Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione dei dati dal data warehouse locale ad Amazon Redshift con AWS Schema Conversion Tool
Puoi utilizzare un AWS SCT agente per estrarre dati dal tuo data warehouse locale e migrarli su Amazon Redshift. L'agente estrae i dati e li carica su Amazon S3 o, per le migrazioni su larga scala, su un dispositivo Edge. AWS Snowball Edge Puoi quindi utilizzare un AWS SCT agente per copiare i dati su Amazon Redshift.
In alternativa, puoi utilizzare AWS Database Migration Service (AWS DMS) per migrare i dati su Amazon Redshift. Il vantaggio di AWS DMS è il supporto della replica continua (acquisizione dei dati di modifica). Tuttavia, per aumentare la velocità di migrazione dei dati, utilizza diversi AWS SCT agenti in parallelo. Secondo i nostri test, AWS SCT gli agenti migrano i dati più velocemente del AWS DMS 15-35 percento. La differenza di velocità è dovuta alla compressione dei dati, al supporto della migrazione delle partizioni di tabella in parallelo e alle diverse impostazioni di configurazione. Per ulteriori informazioni, consultare Utilizzo di un database Amazon Redshift come destinazione per AWS Database Migration Service.
Amazon S3 è un servizio di storage e di recupero. Per archiviare un oggetto in Amazon S3, è necessario caricare il file da archiviare in un bucket Amazon S3. Durante il caricamento di un file, puoi impostare le autorizzazioni per l'oggetto e anche per eventuali metadata.
Migrazioni su larga scala
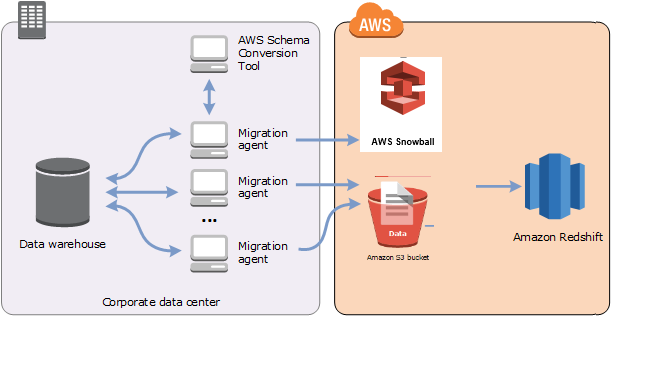
Le migrazioni di dati su larga scala possono includere molti terabyte di informazioni e possono essere rallentate dalle prestazioni della rete e dall'enorme quantità di dati da spostare. AWS Snowball Edge Edge è un AWS servizio che puoi utilizzare per trasferire dati sul cloud a velocità elevate utilizzando un'appliance di proprietà. faster-than-network AWS Un dispositivo AWS Snowball Edge Edge può contenere fino a 100 TB di dati. Utilizza una crittografia a 256 bit e un Trusted Platform Module (TPM) standard di settore per garantire la sicurezza e la completezza dei dati. chain-of-custody AWS SCT AWS Snowball Edge funziona con dispositivi Edge.
Quando utilizzi AWS SCT un dispositivo AWS Snowball Edge Edge, esegui la migrazione dei dati in due fasi. Innanzitutto, è necessario AWS SCT elaborare i dati localmente e quindi spostarli AWS Snowball Edge sul dispositivo Edge. Quindi invii il dispositivo a AWS utilizzare il processo AWS Snowball Edge Edge e quindi carichi AWS automaticamente i dati in un bucket Amazon S3. Successivamente, quando i dati sono disponibili su Amazon S3, li usi AWS SCT per migrare i dati su Amazon Redshift. Gli agenti di estrazione dei dati possono lavorare in background mentre AWS SCT sono chiusi.
Il seguente diagramma mostra lo scenario supportato.
Gli agenti di estrazione dei dati sono attualmente supportati per i seguenti data warehouse di origine:
Azure Synapse Analytics
BigQuery
Database Greenplum (versione 4.3)
Microsoft SQL Server (versione 2008 e successive)
Netezza (versione 7.0.3 e successive)
Oracle (versione 10 e successive)
Snowflake (versione 3)
Teradata (versione 13 e successive)
Vertica (versione 7.2.2 e successive)
Puoi connetterti agli endpoint FIPS per Amazon Redshift se devi rispettare i requisiti di sicurezza del Federal Information Processing Standard (FIPS). Gli endpoint FIPS sono disponibili nelle seguenti regioni: AWS
Regione Stati Uniti orientali (Virginia settentrionale) (redshift-fips.us-east-1.amazonaws.com)
Regione Stati Uniti orientali (Ohio) (redshift-fips.us-east-2.amazonaws.com)
Regione Stati Uniti occidentali (California settentrionale) (redshift-fips.us-west-1.amazonaws.com)
Regione Stati Uniti occidentali (Oregon) (redshift-fips.us-west-2.amazonaws.com)
Utilizza le informazioni nei seguenti argomenti per scoprire come lavorare con gli agenti di estrazione dei dati.
Argomenti
Prerequisiti per l'utilizzo degli agenti di estrazione dei dati
Registrazione degli agenti di estrazione con AWS Schema Conversion Tool
Modifica dell'estrattore e copia le impostazioni dalle impostazioni del progetto
Ordinamento dei dati prima della migrazione utilizzando AWS SCT
Creazione, esecuzione e monitoraggio di un'attività di estrazione dei dati AWS SCT
Esportazione e importazione di un'attività di estrazione dei dati AWS SCT
Estrazione dei dati tramite un dispositivo AWS Snowball Edge Edge
Utilizzo del partizionamento virtuale con AWS Schema Conversion Tool
Migliori pratiche e risoluzione dei problemi per gli agenti di estrazione dei dati
Prerequisiti per l'utilizzo degli agenti di estrazione dei dati
Prima di lavorare con agenti di estrazione dati, aggiungi le autorizzazioni necessarie per Amazon Redshift come destinazione al tuo utente Amazon Redshift. Per ulteriori informazioni, consulta Autorizzazioni per Amazon Redshift come destinazione.
Quindi, archivia le informazioni sul bucket Amazon S3 e configura l'archivio di fiducia e chiavi Secure Sockets Layer (SSL).
Impostazioni Amazon S3
Dopo che i tuoi agenti hanno estratto i tuoi dati, li caricano nel tuo bucket Amazon S3. Prima di continuare, devi fornire le credenziali per connetterti al tuo AWS account e al tuo bucket Amazon S3. Memorizzi le credenziali e le informazioni sul bucket in un profilo nelle impostazioni globali dell'applicazione, quindi associ il profilo al tuo progetto. AWS SCT Se necessario, scegliete Impostazioni globali per creare un nuovo profilo. Per ulteriori informazioni, consulta Gestione dei profili in AWS Schema Conversion Tool.
Per migrare i dati nel database Amazon Redshift di destinazione, AWS SCT l'agente di estrazione dei dati necessita dell'autorizzazione per accedere al bucket Amazon S3 per tuo conto. Per fornire questa autorizzazione, crea un utente AWS Identity and Access Management (IAM) con la seguente politica.
Nell'esempio precedente, sostituiscilo bucket_name111122223333:user/DataExtractionAgentName
Assumendo ruoli IAM
Per una maggiore sicurezza, puoi utilizzare i ruoli AWS Identity and Access Management (IAM) per accedere al tuo bucket Amazon S3. Per farlo, crea un utente IAM per i tuoi agenti di estrazione dati senza alcuna autorizzazione. Quindi, crea un ruolo IAM che abiliti l'accesso ad Amazon S3 e specifica l'elenco di servizi e utenti che possono assumere questo ruolo. Per ulteriori informazioni, consulta Ruoli IAM nella Guida per l'utente IAM.
Per configurare i ruoli IAM per accedere al tuo bucket Amazon S3
-
Crea un nuovo utente IAM. Per le credenziali utente, scegli il tipo di accesso programmatico.
-
Configura l'ambiente host in modo che l'agente di estrazione dei dati possa assumere il ruolo che AWS SCT gli viene fornito. Assicurati che l'utente che hai configurato nel passaggio precedente consenta agli agenti di estrazione dei dati di utilizzare la catena di fornitori di credenziali. Per ulteriori informazioni, consulta Utilizzo delle credenziali nella Guida per gli AWS SDK per Java sviluppatori.
-
Crea un nuovo ruolo IAM con accesso al tuo bucket Amazon S3.
-
Modifica la sezione relativa alla fiducia di questo ruolo in modo che l'utente che hai creato in precedenza assuma il ruolo. Nell'esempio seguente, sostituiscilo
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
Modifica la sezione relativa alla fiducia di questo ruolo in modo che assuma il ruolo come affidabile
redshift.amazonaws.com.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Collega questo ruolo al tuo cluster Amazon Redshift.
Ora puoi eseguire il tuo agente di estrazione dati in AWS SCT.
