Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione dei carichi di lavoro Hadoop su Amazon EMR con AWS Schema Conversion Tool
Per migrare i cluster Apache Hadoop, assicurati di utilizzare la versione 1.0.670 o successiva. AWS SCT Inoltre, acquisisci familiarità con l'interfaccia a riga di comando (CLI) di. AWS SCT Per ulteriori informazioni, consulta Riferimento CLI per AWS Schema Conversion Tool.
Panoramica sulla migrazione
L'immagine seguente mostra il diagramma dell'architettura della migrazione da Apache Hadoop ad Amazon EMR.
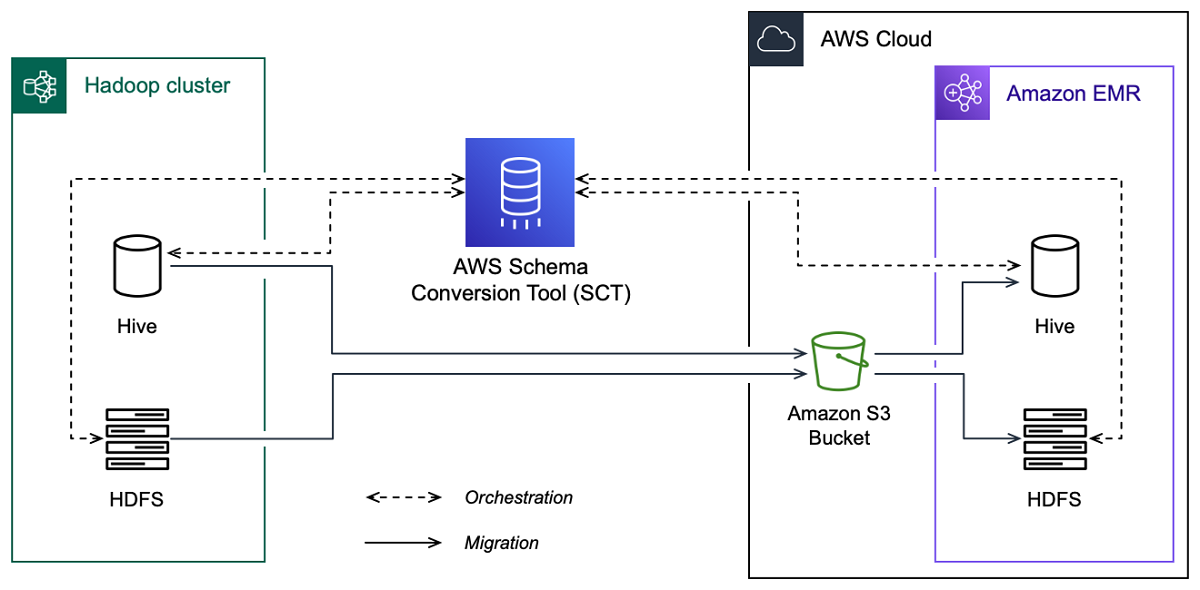
AWS SCT migra dati e metadati dal cluster Hadoop di origine a un bucket Amazon S3. Successivamente, AWS SCT utilizza i metadati Hive di origine per creare oggetti di database nel servizio Amazon EMR Hive di destinazione. Facoltativamente, puoi configurare Hive per utilizzarlo come metastore. AWS Glue Data Catalog In questo caso, AWS SCT migra i metadati Hive di origine in. AWS Glue Data Catalog
Quindi, puoi utilizzarli AWS SCT per migrare i dati da un bucket Amazon S3 al servizio Amazon EMR HDFS di destinazione. In alternativa, puoi lasciare i dati nel tuo bucket Amazon S3 e utilizzarli come repository di dati per i tuoi carichi di lavoro Hadoop.
Per avviare la migrazione di Hapood, devi creare ed eseguire lo script AWS SCT CLI. Questo script include il set completo di comandi per eseguire la migrazione. È possibile scaricare e modificare un modello dello script di migrazione Hadoop. Per ulteriori informazioni, consulta Ottenere scenari CLI.
