Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Componenti principali di Amazon DynamoDB
In DynamoDB, le tabelle, le voci e gli attributi sono i componenti principali da utilizzare. Una tabella è una raccolta di elementi e ogni elemento è una raccolta di attributi. DynamoDB utilizza le chiavi primarie per identificare in modo univoco ciascun elemento in una tabella. Per catturare gli eventi di modifica dei dati nelle tabelle DynamoDB è possibile utilizzare DynamoDB Streams.
Esistono dei limiti in DynamoDB. Per ulteriori informazioni, consulta Quote in Amazon DynamoDB.
Il seguente video ti fornirà un'introduzione a tabelle, elementi ed attributi.
Tabelle, elementi e attributi
Di seguito sono elencati i componenti di base di DynamoDB:
-
Tabelle: analogamente ad altri sistemi di database, DynamoDB memorizza i dati in tabelle. Una tabella è una raccolta di dati. Ad esempio, vedi la tabella di esempio chiamata People che puoi utilizzare per memorizzare le informazioni di contatto personali su amici, familiari o chiunque altro ti interessi. Potresti avere anche una tabella Cars per memorizzare le informazioni sui veicoli guidati dalle persone.
-
Elementi: ogni tabella contiene zero o più elementi. Un item è un set di attributi identificabili in modo univoco tra tutti gli altri item. Nella tabella People, ogni item rappresenta una persona. Per la tabella Cars, ogni item rappresenta un veicolo. Gli elementi in DynamoDB sono simili per molti aspetti alle righe, ai record o alle tuple in altri sistemi di database. In DynamoDB, non c'è limite al numero di elementi che è possibile memorizzare in una tabella.
-
Attributi: ogni elemento è composto da uno o più attributi. Un attributo è un elemento dati fondamentale che non ha bisogno di essere ulteriormente suddiviso. Ad esempio, un elemento in una tabella Persone contiene attributi denominati PersonID, LastNameFirstName, e così via. Per una tabella Department, un elemento potrebbe avere attributi come DepartmentID, Name, Manager e così via. Gli attributi in DynamoDB sono simili per molti aspetti ai campi o alle colonne presenti in altri sistemi di database.
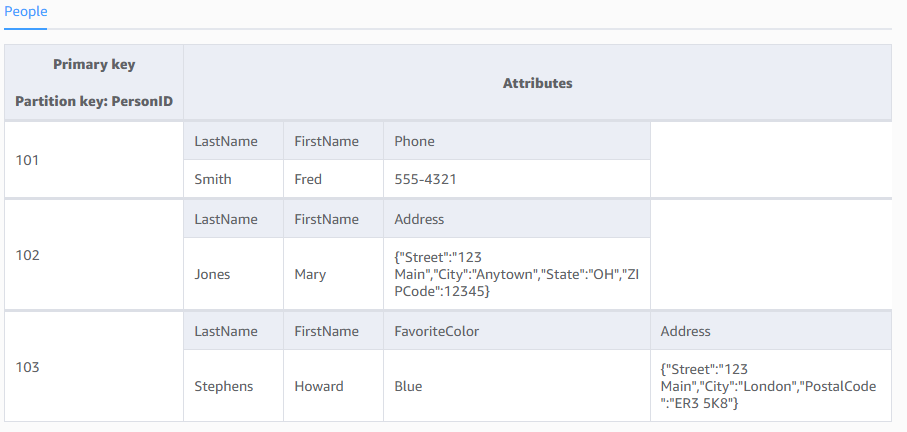
Il diagramma seguente mostra una tabella denominata People con alcuni item e attributi di esempio.
People
{
"PersonID": 101,
"LastName": "Smith",
"FirstName": "Fred",
"Phone": "555-4321"
}
{
"PersonID": 102,
"LastName": "Jones",
"FirstName": "Mary",
"Address": {
"Street": "123 Main",
"City": "Anytown",
"State": "OH",
"ZIPCode": 12345
}
}
{
"PersonID": 103,
"LastName": "Stephens",
"FirstName": "Howard",
"Address": {
"Street": "123 Main",
"City": "London",
"PostalCode": "ER3 5K8"
},
"FavoriteColor": "Blue"
}Tieni presente quanto segue sulla tabella People:
-
Ogni item nella tabella ha un identificatore univoco, o chiave primaria, che distingue l'item da tutti gli altri nella tabella. Nella tabella People, la chiave primaria consiste in un attributo (PersonID).
-
Oltre alla chiave primaria, la tabella People è schematica, il che significa che né gli attributi né i loro tipi di dati devono essere definiti in anticipo. Ogni item può avere i propri attributi distinti.