Quando si utilizza l'assunzione del ruolo IAM, la migrazione dei dati funziona nel modo seguente. L'agente di estrazione dei dati si avvia e ottiene le credenziali dell'utente utilizzando la catena di fornitori di credenziali. Successivamente, si crea un'attività di migrazione dei dati in AWS SCT, quindi si specifica il ruolo IAM che gli agenti di estrazione dei dati devono assumere e si avvia l'attività. Servizio di token di sicurezza AWS (AWS STS) genera credenziali temporanee per accedere ad Amazon S3. L'agente di estrazione dati utilizza queste credenziali per caricare dati su Amazon S3.
Quindi, AWS SCT fornisce ad Amazon Redshift il ruolo IAM. A sua volta, Amazon Redshift ottiene nuove credenziali temporanee per accedere AWS STS ad Amazon S3. Amazon Redshift utilizza queste credenziali per copiare i dati da Amazon S3 alla tabella Amazon Redshift.
Impostazioni di sicurezza
L'agente di estrazione AWS Schema Conversion Tool e gli agenti di estrazione possono comunicare tramite Secure Sockets Layer (SSL). Per abilitare SSL, configura un archivio della chiave e di trust.
Per configurare una comunicazione sicura con il tuo agente di estrazione
-
Avvia il. AWS Schema Conversion Tool
-
Apri il menu Impostazioni, quindi scegli Impostazioni globali. Si aprirà la finestra di dialogo Global Settings (Impostazioni globali).
-
Scegliere Sicurezza.
-
Scegli Genera fiducia e archivio chiavi oppure seleziona Seleziona archivio attendibile esistente.
Se scegli Generate trust e key store, specifichi il nome e la password per gli archivi trust e key e il percorso della posizione dei file generati. Utilizzerai questi file in un secondo momento.
Se scegli Select existing trust store, specifichi quindi la password e il nome del file per gli archivi trust e key. Utilizzerai questi file in un secondo momento.
-
Dopo aver specificato trust store e key store, scegliete OK per chiudere la finestra di dialogo delle impostazioni globali.
Configurazione dell'ambiente per gli agenti di estrazione dei dati
È possibile installare diversi agenti di estrazione dati su un singolo host. Tuttavia, si consiglia di eseguire un agente di estrazione dati su un host.
Per eseguire l'agente di estrazione dati, assicurati di utilizzare un host con almeno quattro v CPUs e 32 GB di memoria. Inoltre, imposta la memoria minima disponibile AWS SCT su almeno quattro GB. Per ulteriori informazioni, consulta Configurazione della memoria aggiuntiva.
La configurazione ottimale e il numero di host degli agenti dipendono dalla situazione specifica di ciascun cliente. Assicurati di considerare fattori quali la quantità di dati da migrare, la larghezza di banda della rete, il tempo necessario per estrarre i dati e così via. È possibile eseguire prima un proof of concept (PoC), quindi configurare gli agenti e gli host di estrazione dei dati in base ai risultati di questo PoC.
Installazione degli agenti di estrazione
È consigliabile installare più agenti di estrazione sui singoli computer, separati dal computer su cui è in esecuzione AWS Schema Conversion Tool.
Gli agenti di estrazione sono attualmente supportati per i seguenti sistemi operativi:
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux (versione 14.04 e successive)
Utilizza la procedura seguente per installare gli agenti di estrazione. Ripeti questa procedura per ogni computer su cui si desidera installare un agente di estrazione.
Per installare un agente di estrazione
-
Se non avete ancora scaricato il file di AWS SCT installazione, seguite le istruzioni riportate Installazione e configurazione AWS Schema Conversion Tool per scaricarlo. Il file.zip che contiene il file di AWS SCT installazione contiene anche il file di installazione dell'agente di estrazione.
-
Scarica e installa l'ultima versione di Amazon Corretto 11. Per ulteriori informazioni, consulta Download per Amazon Corretto 11 nella Guida per l'utente di Amazon Corretto 11.
-
Individua il file del programma di installazione del tuo agente di estrazione in una sottocartella denominata agenti. Per ogni sistema operativo, il file corretto per installare l'agente di estrazione è riportato di seguito.
Sistema operativo Nome file Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
Installa l'agente di estrazione su un computer separato copiando il file di installazione sul nuovo computer.
-
Esegui il file del programma di installazione. Utilizza le istruzioni per il tuo sistema operativo riportate di seguito.
Sistema operativo Istruzioni di installazione Microsoft Windows
Fai doppio clic sul file per eseguire il programma di installazione.
RHEL
Esegui i seguenti comandi nella cartella in cui hai scaricato o spostato il file.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
Esegui i seguenti comandi nella cartella in cui hai scaricato o spostato il file.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
Scegli Avanti, accetta il contratto di licenza e scegli Avanti.
-
Inserisci il percorso per installare l'agente di estrazione AWS SCT dei dati e scegli Avanti.
-
Scegli Installa per installare l'agente di estrazione dati.
AWS SCT installa il tuo agente di estrazione dati. Per completare l'installazione, configura l'agente di estrazione dati. AWS SCT avvia automaticamente il programma di configurazione. Per ulteriori informazioni, consulta Configurazione degli agenti di estrazione.
-
Scegli Fine per chiudere la procedura guidata di installazione dopo aver configurato l'agente di estrazione dei dati.
Configurazione degli agenti di estrazione
Utilizza la procedura seguente per configurare gli agenti di estrazione. Ripeti questa procedura su ogni computer su cui è installato un agente di estrazione.
Per configurare l'agente di estrazione
-
Avvia il programma di configurazione:
-
In Windows, AWS SCT avvia automaticamente il programma di configurazione durante l'installazione di un agente di estrazione dati.
Se necessario, è possibile avviare il programma di installazione manualmente. A tale scopo, esegui il
ConfigAgent.batfile in Windows. Puoi trovare questo file nella cartella in cui hai installato l'agente. -
In RHEL e Ubuntu, esegui il
sct-extractor-setup.shfile dalla posizione in cui hai installato l'agente.
Il programma di installazione richiede informazioni. Per ogni richiesta, appare un valore predefinito.
-
-
Accettate il valore predefinito a ogni richiesta o immettete un nuovo valore.
Specificare le seguenti informazioni:
Per Porta di ascolto, inserite il numero di porta su cui l'agente è in ascolto.
Per Aggiungi un fornitore di origine, inserisci sì, quindi inserisci la piattaforma di data warehouse di origine.
Per il driver JDBC, inserisci la posizione in cui hai installato i driver JDBC.
Per Working folder, inserisci il percorso in cui l'agente di estrazione dei AWS SCT dati memorizzerà i dati estratti. La cartella di lavoro può essere su un computer diverso dall'agente e una singola cartella di lavoro può essere condivisa da più agenti su diversi computer.
Per Abilita la comunicazione SSL, inserisci yes.
Per Archivio chiavi, inserisci la posizione del file dell'archivio delle chiavi.
Per Password dell'archivio chiavi, inserisci la password per l'archivio chiavi.
Per Abilita l'autenticazione SSL del client, inserisci yes.
Per Trust store, inserisci la posizione del file Trust Store.
Per la password del Trust Store, inserisci la password per il Trust Store.
Il programma di installazione aggiorna il file delle impostazioni per l'agente di estrazione. Il file delle impostazioni è denominato settings.properties e si trova nella stessa posizione in cui hai installato l'agente di estrazione.
Di seguito è riportato un esempio di file delle impostazioni.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFFPer modificare le impostazioni di configurazione, è possibile modificare il settings.properties file utilizzando un editor di testo o eseguire nuovamente la configurazione dell'agente.
Installazione e configurazione degli agenti di estrazione con agenti di copia dedicati
È possibile installare agenti di estrazione in una configurazione con storage condiviso e un agente di copia dedicato. Il diagramma seguente illustra questo scenario.