Assicurati che lo script includa i seguenti passaggi in modo da poter eseguire la migrazione da Apache Hadoop ad Amazon S3 e Amazon EMR.
Passaggio 1: Connect ai cluster Hadoop
Per iniziare la migrazione del tuo cluster Apache Hadoop, crea un nuovo progetto. AWS SCT Successivamente, connettiti ai cluster di origine e di destinazione. Assicurati di creare e fornire AWS le risorse di destinazione prima di iniziare la migrazione.
In questo passaggio, si utilizzano i seguenti comandi AWS SCT CLI.
CreateProject— per creare un nuovo AWS SCT progetto.AddSourceCluster— per connettersi al cluster Hadoop di origine del progetto. AWS SCTAddSourceClusterHive— per connettersi al servizio Hive di origine del progetto.AddSourceClusterHDFS— per connettersi al servizio HDFS di origine del progetto.AddTargetCluster— per connetterti al cluster Amazon EMR di destinazione del tuo progetto.AddTargetClusterS3— per aggiungere il bucket Amazon S3 al tuo progetto.AddTargetClusterHive— per connetterti al servizio Hive di destinazione del tuo progettoAddTargetClusterHDFS— per connettersi al servizio HDFS di destinazione del progetto
Per esempi di utilizzo di questi comandi AWS SCT CLI, vedere. Connessione ad Apache Hadoop
Quando esegui il comando che si connette a un cluster di origine o di destinazione, AWS SCT tenta di stabilire la connessione a questo cluster. Se il tentativo di connessione fallisce, AWS SCT interrompe l'esecuzione dei comandi dallo script CLI e visualizza un messaggio di errore.
Fase 2: Impostare le regole di mappatura
Dopo esserti connesso ai cluster di origine e di destinazione, configura le regole di mappatura. Una regola di mappatura definisce l'obiettivo di migrazione per un cluster di origine. Assicurati di impostare le regole di mappatura per tutti i cluster di origine che hai aggiunto al progetto. AWS SCT Per ulteriori informazioni sulle regole di mappatura, consulta. Mappatura dei tipi di dati in AWS Schema Conversion Tool
In questo passaggio, si utilizza il AddServerMapping comando. Questo comando utilizza due parametri che definiscono i cluster di origine e di destinazione. È possibile utilizzare il AddServerMapping comando con il percorso esplicito degli oggetti del database o con i nomi di un oggetto. Come prima opzione, includi il tipo di oggetto e il suo nome. Per la seconda opzione, includete solo i nomi degli oggetti.
-
sourceTreePath— il percorso esplicito degli oggetti del database di origine.targetTreePath— il percorso esplicito degli oggetti del database di destinazione. -
sourceNamePath— il percorso che include solo i nomi degli oggetti di origine.targetNamePath— il percorso che include solo i nomi degli oggetti di destinazione.
Il seguente esempio di codice crea una regola di mappatura utilizzando percorsi espliciti per il database testdb Hive di origine e il cluster EMR di destinazione.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
È possibile utilizzare questo esempio e gli esempi seguenti in Windows. Per eseguire i comandi CLI in Linux, assicurati di aver aggiornato i percorsi dei file in modo appropriato per il tuo sistema operativo.
Il seguente esempio di codice crea una regola di mappatura utilizzando i percorsi che includono solo i nomi degli oggetti.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Puoi scegliere Amazon EMR o Amazon S3 come destinazione per il tuo oggetto di origine. Per ogni oggetto sorgente, puoi scegliere solo una destinazione in un singolo AWS SCT progetto. Per modificare la destinazione di migrazione per un oggetto di origine, eliminate la regola di mappatura esistente e quindi create una nuova regola di mappatura. Per eliminare una regola di mappatura, utilizzare il comando. DeleteServerMapping Questo comando utilizza uno dei due parametri seguenti.
sourceTreePath— il percorso esplicito degli oggetti del database di origine.sourceNamePath— il percorso che include solo i nomi degli oggetti di origine.
