distinzione tra maiuscole e minuscole.
Utilizzate la percentuale (
%) come jolly per sostituire qualsiasi numero di simboli nel nome del database o dello schema. L'esempio precedente utilizza la percentuale (%) come carattere jolly per includere tutti gli schemi delemployeesdatabase nel rapporto di valutazione. -
Usa l'autenticazione di Windows: se utilizzi l'autenticazione di Windows per connetterti al tuo database di Microsoft SQL Server, inserisci true. Per ulteriori informazioni, consulta Utilizzo dell'autenticazione di Windows quando si utilizza Microsoft SQL Server come origine.
-
Login: il nome utente per la connessione al server del database di origine.
-
Password: la password per la connessione al server del database di origine.
-
Usa SSL: se utilizzi Secure Sockets Layer (SSL) per connetterti al database di origine, inserisci true.
-
Trust store: il trust store da utilizzare per la connessione SSL.
-
Archivio chiavi: l'archivio delle chiavi da utilizzare per la connessione SSL.
-
Autenticazione SSL: se utilizzi l'autenticazione SSL tramite certificato, inserisci true.
-
Target Engines: le piattaforme di database di destinazione. Utilizza i seguenti valori per specificare uno o più obiettivi nel rapporto di valutazione:
AURORA_MYSQL per un database compatibile con Aurora MySQL.
AURORA_POSTGRESQL per un database compatibile con Aurora PostgreSQL.
BABELFISH per un database PostgreSQL Babelfish per Aurora.
MARIA_DB per un database MariaDB.
MSSQL per un database Microsoft SQL Server.
MYSQL per un database MySQL.
ORACLE per un database Oracle.
POSTGRESQL per un database PostgreSQL.
REDSHIFT per un database Amazon Redshift.
Separa più destinazioni utilizzando punti e virgola come questo:.
MYSQL;MARIA_DBIl numero di obiettivi influisce sul tempo necessario per eseguire la valutazione.
Individuazione e visualizzazione dei report
La valutazione multiserver genera due tipi di report:
-
Un rapporto aggregato di tutti i database di origine.
-
Un rapporto di valutazione dettagliato dei database di destinazione per ogni nome di schema in un database di origine.
I report vengono archiviati nella directory scelta come Posizione nella finestra di dialogo Nuova valutazione multiserver.
Per accedere ai report dettagliati, è possibile navigare nelle sottodirectory, organizzate per database di origine, nome dello schema e motore di database di destinazione.
I report aggregati mostrano informazioni in quattro colonne sulla complessità di conversione di un database di destinazione. Le colonne includono informazioni sulla conversione di oggetti di codice, oggetti di archiviazione, elementi di sintassi e complessità della conversione.
L'esempio seguente mostra le informazioni per la conversione di due schemi di database Oracle in Amazon RDS for PostgreSQL.

Le stesse quattro colonne vengono aggiunte ai report per ogni motore di database di destinazione aggiuntivo specificato.
Per informazioni dettagliate su come leggere queste informazioni, consulta quanto segue.
Risultato per un rapporto di valutazione aggregato
Il rapporto aggregato di valutazione della migrazione del database multiserver AWS Schema Conversion Tool è un file CSV con le seguenti colonne:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Per raccogliere informazioni, AWS SCT esegue report di valutazione completi e quindi aggrega i report per schemi.
Nel rapporto, i tre campi seguenti mostrano la percentuale di possibile conversione automatica in base alla valutazione:
- % di conversione degli oggetti di codice
-
La percentuale di oggetti di codice nello schema che AWS SCT possono essere convertiti automaticamente o con modifiche minime. Gli oggetti di codice includono procedure, funzioni, viste e simili.
- % di conversione degli oggetti di archiviazione
-
La percentuale di oggetti di storage che SCT può convertire automaticamente o con modifiche minime. Gli oggetti di archiviazione includono tabelle, indici, vincoli e simili.
- % di conversione degli elementi di sintassi
-
La percentuale di elementi di sintassi che SCT può convertire automaticamente. Gli elementi di sintassi includono
SELECT,,FROMDELETE, eJOINclausole e simili.
Il calcolo della complessità della conversione si basa sulla nozione di azioni. Un'azione riflette un tipo di problema riscontrato nel codice sorgente che è necessario correggere manualmente durante la migrazione verso una destinazione particolare. Un'azione può avere più ricorrenze.
Una scala ponderata identifica il livello di complessità per l'esecuzione di una migrazione. Il numero 1 rappresenta il livello di complessità più basso e il numero 10 rappresenta il livello di complessità più elevato.