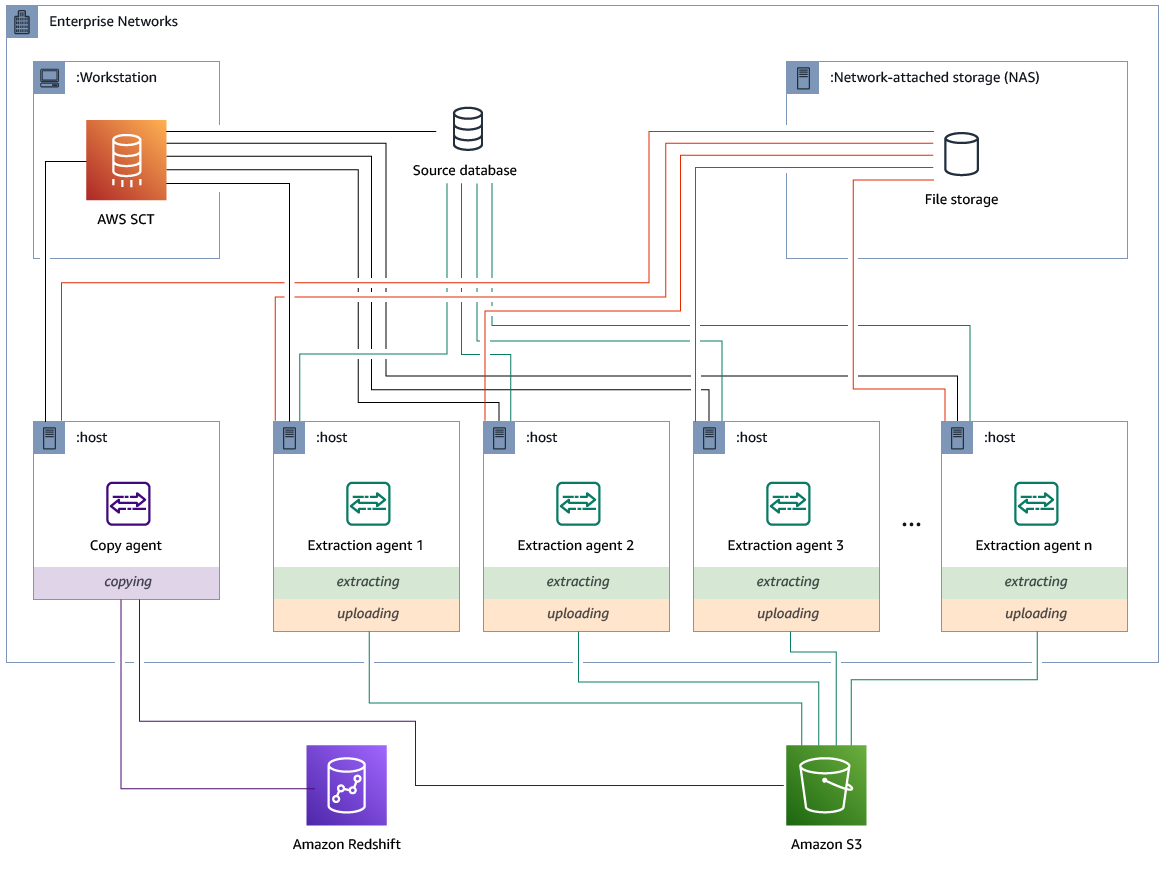
Questa configurazione può essere utile quando un server di database di origine supporta fino a 120 connessioni e la rete dispone di un ampio spazio di archiviazione collegato. Utilizzate la procedura seguente per configurare gli agenti di estrazione con un agente di copia dedicato.
Per installare e configurare agenti di estrazione e un agente di copia dedicato
-
Assicuratevi che la directory di lavoro di tutti gli agenti di estrazione utilizzi la stessa cartella sullo storage condiviso.
-
Installa gli agenti di estrazione seguendo la procedura riportata di seguito. Installazione degli agenti di estrazione
-
Configura gli agenti di estrazione seguendo i passaggi indicatiConfigurazione degli agenti di estrazione, ma specifica solo il driver JDBC di origine.
-
Configura un agente di copia dedicato seguendo i passaggi indicatiConfigurazione degli agenti di estrazione, ma specifica solo un driver JDBC Amazon Redshift.
Avvio degli agenti di estrazione
Utilizza la procedura seguente per avviare gli agenti di estrazione. Ripeti questa procedura su ogni computer su cui è installato un agente di estrazione.
Gli agenti di estrazione fungono da ascoltatori. Quando avvii un agente con questa procedura, l'agente avvia l'ascolto delle relative istruzioni. Puoi inviare agli agenti le istruzioni per estrarre i dati provenienti dal data warehouse in una sezione successiva.
Per avviare l'agente di estrazione
-
Nel computer in cui è installato l'agente di estrazione, esegui il comando elencato di seguito per il tuo sistema operativo.
Sistema operativo Comando di avvio Microsoft Windows
Fai doppio clic sul file batch
StartAgent.bat.RHEL
Esegui il comando seguente nel percorso per la cartella in cui hai installato l'agente:
sudo initctlstartsct-extractorUbuntu Linux
Esegui il comando seguente nel percorso per la cartella in cui hai installato l'agente. Utilizza il comando appropriato alla tua versione di Ubuntu.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 e versioni successive:
sudo systemctlstartsct-extractor
Per controllare lo stato dell'agente, esegui lo stesso comando, ma sostituisci start con status.
Per arrestare un agente, esegui lo stesso comando, ma sostituisci start con stop.
Registrazione degli agenti di estrazione con AWS Schema Conversion Tool
Gestisci i tuoi agenti di estrazione utilizzando AWS SCT. Gli agenti di estrazione fungono da ascoltatori. Quando ricevono istruzioni da AWS SCT, estraggono i dati dal tuo data warehouse.
Utilizzate la seguente procedura per registrare gli agenti di estrazione nel AWS SCT progetto.
Per registrare un agente di estrazione
-
AWS Schema Conversion Tool Avviate e aprite un progetto.
-
Apri il menu Visualizza, quindi scegli Data Migration view (altro). Viene visualizzata la scheda Agents (Agenti). Se hai già degli agenti registrati, li AWS SCT visualizza in una griglia nella parte superiore della scheda.
-
Scegli Registrati.
Dopo aver registrato un agente per un AWS SCT progetto, non puoi registrare lo stesso agente per un progetto diverso. Se non utilizzi più un agente in un AWS SCT progetto, puoi annullarne la registrazione. Puoi registrarlo con un progetto diverso.
-
Scegli Redshift Data Agent, quindi scegli OK.
-
Inserisci le tue informazioni nella scheda Connessione della finestra di dialogo:
-
In Descrizione, inserisci una descrizione dell'agente.
-
Per Nome host, inserire il nome host o l'indirizzo IP del computer dell'agente.
-
In Porta, inserisci il numero di porta su cui l'agente è in ascolto.
-
Scegli Registra per registrare l'agente nel tuo AWS SCT progetto.
-
-
Ripeti i passaggi precedenti per registrare più agenti con il tuo progetto AWS SCT .
Nascondere e recuperare informazioni per un agente AWS SCT
Un AWS SCT agente crittografa una quantità significativa di informazioni, ad esempio le password degli archivi di fiducia delle chiavi degli utenti, gli account del database, le informazioni sugli AWS account e elementi simili. Lo fa utilizzando un file speciale chiamato seed.dat. Per impostazione predefinita, l'agente crea questo file nella cartella di lavoro dell'utente che configura per primo l'agente.
Poiché utenti diversi possono configurare ed eseguire l'agente, il percorso per seed.dat viene memorizzato nel parametro {extractor.private.folder} del file settings.properties. Quando l'agente viene avviato, può usare questo percorso per trovare il file seed.dat per accedere alle informazioni relative all'archivio di trust-della chiave per il database su cui agisce.
Potresti dover recuperare le password che un agente ha archiviato in questi casi:
Se l'utente perde il
seed.datfile e la posizione e la porta dell' AWS SCT agente non sono cambiate.Se l'utente perde il
seed.datfile e la posizione e la porta dell' AWS SCT agente sono cambiate. In questo caso, la modifica in genere si verifica perché l'agente è stato migrato a un altro host o la porta e le informazioni contenute nelseed.datfile non sono più valide.
In questi casi, se un agente viene avviato senza SSL, si avvia e quindi accede allo storage dell'agente creato in precedenza. Quindi va nello stato Waiting for recovery (In attesa di ripristino)..
Tuttavia, in questi casi, se un agente viene avviato con SSL non puoi riavviarlo. Questo perché l'agente non è in grado di decriptare le password archiviate nel file settings.properties. In questo tipo di avvio, l'agente non riesce ad avviarsi. Un errore simile al seguente è scritto nel log: "L'agente non è stato in grado di avviarsi con la modalità SSL abilitata. Si prega di riconfigurare l'agente. Motivo: la password per il keystore non è corretta."
Per risolvere questo problema, crea un nuovo agente e configuralo in modo da utilizzare le password esistenti per accedere ai certificati SSL. A tale scopo, procedi come indicato di seguito.
Dopo aver eseguito questa procedura, l'agente dovrebbe avviarsi e passare allo stato In attesa di ripristino. AWS SCT invia automaticamente le password necessarie a un agente nello stato Waiting for recovery. Quando l'agente ha le password, riavvia qualsiasi attività. Non sono necessarie ulteriori azioni da AWS SCT parte dell'utente.
Per riconfigurare l'agente e ripristinare le password per l'accesso ai certificati SSL
Installa un nuovo AWS SCT agente ed esegui la configurazione.
Cambia la proprietà
agent.namenel fileinstance.propertiesper il nome dell'agente per cui lo storage è stato creato, per far sì che il nuovo agente sia compatibile con lo storage dell'agente esistente.Il file
instance.propertiesviene archiviato nella cartella privata dell'agente, denominata utilizzando la seguente convenzione:{.output.folder}\dmt\{hostName}_{portNumber}\Cambia il nome di
{in quello della cartella di output dell'agente precedente.output.folder}A questo punto, AWS SCT sta ancora cercando di accedere al vecchio estrattore sul vecchio host e sulla vecchia porta. Di conseguenza, l'estrattore inaccessibile ottiene lo stato FAILED. Puoi modificare l'host e la porta.
Modifica l'host, la porta (o entrambi) dell'agente precedente utilizzando il comando Modifica per reindirizzare il flusso di richiesta al nuovo agente.
Quando AWS SCT può eseguire il ping del nuovo agente, AWS SCT riceve lo stato In attesa di ripristino dall'agente. AWS SCT quindi recupera automaticamente le password dell'agente.