Per ulteriori informazioni sui DeleteServerMapping comandi AddServerMapping and, consulta la AWS Schema Conversion Tool CLI Reference
Fase 3: Creare un rapporto di valutazione
Prima di iniziare la migrazione, ti consigliamo di creare un rapporto di valutazione. Questo rapporto riassume tutte le attività di migrazione e descrive in dettaglio le azioni che emergeranno durante la migrazione. Per assicurarti che la migrazione non vada a buon fine, visualizza questo rapporto e risolvi le azioni da intraprendere prima della migrazione. Per ulteriori informazioni, consulta Report di valutazione.
In questo passaggio, si utilizza il CreateMigrationReport comando. Questo comando utilizza due parametri. Il treePath parametro è obbligatorio e il forceMigrate parametro è facoltativo.
treePath— il percorso esplicito degli oggetti del database di origine per i quali si salva una copia del rapporto di valutazione.forceMigrate— se impostato sutrue, AWS SCT continua la migrazione anche se il progetto include una cartella HDFS e una tabella Hive che fanno riferimento allo stesso oggetto. Il valore predefinito èfalse.
È quindi possibile salvare una copia del rapporto di valutazione come file PDF o file con valori separati da virgole (CSV). A tale scopo, utilizzate il comando or. SaveReportPDF SaveReportCSV
Il SaveReportPDF comando salva una copia del rapporto di valutazione come file PDF. Questo comando utilizza quattro parametri. Il file parametro è obbligatorio, gli altri parametri sono opzionali.
file— il percorso del file PDF e il suo nome.filter— il nome del filtro creato in precedenza per definire l'ambito degli oggetti di origine da migrare.treePath— il percorso esplicito degli oggetti del database di origine per i quali salvate una copia del rapporto di valutazione.namePath— il percorso che include solo i nomi degli oggetti di destinazione per i quali si salva una copia del rapporto di valutazione.
Il SaveReportCSV comando salva il rapporto di valutazione in tre file CSV. Questo comando utilizza quattro parametri. Il directory parametro è obbligatorio, gli altri parametri sono opzionali.
directory— il percorso della cartella in cui vengono AWS SCT salvati i file CSV.filter— il nome del filtro creato in precedenza per definire l'ambito degli oggetti di origine da migrare.treePath— il percorso esplicito degli oggetti del database di origine per i quali salvate una copia del rapporto di valutazione.namePath— il percorso che include solo i nomi degli oggetti di destinazione per i quali si salva una copia del rapporto di valutazione.
Il seguente esempio di codice salva una copia del rapporto di valutazione nel c:\sct\ar.pdf file.
SaveReportPDF -file:'c:\sct\ar.pdf' /
Il seguente esempio di codice salva una copia del rapporto di valutazione come file CSV nella c:\sct cartella.
SaveReportCSV -file:'c:\sct' /
Per ulteriori informazioni sui SaveReportCSV comandi SaveReportPDF and, consulta la AWS Schema Conversion Tool CLI Reference
Fase 4: Esegui la migrazione del cluster Apache Hadoop su Amazon EMR con AWS SCT
Dopo aver configurato il AWS SCT progetto, avvia la migrazione del cluster Apache Hadoop locale verso. Cloud AWS
In questo passaggio, si utilizzano i comandiMigrate, MigrationStatus e. ResumeMigration
Il Migrate comando migra gli oggetti di origine nel cluster di destinazione. Questo comando utilizza quattro parametri. Assicurati di specificare il treePath parametro filter o. Gli altri parametri sono opzionali.
filter— il nome del filtro creato in precedenza per definire l'ambito degli oggetti di origine da migrare.treePath— il percorso esplicito degli oggetti del database di origine per i quali salvate una copia del rapporto di valutazione.forceLoad— se impostato sutrue, carica AWS SCT automaticamente gli alberi di metadati del database durante la migrazione. Il valore predefinito èfalse.forceMigrate— se impostato sutrue, AWS SCT continua la migrazione anche se il progetto include una cartella HDFS e una tabella Hive che fanno riferimento allo stesso oggetto. Il valore predefinito èfalse.