-
La maggior parte degli attributi è scalare, il che significa che possono avere un solo valore. Le stringhe e i numeri sono esempi comuni di scalari.
-
Alcuni elementi hanno un attributo nidificato (Indirizzo). DynamoDB supporta gli attributi nidificati fino a un massimo di 32 livelli di profondità.
Di seguito è riportata un'altra tabella di esempio denominata Music che puoi utilizzare per tenere traccia della tua raccolta musicale.
Music
{
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle": "Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
{
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle": "Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
{
"Artist": "The Acme Band",
"SongTitle": "Still in Love",
"AlbumTitle": "The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying": [
"KHCR",
"KQBX",
"WTNR",
"WJJH"
],
"TourDates": {
"Seattle": "20150622",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
{
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle": "The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
} Tieni presente quanto segue sulla tabella Music:
-
La chiave primaria per Music è composta da due attributi (Artista e SongTitle). Ogni item nella tabella deve avere questi due attributi. La combinazione di Artista e SongTitledistingue ogni elemento della tabella da tutti gli altri.
-
Oltre alla chiave primaria, la tabella Music è schematica, il che significa che né gli attributi né i loro tipi di dati devono essere definiti in anticipo. Ogni item può avere i propri attributi distinti.
-
Uno degli elementi ha un attributo nidificato (PromotionInfo), che contiene altri attributi nidificati. DynamoDB supporta gli attributi nidificati fino a un massimo di 32 livelli di profondità.
Per ulteriori informazioni, consulta Utilizzo di tabelle e dati in DynamoDB.
Chiave primaria
Quando crei una tabella, oltre al nome della tabella, è necessario specificare la chiave primaria della tabella. La chiave primaria identifica in modo univoco ogni elemento della tabella, in modo che due elementi non possano avere la stessa chiave.
DynamoDB supporta due diversi tipi di chiavi primarie:
-
Chiave di partizione: una chiave primaria semplice, composta da un attributo noto come chiave di partizione.
DynamoDB utilizza il valore della chiave di partizione come input per una funzione hash interna. L'output dalla funzione hash determina la partizione (spazio di archiviazione fisico interno a DynamoDB) in cui verrà memorizzato l'elemento.
In una tabella che ha solo una chiave di partizione, non è possibile che due item abbiano lo stesso valore di chiave di partizione.
La tabella People descritta in Tabelle, elementi e attributi è un esempio di una tabella con una chiave primaria semplice (PersonID). È possibile accedere direttamente a qualsiasi elemento nella tabella Persone fornendo il PersonIdvalore per tale elemento.
-
Chiave di partizione e chiave di ordinamento: indicati come chiave primaria composita, questo tipo di chiave è costituito da due attributi. Il primo attributo è la chiave di partizione e il secondo attributo è la chiave di ordinamento.
DynamoDB utilizza il valore della chiave di partizione come input per una funzione hash interna. L'output dalla funzione hash determina la partizione (spazio di archiviazione fisico interno a DynamoDB) in cui verrà memorizzato l'elemento. Tutti gli elementi con lo stesso valore della chiave di partizione vengono memorizzati insieme, in ordine per valore di chiave di ordinamento.
In una tabella che ha una chiave di partizione e una chiave di ordinamento, è possibile che più elementi abbiano lo stesso valore della chiave di partizione. Tuttavia, questi elementi devono avere valori delle chiavi di ordinamento diversi.
La tabella Music descritta in Tabelle, elementi e attributi è un esempio di tabella con una chiave primaria composita (Artist and SongTitle). È possibile accedere direttamente a qualsiasi elemento della tabella Musica, se si forniscono l'Artista e SongTitlei valori per tale elemento.
Una chiave primaria composita offre maggiore flessibilità durante la query sui dati. Ad esempio, se si fornisci solo il valore per Artist, DynamoDB recupera tutti i brani di quell'artista. Per recuperare solo un sottoinsieme di brani di un particolare artista, puoi fornire un valore per Artista insieme a un intervallo di valori per. SongTitle
Nota
La chiave di partizione di un item è anche nota come attributo hash. Il termine attributo hash deriva dall'uso di una funzione hash interna in DynamoDB che distribuisce uniformemente gli elementi di dati tra le partizioni, in base ai valori delle chiavi delle partizioni.
La chiave di ordinamento di un item è anche nota come attributo di intervallo. Il termine attributo di intervallo deriva dal modo in cui DynamoDB memorizza gli elementi con la stessa chiave di partizione fisicamente vicini, ordinati in base al valore della chiave di ordinamento.