Ogni agente che funziona con lo storage dell'agente aggiorna un file speciale chiamato storage.lck posizionato in {. Questo file contiene l'ID di rete dell'agente e il tempo durante cui lo storage è bloccato. Quando l'agente funziona con lo storage dell'agente, aggiorna il file output.folder}\{agentName}\storage\storage.lck ed estende la decorrenza dello storage di 10 minuti ogni 5 minuti. Nessuna altra istanza può funzionare con lo storage di questo agente prima della scadenza della decorrenza.
Creazione di regole di migrazione dei dati in AWS SCT
Prima di estrarre i dati con AWS Schema Conversion Tool, puoi impostare filtri che riducano la quantità di dati che estrai. È possibile creare regole di migrazione dei dati utilizzando WHERE clausole per ridurre i dati estratti. Ad esempio, puoi scrivere una clausola WHERE che seleziona i dati da un'unica tabella.
Puoi creare regole di migrazione dei dati e salvare i filtri come parte del tuo progetto. Con il progetto aperto, utilizzate la procedura seguente per creare regole di migrazione dei dati.
Per creare regole di migrazione dei dati
-
Apri il menu Visualizza, quindi scegli Data Migration view (altro).
-
Scegli Regole di migrazione dei dati, quindi scegli Aggiungi nuova regola.
-
Configura la tua regola di migrazione dei dati:
-
In Nome, inserisci un nome per la regola di migrazione dei dati.
-
Per Dove il nome dello schema è simile, inserisci un filtro da applicare agli schemi. In questo filtro, una clausola
WHEREviene valutata utilizzando una clausolaLIKE. Per scegliere uno schema, inserisci un nome esatto dello schema. Per scegliere più schemi, usa il carattere «%» come jolly per abbinare un numero qualsiasi di caratteri nel nome dello schema. -
Ad esempio, inserisci un filtro da applicare alle tabelle. In questo filtro, una clausola
WHEREviene valutata utilizzando una clausolaLIKE. Per scegliere una tabella, inserisci un nome esatto. Per scegliere più tabelle, usa il carattere «%» come jolly per abbinare un numero qualsiasi di caratteri nel nome della tabella. -
Per la clausola Where, inserisci una
WHEREclausola per filtrare i dati.
-
-
Dopo aver configurato il filtro, selezionare Salva per salvare il filtro o Annulla per annullare le modifiche.
-
Dopo aver aggiunto, modificato ed eliminato i filtri, scegli Salva tutto per salvare tutte le modifiche.
Per disattivare un filtro senza eliminarlo, utilizza l'icona di attivazione/disattivazione. Per duplicare un filtro esistente, utilizza l'icona Copia. Per eliminare un filtro esistente, utilizza l'icona Elimina. Per salvare le modifiche apportate ai filtri, scegli Salva tutto.
Modifica dell'estrattore e copia le impostazioni dalle impostazioni del progetto
Dalla finestra delle impostazioni del progetto in AWS SCT, puoi scegliere le impostazioni per gli agenti di estrazione dei dati e il comando Amazon RedshiftCOPY.
Per scegliere queste impostazioni, scegli Impostazioni, Impostazioni del progetto, quindi scegli Migrazione dei dati. Qui puoi modificare le impostazioni di estrazione, le impostazioni di Amazon S3 e le impostazioni di copia.
Utilizza le istruzioni nella tabella seguente per fornire le informazioni per le impostazioni di estrazione.
| Per questo parametro | Esegui questa operazione |
|---|---|
Formato di compressione |
Specificate il formato di compressione dei file di input. Scegliete una delle seguenti opzioni: GZIP BZIP2, ZSTD o Nessuna compressione. |
Carattere delimitatore |
Specificate il carattere ASCII che separa i campi nei file di input. I caratteri non stampabili non sono supportati. |
Valore NULL come stringa |
Attiva questa opzione se i dati includono un terminatore nullo. Se questa opzione è disattivata, il |
Strategia di ordinamento |
Usa l'ordinamento per riavviare l'estrazione dal punto di errore. Scegliete una delle seguenti strategie di ordinamento: Usa l'ordinamento dopo il primo errore (consigliato), Usa l'ordinamento se possibile o Non usare mai l'ordinamento. Per ulteriori informazioni, consulta Ordinamento dei dati prima della migrazione utilizzando AWS SCT. |
Schema temporaneo di origine |
Immettete il nome dello schema nel database di origine, in cui l'agente di estrazione può creare gli oggetti temporanei. |
Dimensione del file in uscita (in MB) |
Inserisci la dimensione, in MB, dei file caricati su Amazon S3. |
Dimensione del file Snowball out (in MB) |
Inserisci la dimensione, in MB, dei file caricati su. AWS Snowball Edge Le dimensioni dei file possono essere comprese tra 1 e 1.000 MB. |
Utilizza il partizionamento automatico. Per Greenplum e Netezza, inserisci la dimensione minima delle tabelle supportate (in megabyte) |
Attiva questa opzione per utilizzare il partizionamento delle tabelle, quindi inserisci la dimensione delle tabelle da partizionare per i database di origine Greenplum e Netezza. Per le migrazioni da Oracle ad Amazon Redshift, puoi lasciare vuoto questo campo perché AWS SCT crea sottoattività per tutte le tabelle partizionate. |
Estrarre LOBs |
Attiva questa opzione per estrarre oggetti di grandi dimensioni (LOBs) dal database di origine. LOBs include BLOBs, CLOBs, NCLOBs, file XML e così via. Per ogni LOB, gli agenti AWS SCT di estrazione creano un file di dati. |
Cartella bucket Amazon S3 LOBs |
Inserisci la posizione degli agenti di AWS SCT estrazione da archiviare. LOBs |
Applica RTRIM alle colonne di stringhe |
Attiva questa opzione per tagliare un set di caratteri specificato dalla fine delle stringhe estratte. |
Conserva i file localmente dopo il caricamento su Amazon S3 |
Attiva questa opzione per conservare i file sul computer locale dopo che gli agenti di estrazione dei dati li hanno caricati su Amazon S3. |
Utilizza le istruzioni nella tabella seguente per fornire le informazioni per le impostazioni di Amazon S3.
| Per questo parametro | Esegui questa operazione |
|---|---|
Usa un proxy |
Attiva questa opzione per utilizzare un server proxy per caricare dati su Amazon S3. Quindi scegli il protocollo di trasferimento dati, inserisci il nome host, la porta, il nome utente e la password. |
Endpoint type (Tipo di endpoint) |
Scegli FIPS per utilizzare l'endpoint FIPS (Federal Information Processing Standard). Scegli VPCE per utilizzare l'endpoint del cloud privato virtuale (VPC). Quindi, per l'endpoint VPC, inserisci il Domain Name System (DNS) del tuo endpoint VPC. |
Conserva i file su Amazon S3 dopo averli copiati su Amazon Redshift |
Attiva questa opzione per conservare i file estratti su Amazon S3 dopo averli copiati su Amazon Redshift. |
Utilizza le istruzioni nella tabella seguente per fornire le informazioni per le impostazioni di copia.
| Per questo parametro | Esegui questa operazione |
|---|---|
Numero massimo di errori |
Immettere il numero di errori di caricamento. Dopo che l'operazione raggiunge questo limite, gli agenti di estrazione AWS SCT dei dati terminano il processo di caricamento dei dati. Il valore predefinito è 0, il che significa che gli agenti di estrazione AWS SCT dei dati continuano il caricamento dei dati indipendentemente dagli errori. |
Sostituisce i caratteri UTF-8 non validi |
Attiva questa opzione per sostituire i caratteri UTF-8 non validi con il carattere specificato e continuare l'operazione di caricamento dei dati. |
Usa il valore vuoto come valore nullo |
Attiva questa opzione per caricare campi vuoti costituiti da caratteri di spazio bianco come nulli. |
Usa vuoto come valore nullo |
Attiva questa opzione per caricare campi vuoti |
Tronca le colonne |
Attiva questa opzione per troncare i dati in colonne per adattarli alle specifiche del tipo di dati. |
Compressione automatica |
Attiva questa opzione per applicare la codifica di compressione durante un'operazione di copia. |
Aggiornamento automatico delle statistiche |
Attiva questa opzione per aggiornare le statistiche al termine di un'operazione di copia. |
Controlla il file prima del caricamento |
Attiva questa opzione per convalidare i file di dati prima di caricarli su Amazon Redshift. |
Ordinamento dei dati prima della migrazione utilizzando AWS SCT
L'ordinamento dei dati prima della migrazione AWS SCT offre alcuni vantaggi. Se si ordinano prima i dati, AWS SCT è possibile riavviare l'agente di estrazione dall'ultimo punto salvato dopo un errore. Inoltre, se stai migrando i dati su Amazon Redshift e li ordini prima AWS SCT , puoi inserirli in Amazon Redshift più velocemente.
Questi vantaggi riguardano il modo in cui vengono AWS SCT create le query di estrazione dei dati. In alcuni casi, AWS SCT utilizza la funzione analitica DENSE_RANK in queste query. Tuttavia, DENSE_RANK può utilizzare molto tempo e risorse del server per ordinare il set di dati risultante dall'estrazione, quindi se può funzionare senza di esso, funziona. AWS SCT
Per ordinare i dati prima della migrazione, utilizzare AWS SCT
Aprire un AWS SCT progetto.