Il MigrationStatus comando restituisce le informazioni sull'avanzamento della migrazione. Per eseguire questo comando, inserisci il nome del tuo progetto di migrazione per il name parametro. Hai specificato questo nome nel CreateProject comando.
Il ResumeMigration comando riprende la migrazione interrotta avviata utilizzando il comando. Migrate Il ResumeMigration comando non utilizza parametri. Per riprendere la migrazione, è necessario connettersi ai cluster di origine e di destinazione. Per ulteriori informazioni, consulta Gestione del progetto di migrazione.
Il seguente esempio di codice migra i dati dal servizio HDFS di origine ad Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Esecuzione dello script CLI
Dopo aver finito di modificare lo script AWS SCT CLI, salvalo come file con estensione. .scts Ora puoi eseguire lo script dalla app cartella del percorso di AWS SCT installazione. A tale scopo, utilizzare il comando seguente.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
Nell'esempio precedente, sostituite script_path con il percorso del file con lo script CLI. Per ulteriori informazioni sull'esecuzione degli script CLI in AWS SCT, vedere. Modalità script
Gestione del progetto di migrazione dei Big Data
Dopo aver completato la migrazione, puoi salvare e modificare il tuo AWS SCT progetto per usi futuri.
Per salvare il AWS SCT progetto, usa il SaveProject comando. Questo comando non utilizza parametri.
Il seguente esempio di codice salva il AWS SCT progetto.
SaveProject /
Per aprire il AWS SCT progetto, usa il OpenProject comando. Questo comando utilizza un parametro obbligatorio. Per il file parametro, inserite il percorso del file di AWS SCT progetto e il relativo nome. Avete specificato il nome del progetto nel CreateProject comando. Assicurati di aggiungere l'.sctsestensione al nome del file di progetto per eseguire il OpenProject comando.
Il seguente esempio di codice apre il hadoop_emr progetto dalla c:\sct cartella.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Dopo aver aperto il AWS SCT progetto, non è necessario aggiungere i cluster di origine e di destinazione perché li avete già aggiunti al progetto. Per iniziare a lavorare con i cluster di origine e di destinazione, devi connetterti ad essi. A tale scopo, si utilizzano i ConnectTargetCluster comandi ConnectSourceCluster and. Questi comandi utilizzano gli stessi parametri dei AddTargetCluster comandi AddSourceCluster and. Puoi modificare lo script CLI e sostituire il nome di questi comandi lasciando l'elenco dei parametri senza modifiche.
Il seguente esempio di codice si connette al cluster Hadoop di origine.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
Il seguente esempio di codice si connette al cluster Amazon EMR di destinazione.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
Nell'esempio precedente, sostituiscilo hadoop_address con l'indirizzo IP del tuo cluster Hadoop. Se necessario, configura il valore della variabile di porta. Quindi, sostituisci hadoop_user e hadoop_password con il nome del tuo utente Hadoop e la password per questo utente. Ad esempiopath\name, inserisci il nome e il percorso del file PEM per il tuo cluster Hadoop di origine. Per ulteriori informazioni sull'aggiunta dei cluster di origine e di destinazione, consulta. Connessione ai database Apache Hadoop con AWS Schema Conversion Tool
Dopo esserti connesso ai cluster Hadoop di origine e di destinazione, devi connetterti ai servizi Hive e HDFS, nonché al tuo bucket Amazon S3. A tale scopo, si utilizzano i comandi,,, eConnectSourceClusterHive. ConnectSourceClusterHdfs ConnectTargetClusterHive ConnectTargetClusterHdfs ConnectTargetClusterS3 Questi comandi utilizzano gli stessi parametri dei comandi che hai usato per aggiungere i servizi Hive e HDFS e il bucket Amazon S3 al tuo progetto. Modifica lo script CLI per sostituire il Add prefisso con Connect nei nomi dei comandi.