Apri il menu contestuale (fai clic con il pulsante destro del mouse) per l'oggetto, quindi scegli Crea attività locale.
Scegli la scheda Avanzate e, per Strategia di ordinamento, scegli un'opzione:
Non utilizzare mai l'ordinamento: l'agente di estrazione non utilizza la funzione analitica DENSE_RANK e si riavvia dall'inizio in caso di errore.
Se possibile, utilizzate l'ordinamento: l'agente di estrazione utilizza DENSE_RANK se la tabella ha una chiave primaria o un vincolo univoco.
Utilizza l'ordinamento dopo il primo errore (consigliato): l'agente di estrazione tenta innanzitutto di ottenere i dati senza utilizzare DENSE_RANK. Se il primo tentativo ha esito negativo, l'agente di estrazione ricostruisce la query utilizzando DENSE_RANK e conserva la propria posizione in caso di guasto.
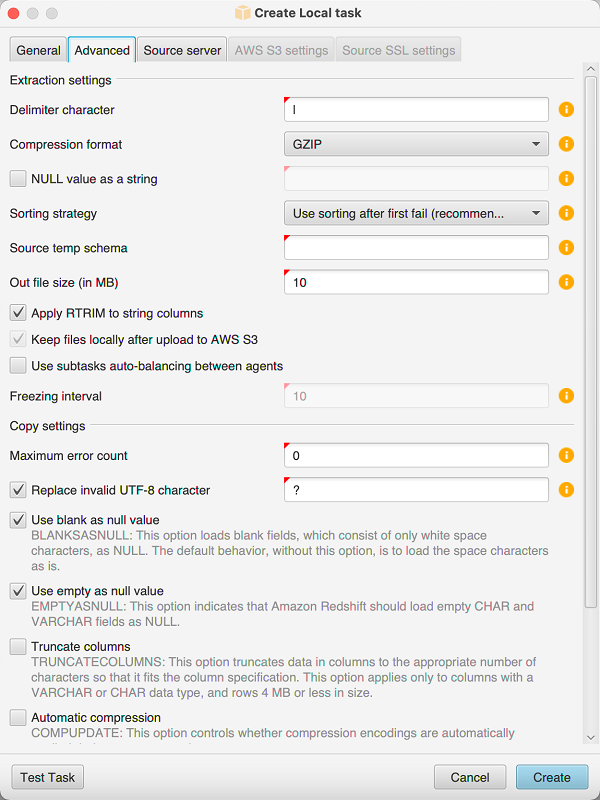
Impostare parametri aggiuntivi come descritto di seguito, quindi scegli Crea per creare la tua attività di estrazione dei dati.
Creazione, esecuzione e monitoraggio di un'attività di estrazione dei dati AWS SCT
Utilizza le seguenti procedure per creare, eseguire e monitorare le attività di estrazione dei dati.
Per assegnare le attività agli agenti e migrare i dati
-
In AWS Schema Conversion Tool, dopo aver convertito lo schema, scegli una o più tabelle dal pannello di sinistra del progetto.
Puoi scegliere tutte le tabelle, ma è un'azione che sconsigliamo per motivi di prestazioni. È consigliabile creare più attività per più tabelle in base alle dimensioni delle tabelle del data warehouse.
-
Apri il menu contestuale (fai clic con il pulsante destro del mouse) per ogni tabella, quindi scegli Crea attività. Viene visualizzata la finestra di dialogo Crea attività locale.
-
In Nome attività, inserisci un nome per l'attività.
-
Per la modalità di migrazione, scegli una delle seguenti opzioni:
-
Solo estrazione: estrai i dati e salvali nelle cartelle di lavoro locali.
-
Estrazione e caricamento: estrai i dati e caricali su Amazon S3.
-
Estrai, carica e copia: estrai i dati, carica i dati su Amazon S3 e copiali nel tuo data warehouse Amazon Redshift.
-
-
Per il tipo di crittografia, scegli una delle seguenti opzioni:
-
NESSUNA: disattiva la crittografia dei dati per l'intero processo di migrazione dei dati.
-
CSE_SK: utilizza la crittografia lato client con una chiave simmetrica per migrare i dati. AWS SCT genera automaticamente chiavi di crittografia e le trasmette agli agenti di estrazione dei dati utilizzando Secure Sockets Layer (SSL). AWS SCT non crittografa oggetti di grandi dimensioni (LOBs) durante la migrazione dei dati.
-
-
Scegliete Extract LOBs per estrarre oggetti di grandi dimensioni. Se non è necessario estrarre gli oggetti di grandi dimensioni, è possibile deselezionare la casella di controllo. In questo modo è possibile ridurre la quantità di dati estratti.
-
Per visualizzare informazioni dettagliate su un'attività, scegli Abilita la registrazione delle attività. Puoi utilizzare i log dell'attività per il debug dei problemi.
Se abiliti il log delle attività, scegli il livello di dettaglio che desideri visualizzare. I livelli sono i seguenti, con ogni livello che include tutti i messaggi del livello precedente:
ERROR— La minima quantità di dettagli.WARNINGINFODEBUGTRACE— La massima quantità di dettagli.
-
Per esportare i dati da BigQuery, AWS SCT utilizza la cartella bucket di Google Cloud Storage. In questa cartella, gli agenti di estrazione dei dati archiviano i dati di origine.
Per inserire il percorso della cartella bucket di Google Cloud Storage, scegli Avanzate. Per la cartella bucket di Google CS, inserisci il nome del bucket e il nome della cartella.
-
Per assumere un ruolo come utente del tuo agente di estrazione dati, scegli le impostazioni di Amazon S3. Per il ruolo IAM, inserisci il nome del ruolo da utilizzare. Per Regione, scegli il ruolo Regione AWS per questo ruolo.
-
Scegli Test task per verificare che sia possibile connettersi alla cartella di lavoro, al bucket Amazon S3 e al data warehouse Amazon Redshift. La verifica dipende dalla modalità di migrazione scelta.
-
Scegli Create (crea) per creare l'attività.
-
Ripeti i passaggi precedenti per creare le attività per tutti i dati che desideri migrare.
Per eseguire e monitorare le attività
-
Per View, scegli Data Migration view. Viene visualizzata la scheda Agents (Agenti).
-
Selezionare la scheda Tasks (Attività). Le tue attività compaiono nella griglia nella parte superiore come illustrato di seguito. Puoi visualizzare lo stato di un'attività nella griglia superiore e lo stato delle sottoattività nella griglia inferiore.
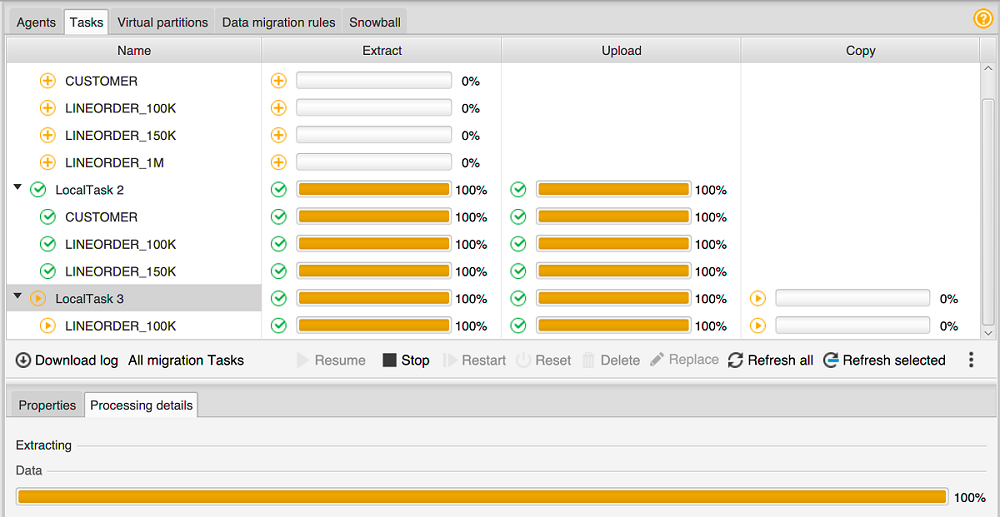
-
Scegli un'attività nella griglia superiore ed espandila. A seconda della modalità di migrazione scelta, vedrai l'attività divisa in Extract (Estrai), Carica e Copy (Copia).
-
Scegliere Start (Avvia) per un'attività per avviarla. Puoi monitorare lo stato delle attività durante il loro lavoro. Le sottoattività vengono eseguite in parallelo. Anche l'estrazione, il caricamento e la copia vengono eseguiti in parallelo.
-
Se hai abilitato la creazione di log quando configuri l'attività, puoi visualizzare i log:
-
Scegli Scarica registro. Viene visualizzato un messaggio con il nome della cartella che contiene i file di log. Elimina il messaggio.
-
Un link viene visualizzato nella scheda Task details (Dettagli dell'attività). Scegli il link per aprire la cartella che contiene i file di log.
-
Puoi chiudere AWS SCT e gli agenti e le attività continueranno a funzionare. Puoi riaprirle in un AWS SCT secondo momento per controllare lo stato delle tue attività e visualizzare i registri delle attività.
È possibile salvare le attività di estrazione dei dati sul disco locale e ripristinarle sullo stesso o su un altro progetto utilizzando l'esportazione e l'importazione. Per esportare un'attività, assicurati di avere almeno un'attività di estrazione creata in un progetto. È possibile importare una singola attività di estrazione o tutte le attività create nel progetto.
Quando esporti un'attività di estrazione, AWS SCT crea un .xml file separato per quell'attività. Il .xml file memorizza le informazioni sui metadati dell'attività, come le proprietà, la descrizione e le sottoattività. Il .xml file non contiene informazioni sull'elaborazione di un'operazione di estrazione. Informazioni come le seguenti vengono ricreate quando l'attività viene importata:
-
Avanzamento dell'attività
-
Sottoattività e stati dello stadio
-
Distribuzione degli agenti di estrazione per sottoattività e fasi
-
Attività e sottoattività IDs
-
Nome attività
Esportazione e importazione di un'attività di estrazione dei dati AWS SCT
È possibile salvare rapidamente un'attività esistente da un progetto e ripristinarla in un altro progetto (o nello stesso progetto) utilizzando l' AWS SCT esportazione e l'importazione. Utilizzate la seguente procedura per esportare e importare le attività di estrazione dei dati.
Per esportare e importare un'attività di estrazione dei dati
-
Per Visualizza, scegli la visualizzazione Data Migration. Viene visualizzata la scheda Agents (Agenti).
-
Selezionare la scheda Tasks (Attività). Le tue attività sono elencate nella griglia visualizzata.
-
Scegli i tre punti allineati verticalmente (icona con i puntini di sospensione) situati nell'angolo in basso a destra sotto l'elenco delle attività.
-
Scegli Esporta attività dal menu pop-up.
-
Scegli la cartella in cui desideri AWS SCT inserire il
.xmlfile di esportazione dell'attività.AWS SCT crea il file di esportazione delle attività con il formato del nome file di
TASK-DESCRIPTION_TASK-ID.xml -
Scegli i tre punti allineati verticalmente (icona con i puntini di sospensione) in basso a destra sotto l'elenco delle attività.
-
Scegli Importa attività dal menu pop-up.
È possibile importare un'attività di estrazione in un progetto collegato al database di origine e il progetto ha almeno un agente di estrazione registrato attivo.
-
Seleziona il
.xmlfile per l'attività di estrazione che hai esportato.AWS SCT ottiene i parametri dell'attività di estrazione dal file, crea l'attività e la aggiunge agli agenti di estrazione.
-
Ripeti questi passaggi per esportare e importare altre attività di estrazione dei dati.
Al termine di questo processo, l'esportazione e l'importazione sono complete e le attività di estrazione dei dati sono pronte per l'uso.
Estrazione dei dati tramite un dispositivo AWS Snowball Edge Edge
Il processo di utilizzo AWS SCT di AWS Snowball Edge Edge prevede diversi passaggi. La migrazione prevede un'attività locale, in cui AWS SCT utilizza un agente di estrazione dei dati per spostare i dati sul dispositivo AWS Snowball Edge Edge, quindi un'azione intermedia in cui AWS copia i dati dal dispositivo AWS Snowball Edge Edge a un bucket Amazon S3. Il processo termina il AWS SCT caricamento dei dati dal bucket Amazon S3 su Amazon Redshift.
Le sezioni che seguono questa panoramica forniscono una step-by-step guida per ciascuna di queste attività. La procedura presuppone che sia stato AWS SCT installato e configurato e registrato un agente di estrazione dati su un computer dedicato.
Esegui i passaggi seguenti per migrare i dati da un data store locale a un AWS data store utilizzando AWS Snowball Edge Edge.
Crea un job AWS Snowball Edge Edge utilizzando la AWS Snowball Edge console.
Sblocca il dispositivo AWS Snowball Edge Edge utilizzando il computer Linux locale dedicato.
Crea un nuovo progetto in AWS SCT.
Installa e configura i tuoi agenti di estrazione dei dati.
Crea e imposta le autorizzazioni per il bucket Amazon S3 da utilizzare.
Importa un AWS Snowball Edge lavoro nel tuo AWS SCT progetto.
Registra il tuo agente di estrazione dati in AWS SCT.
Crea un'attività locale in AWS SCT.
Esegui e monitora l'attività di migrazione dei dati in AWS SCT.
Step-by-step procedure per la migrazione dei dati utilizzando AWS SCT and AWS Snowball Edge Edge
Le sezioni seguenti forniscono informazioni dettagliate sulle fasi della migrazione.
Passaggio 1: creare un lavoro AWS Snowball Edge Edge
Crea un AWS Snowball Edge lavoro seguendo i passaggi descritti nella sezione Creating an AWS Snowball Edge Edge Job nella AWS Snowball Edge Edge Developer Guide.
Passaggio 2: sblocca il dispositivo AWS Snowball Edge Edge
Esegui i comandi che sbloccano e forniscono le credenziali al dispositivo Snowball Edge Edge dal computer su cui hai installato AWS DMS l'agente. Eseguendo questi comandi, puoi essere certo che la chiamata dell' AWS DMS agente si connetta al dispositivo AWS Snowball Edge Edge. Per ulteriori informazioni sullo sblocco del dispositivo AWS Snowball Edge Edge, consulta Sblocco di Snowball Edge.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
Fase 3: Creare un nuovo progetto AWS SCT
Quindi, crea un nuovo AWS SCT progetto.
Per creare un nuovo progetto in AWS SCT
-
Avvia il AWS Schema Conversion Tool. Nel menu File, scegli Nuovo progetto. Viene visualizzata la finestra di dialogo Nuovo progetto.
-
Immetti un nome per il progetto, che è memorizzato localmente nel computer.
-
Immetti l'ubicazione del file del progetto locale.
-
Scegliete OK per creare il AWS SCT progetto.
-
Scegli Aggiungi sorgente per aggiungere un nuovo database di origine al tuo AWS SCT progetto.
-
Scegli Aggiungi destinazione per aggiungere una nuova piattaforma di destinazione al tuo AWS SCT progetto.
-
Scegli lo schema del database di origine nel pannello di sinistra.
-
Nel pannello di destra, specifica la piattaforma di database di destinazione per lo schema di origine selezionato.
-
Scegli Crea mappatura. Questo pulsante diventa attivo dopo aver scelto lo schema del database di origine e la piattaforma di database di destinazione.
Passaggio 4: installa e configura l'agente di estrazione dei dati
AWS SCT utilizza un agente di estrazione dati per migrare i dati su Amazon Redshift. Il file.zip che hai scaricato per l'installazione include il file di installazione AWS SCT dell'agente di estrazione. È possibile installare l'agente di estrazione dei dati in Windows, Red Hat Enterprise Linux o Ubuntu. Per ulteriori informazioni, consulta Installazione degli agenti di estrazione.
Per configurare l'agente di estrazione dei dati, inserisci i motori di database di origine e di destinazione. Inoltre, assicurati di aver scaricato i driver JDBC per i database di origine e di destinazione sul computer su cui esegui l'agente di estrazione dati. Gli agenti di estrazione dei dati utilizzano questi driver per connettersi ai database di origine e di destinazione. Per ulteriori informazioni, consulta Installazione dei driver JDBC per AWS Schema Conversion Tool.
In Windows, il programma di installazione dell'agente di estrazione dati avvia la procedura guidata di configurazione nella finestra del prompt dei comandi. In Linux, esegui il sct-extractor-setup.sh file dalla posizione in cui hai installato l'agente.
Fase 5: Configurazione AWS SCT per accedere al bucket Amazon S3
Per informazioni sulla configurazione di un bucket Amazon S3, consulta la panoramica dei bucket nella Guida per l'utente di Amazon Simple Storage Service.
Fase 6: Importa un AWS Snowball Edge lavoro nel tuo progetto AWS SCT
Per connettere il AWS SCT progetto al dispositivo AWS Snowball Edge Edge, importa il AWS Snowball Edge lavoro.
Per importare il tuo AWS Snowball Edge lavoro
-
Apri il menu Impostazioni, quindi scegli Impostazioni globali. Si aprirà la finestra di dialogo Global Settings (Impostazioni globali).
-
Scegli i profili di AWS servizio, quindi scegli Importa lavoro.
Scegli il tuo AWS Snowball Edge lavoro.
-
Inserisci il tuo AWS Snowball Edge IP. Per ulteriori informazioni, consulta Modifica dell'indirizzo IP nella Guida AWS Snowball Edge per l'utente.
-
Inserisci la tua AWS Snowball Edge porta. Per ulteriori informazioni, consulta Porte necessarie per utilizzare AWS i servizi su un dispositivo AWS Snowball Edge Edge nella AWS Snowball Edge Edge Developer Guide.
-
Inserisci la chiave di AWS Snowball Edge accesso e la chiave AWS Snowball Edge segreta. Per ulteriori informazioni, consulta la sezione Autorizzazione e controllo degli accessi AWS Snowball Edge nella Guida AWS Snowball Edge per l'utente.
Scegli Apply (Applica), quindi OK.
Passaggio 7: Registrare un agente di estrazione dati in AWS SCT
In questa sezione, si registra l'agente di estrazione dati in AWS SCT.
Per registrare un agente di estrazione dati
-
Nel menu Visualizza, scegli Visualizzazione di migrazione dei dati (altro), quindi scegli Registra.
-
Per Descrizione, inserisci un nome per l'agente di estrazione dei dati.
-
Per Nome host, inserisci l'indirizzo IP del computer su cui viene eseguito l'agente di estrazione dati.
-
Per Porta, inserisci la porta di ascolto che hai configurato.
-
Scegli Registrati.
Fase 8: Creazione di un'attività locale
Successivamente, crei l'attività di migrazione. che include due attività secondarie: Una sottoattività consente di migrare i dati dal database di origine all'appliance AWS Snowball Edge Edge. L'altra attività secondaria acquisisce i dati caricati dall'appliance in un bucket Amazon S3 e ne esegue la migrazione nel database di destinazione.
Per creare l'attività di migrazione
-
Nel menu Visualizza, quindi scegli Data migration view (altro).
Nel pannello a sinistra, in cui viene visualizzato lo schema del database di origine, scegli un oggetto dello schema per il quale eseguire la migrazione. Apri il menu contestuale (fai clic con il pulsante destro del mouse) per l'oggetto, quindi scegli Crea attività locale.
-
In Nome attività, inserisci un nome descrittivo per l'attività di migrazione dei dati.
-
Per la modalità di migrazione, scegli Estrai, carica e copia.
-
Scegli le impostazioni di Amazon S3.
-
Seleziona Usa Snowball Edge.
-
Inserisci cartelle e sottocartelle nel tuo bucket Amazon S3 in cui l'agente di estrazione dati può archiviare i dati.
-
Scegli Create (crea) per creare l'attività.
Fase 9: Esecuzione e monitoraggio dell'attività di migrazione dei dati in AWS SCT
Per iniziare l'attività di migrazione dei dati, scegli Avvia. Assicurati di aver stabilito connessioni al database di origine, al bucket Amazon S3, al AWS Snowball Edge dispositivo e alla connessione al database di destinazione su. AWS
Puoi monitorare e gestire le attività di migrazione dei dati e le relative sottoattività nella scheda Attività. È possibile visualizzare l'avanzamento della migrazione dei dati, nonché sospendere o riavviare le attività di migrazione dei dati.
Output dell'attività di estrazione dei dati
Dopo il completamento delle attività di migrazione, i tuoi dati sono pronti. Utilizza le informazioni riportate di seguito per determinare come procedere in base alla modalità di migrazione scelta e alla posizione dei dati.
| Modalità di migrazione | Ubicazione dei dati |
|---|---|
|
Estrai, carica e copia |
I dati sono già presenti nel tuo data warehouse Amazon Redshift. Puoi verificare che i dati siano presenti e iniziare a utilizzarli. Per ulteriori informazioni, consulta Connessione ai cluster da strumenti e codice client. |
|
Estrai e carica |
Gli agenti di estrazione hanno salvato i dati come file nel bucket Amazon S3. Puoi utilizzare il comando Amazon Redshift COPY per caricare i dati su Amazon Redshift. Per ulteriori informazioni, consulta Caricamento di dati da Amazon S3 nella documentazione di Amazon Redshift. Nel bucket Amazon S3 sono presenti più cartelle, corrispondenti alle attività di estrazione che hai impostato. Quando carichi i dati su Amazon Redshift, specifica il nome del file manifest creato da ciascuna attività. Il file manifest viene visualizzato nella cartella delle attività del bucket Amazon S3 come illustrato di seguito. 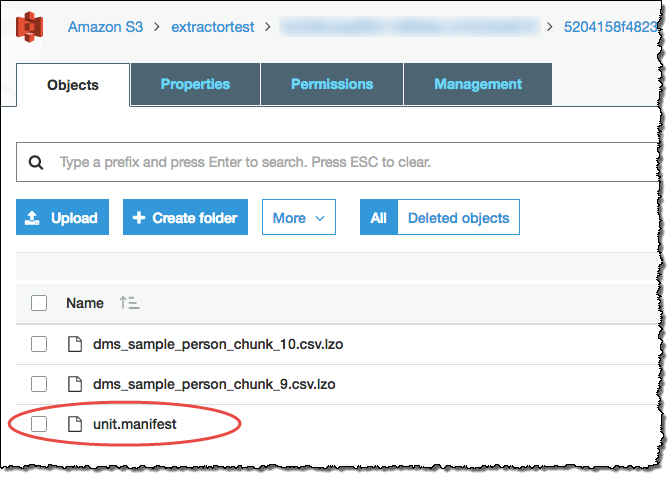
|
|
Estrai solo |
Gli agenti di estrazione hanno salvato i dati come file nella tua cartella di lavoro. Copia manualmente i dati nel bucket Amazon S3, quindi procedi con le istruzioni per l'estrazione e il caricamento. |
Utilizzo del partizionamento virtuale con AWS Schema Conversion Tool
Puoi gestire tabelle non partizionate di grandi dimensioni creando sottoattività che generano partizioni virtuali dei dati della tabella utilizzando le regole di filtro. In AWS SCT, puoi creare partizioni virtuali per i tuoi dati migrati. Esistono tre tipi di partizione, che funzionano con determinati tipi di dati:
Il tipo di partizione RANGE funziona con tipi di dati numerici e relativi a data e ora.
Il tipo di partizione LIST funziona con tipi di dati numerici, di carattere e relativi a data e ora.
Il tipo di partizione DATE AUTO SPLIT funziona con tipi di dati numerici, di data e ora.
AWS SCT convalida i valori forniti per la creazione di una partizione. Ad esempio, se si tenta di partizionare una colonna con il tipo di dati NUMERIC ma si forniscono valori di un tipo di dati diverso, AWS SCT genera un errore.
Inoltre, se utilizzi AWS SCT per migrare i dati su Amazon Redshift, puoi utilizzare il partizionamento nativo per gestire la migrazione di tabelle di grandi dimensioni. Per ulteriori informazioni, consulta Utilizzo del partizionamento nativo.
Limiti durante la creazione di partizionamenti virtuali
Queste sono limitazioni per la creazione di una partizione virtuale:
Puoi utilizzare il partizionamento virtuale solo per le tabelle non partizionate.
Puoi usare il partizionamento virtuale solo nella vista della migrazione dei dati.
Non puoi utilizzare l'opzione UNION ALL VIEW con il partizionamento virtuale.
Tipo di partizione RANGE
Il tipo di partizione RANGE suddivide i dati in base a una gamma di valori di colonna per i tipi di dati numerici e relativi a data e ora. Questo tipo di partizione crea una clausola WHERE e tu fornisci l'intervallo di valori per ogni partizione. Per specificare un elenco di valori per la colonna partizionata, utilizzate la casella Valori. Puoi caricare le informazioni sul valore utilizzando un file csv.
Il tipo di partizione RANGE crea partizioni predefinite a entrambe le estremità dei valori della partizione. Queste partizioni predefinite catturano tutti i dati inferiori o superiori ai valori di partizione specificati.
Ad esempio, è possibile creare più partizioni in base a un intervallo di valori fornito dall'utente. In questo esempio, i valori del partizionamento LO_TAX sono specificati per creare più partizioni.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
Per creare una partizione virtuale RANGE
Aprire AWS SCT.
Scegli la modalità di visualizzazione Data Migration (altro).
Scegliere la tabella in cui desideri impostare il partizionamento virtuale. Apri il menu contestuale (fai clic con il pulsante destro del mouse) per la tabella e scegli Aggiungi partizionamento virtuale.
Nella finestra di dialogo Aggiungi partizionamento virtuale, immettete le informazioni come segue.
Opzione Azione Tipo di partizione
Scegli RANGE. L'interfaccia utente della finestra di dialogo cambia a seconda del tipo scelto.
Nome della colonna
Scegli la colonna su cui desideri effettuare la partizione.
Tipo di colonna
Scegli il tipo di dati per i valori nella colonna.
Valori
Aggiungere nuovi valori digitando ogni valore nella casella New Value (Nuovo valore), quindi scegliendo il segno più per aggiungere il valore.
Carica da file
(Facoltativo) Immetti il nome di un file.csv che contiene i valori della partizione.
-
Scegli OK.
Tipo di partizione LIST
Il tipo di partizione LIST suddivide i dati in base ai valori di colonna per i tipi di dati numerici, di carattere e relativi a data e ora. Questo tipo di partizione crea una clausola WHERE e tu fornisci i valori per ogni partizione. Per specificare un elenco di valori per la colonna partizionata, utilizzate la casella Valori. Puoi caricare le informazioni sul valore utilizzando un file csv.
Ad esempio, puoi creare più partizioni in base a un valore fornito. In questo esempio, i valori del partizionamento LO_ORDERKEY sono specificati per creare più partizioni.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
Puoi anche creare una partizione di default per i valori non inclusi in quelli specificati.
È possibile utilizzare il tipo di partizione LIST per filtrare i dati di origine se si desidera escludere valori particolari dalla migrazione. Ad esempio, supponiamo di voler omettere le righe con. LO_ORDERKEY = 4 In questo caso, non includete il valore 4 nell'elenco dei valori di partizione e assicuratevi che l'opzione Includi altri valori non sia selezionata.
Per creare una partizione virtuale LIST
Apri AWS SCT.
Scegli la modalità di visualizzazione Data Migration (altro).
Scegliere la tabella in cui desideri impostare il partizionamento virtuale. Apri il menu contestuale (fai clic con il pulsante destro del mouse) per la tabella e scegli Aggiungi partizionamento virtuale.
Nella finestra di dialogo Aggiungi partizionamento virtuale, immettete le informazioni come segue.
Opzione Azione Tipo di partizione
Scegli LIST. L'interfaccia utente della finestra di dialogo cambia a seconda del tipo scelto.
Nome della colonna
Scegli la colonna su cui desideri effettuare la partizione.
Nuovo valore
Digita un valore qui per aggiungerlo al set di valori di partizionamento.
Includi altri valori
Scegli questa opzione per creare una partizione di default in cui tutti i valori che non soddisfano i criteri di partizionamento vengono archiviati.
Carica da file
(Facoltativo) Immetti il nome di un file.csv che contiene i valori della partizione.
Scegli OK.
Tipo di partizione DATE AUTO SPLIT
Il tipo di partizione DATE AUTO SPLIT è un modo automatico per generare partizioni RANGE. Con DATA AUTO SPLIT, si indica AWS SCT all'attributo di partizionamento, dove iniziare e finire e la dimensione dell'intervallo tra i valori. Quindi AWS SCT calcola automaticamente i valori delle partizioni.
DATA AUTO SPLIT automatizza gran parte del lavoro relativo alla creazione di partizioni di intervallo. Il compromesso tra l'utilizzo di questa tecnica e il partizionamento a intervalli è il controllo necessario sui limiti delle partizioni. Il processo di suddivisione automatica crea sempre intervalli di dimensioni uguali (uniformi). Il partizionamento degli intervalli consente di variare le dimensioni di ciascun intervallo in base alle esigenze di una particolare distribuzione dei dati. Ad esempio, è possibile utilizzare giornalmente, settimanalmente, bisettimanalmente, mensilmente e così via.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
Per creare una partizione virtuale DATE AUTO SPLIT
Aperta AWS SCT.
Scegli la modalità di visualizzazione Data Migration (altro).
Scegliere la tabella in cui desideri impostare il partizionamento virtuale. Apri il menu contestuale (fai clic con il pulsante destro del mouse) per la tabella e scegli Aggiungi partizionamento virtuale.
Nella finestra di dialogo Aggiungi partizionamento virtuale, immettete le informazioni come segue.
Opzione Azione Tipo di partizione
Scegliere DATE AUTO SPLIT. L'interfaccia utente della finestra di dialogo cambia a seconda del tipo scelto.
Nome della colonna
Scegli la colonna su cui desideri effettuare la partizione.
Data di inizio
Digitare una data di inizio.
Data di fine
Digitare una data di fine.
Interval (Intervallo)
Immetti l'unità dell'intervallo e scegli il valore per quell'unità.
Scegli OK.
Utilizzo del partizionamento nativo
Per accelerare la migrazione dei dati, gli agenti di estrazione dei dati possono utilizzare partizioni native di tabelle sul server del data warehouse di origine. AWS SCT supporta il partizionamento nativo per le migrazioni da Greenplum, Netezza e Oracle ad Amazon Redshift.
Ad esempio, dopo aver creato un progetto, è possibile raccogliere statistiche su uno schema e analizzare le dimensioni delle tabelle selezionate per la migrazione. Per le tabelle che superano la dimensione specificata, AWS SCT attiva il meccanismo di partizionamento nativo.
Per utilizzare il partizionamento nativo
-
Apri AWS SCT e scegli Nuovo progetto per File. Viene visualizzata la finestra di dialogo Nuovo progetto.
-
Crea un nuovo progetto, aggiungi i server di origine e di destinazione e crea regole di mappatura. Per ulteriori informazioni, consulta Avvio e gestione di progetti in AWS SCT.
-
Scegliete Visualizza, quindi scegliete Visualizzazione principale.
-
Per le impostazioni del progetto, scegli la scheda Migrazione dei dati. Scegli Usa il partizionamento automatico. Per i database di origine Greenplum e Netezza, inserisci la dimensione minima delle tabelle supportate in megabyte (ad esempio, 100). AWS SCT crea automaticamente sottoattività di migrazione separate per ogni partizione nativa che non sia vuota. Per le migrazioni da Oracle ad Amazon Redshift, AWS SCT crea sottoattività per tutte le tabelle partizionate.
-
Nel pannello di sinistra che mostra lo schema dal database di origine, scegli uno schema. Apri il menu contestuale (fai clic con il pulsante destro del mouse) per l'oggetto e scegli Raccogli statistiche. Per la migrazione dei dati da Oracle ad Amazon Redshift, puoi saltare questo passaggio.
-
Scegli tutte le tabelle da migrare.
-
Registra il numero richiesto di agenti. Per ulteriori informazioni, consulta Registrazione degli agenti di estrazione con AWS Schema Conversion Tool.
-
Crea un'attività di estrazione dei dati per le tabelle selezionate. Per ulteriori informazioni, consulta Creazione, esecuzione e monitoraggio di un'attività di estrazione dei dati AWS SCT.
Controlla se le tabelle di grandi dimensioni sono suddivise in sottoattività e che ciascuna sottoattività corrisponda al set di dati che presenta una parte della tabella situata su una sezione del data warehouse di origine.
-
Avvia e monitora il processo di migrazione fino a quando gli agenti di estrazione AWS SCT dei dati non completano la migrazione dei dati dalle tabelle di origine.
Migrazione LOBs ad Amazon Redshift
Amazon Redshift non supporta la memorizzazione di oggetti binari di grandi dimensioni ()LOBs. Tuttavia, se devi migrarne uno o più LOBs verso Amazon Redshift AWS SCT , puoi eseguire la migrazione. A tale scopo, AWS SCT utilizza un bucket Amazon S3 per archiviare LOBs e scrive l'URL del bucket Amazon S3 nei dati migrati archiviati in Amazon Redshift.
Per migrare LOBs ad Amazon Redshift
Aprire un progetto AWS SCT .
Esegui la connessione ai database di origine e di destinazione. Aggiorna i metadati dal database di destinazione e assicurati che le tabelle convertite esistano lì.
Per Azioni, scegli Crea attività locale.
-
Per la modalità di migrazione, scegli una delle seguenti opzioni:
-
Estrai e carica per estrarre i tuoi dati e carica i tuoi dati su Amazon S3.
-
Estrai, carica e copia per estrarre i tuoi dati, carica i dati su Amazon S3 e copiali nel tuo data warehouse Amazon Redshift.
-
Scegli le impostazioni di Amazon S3.
Per la LOBs cartella bucket Amazon S3, inserisci il nome della cartella in un bucket Amazon S3 in cui desideri archiviarla. LOBs
Se utilizzi il profilo di AWS servizio, questo campo è facoltativo. AWS SCT puoi utilizzare le impostazioni predefinite del tuo profilo. Per utilizzare un altro bucket Amazon S3, inserisci il percorso qui.
-
Attiva l'opzione Usa proxy per utilizzare un server proxy per caricare dati su Amazon S3. Quindi scegli il protocollo di trasferimento dati, inserisci il nome host, la porta, il nome utente e la password.
-
Per il tipo di endpoint, scegli FIPS per utilizzare l'endpoint FIPS (Federal Information Processing Standard). Scegli VPCE per utilizzare l'endpoint del cloud privato virtuale (VPC). Quindi, per l'endpoint VPC, inserisci il Domain Name System (DNS) del tuo endpoint VPC.
-
Attiva l'opzione Keep files on Amazon S3 dopo averli copiati su Amazon Redshift per conservare i file estratti su Amazon S3 dopo averli copiati su Amazon Redshift.
Scegli Create (crea) per creare l'attività.
Migliori pratiche e risoluzione dei problemi per gli agenti di estrazione dei dati
Di seguito sono elencati alcuni suggerimenti per la risoluzione dei problemi e best practice per l'utilizzo degli agenti di estrazione.
| Problema | Suggerimenti sulla risoluzione dei problemi |
|---|---|
|
Le prestazioni sono lente |
Per migliorare le prestazioni, ti consigliamo di attenerti alle seguenti indicazioni:
|
|
Ritardi dovuti a conflitti |
Evita la presenza di troppi agenti che accedono al tuo data warehouse nello stesso momento. |
|
Un agente non è temporaneamente disponibile |
Se un agente non è disponibile, lo stato di ogni sua attività viene visualizzato come non riuscito in AWS SCT. Se attendi, in alcuni casi l'agente è in grado di tornare disponibile. In questo caso, lo stato delle sue attività si aggiorna in AWS SCT. |
|
Un agente non è disponibile in modo permanente |
Se il computer che esegue un agente diventa non disponibile in modo permanente e tale agente sta eseguendo un'attività, puoi sostituirlo con un nuovo agente per continuare l'attività. Puoi sostituire un nuovo agente solo se la cartella di lavoro dell'agente originale non era nello stesso computer dell'agente originale. Per sostituire un nuovo agente, esegui le operazioni indicate di seguito:
|