Ogni attributo chiave primaria deve essere scalare (ovvero può contenere solo un singolo valore). Gli unici tipi di dati consentiti per gli attributi della chiave primaria sono stringa, numero o binario. Non ci sono restrizioni di questo tipo per altri attributi non di chiave.
Indici secondari
Puoi creare uno o più indici secondari su una tabella. Un indice secondario consente di eseguire query sui dati nella tabella utilizzando una chiave alternativa, oltre alle query sulla chiave primaria. DynamoDB non richiede l'utilizzo di indici, ma offre maggiore flessibilità alle applicazioni durante l'esecuzione di query sui dati. Dopo aver creato un indice secondario su una tabella, puoi leggere i dati dall'indice più o meno allo stesso modo della tabella.
DynamoDB supporta due diversi tipi di indici:
-
Indice secondario globale: un indice con una chiave di partizione e una chiave di ordinamento che possono essere differenti da quelle presenti sulla tabella. I valori della chiave primaria negli indici secondari globali non devono necessariamente essere univoci.
-
Indice secondario locale: un indice con la stessa chiave di partizione della tabella ma con una chiave di ordinamento diversa.
In DynamoDB, gli indici secondari globali (GSI) sono indici che coprono l’intera tabella e consentono di eseguire query su tutte le chiavi di partizione. Gli indici secondari locali (LSI) sono indici con la stessa chiave di partizione della tabella di base ma con una chiave di ordinamento diversa.
Ogni tabella in DynamoDB ha una quota di 20 indici secondari globali (quota predefinita) e 5 indici secondari locali.
Nella tabella Music di esempio mostrata in precedenza, è possibile interrogare gli elementi di dati per Artista (chiave di partizione) o per Artista e SongTitle(chiave di partizione e chiave di ordinamento). E se volessi interrogare i dati anche per genere e? AlbumTitle Per fare ciò, potreste creare un indice su Genre e AlbumTitlequindi interrogare l'indice più o meno allo stesso modo in cui interroghereste la tabella Music.
Il diagramma seguente mostra la tabella Music di esempio, con un nuovo indice chiamato GenreAlbumTitle. Nell'indice, Genre è la chiave di partizione e AlbumTitlela chiave di ordinamento.
| Tabella musicale | GenreAlbumTitle |
|---|---|
|
|
|
|
|
|
|
|
Nota quanto segue sull'GenreAlbumTitleindice:
-
Ogni indice appartiene a una tabella chiamata la tabella di base dell'indice. Nell'esempio precedente, Music è la tabella di base per l'GenreAlbumTitleindice.
-
DynamoDB conserva gli indici automaticamente. Quando si aggiunge, aggiorna o elimina un elemento nella tabella di base, DynamoDB aggiunge, aggiorna o elimina l'elemento corrispondente in tutti gli indici che appartengono a quella tabella.
-
Quando crei un indice, puoi specificare quali attributi verranno copiati o proiettati, dalla tabella di base all'indice. Come minimo, DynamoDB proietta gli attributi della chiave dalla tabella di base nell'indice. Questo è il caso di
GenreAlbumTitle, in cui vengono proiettati solo gli attributi della chiave della tabellaMusicnell'indice.
È possibile eseguire una query nell'GenreAlbumTitleindice per trovare tutti gli album di un particolare genere (ad esempio, tutti gli album Rock). Puoi eseguire la query sull'indice per trovare tutti gli album di un determinato genere (ad esempio, tutti gli album Country con il titolo che inizia con la lettera H).
Per ulteriori informazioni, consulta Miglioramento dell’accesso ai dati con gli indici secondari in DynamoDB.
DynamoDB Streams
DynamoDB Streams è una funzionalità opzionale che cattura gli eventi di modifica dei dati nelle tabelle DynamoDB. I dati relativi a questi eventi vengono visualizzati nel flusso pressoché in tempo reale e nell'ordine in cui si sono verificati gli eventi.
Ogni evento è rappresentato da un record di flusso. Se su una tabella viene abilitato un flusso, DynamoDB Streams scrive un record di flusso ogni volta che si verifica uno dei seguenti eventi:
-
Una nuova voce viene aggiunta alla tabella, il flusso acquisisce un'immagine dell'intera voce, inclusi tutti i suoi attributi.
-
Una voce viene aggiornata, il flusso acquisisce l'immagine "prima" e "dopo" della modifica di qualsiasi attributo nella voce.
-
Una voce viene eliminata dalla tabella, il flusso acquisisce un'immagine dell'intera voce prima che venga cancellata.
Ogni record di flusso contiene anche il nome della tabella, la data e l'ora dell'evento e altri metadati. I record di flusso hanno una durata di 24 ore e dopo vengono automaticamente rimossi dal flusso.
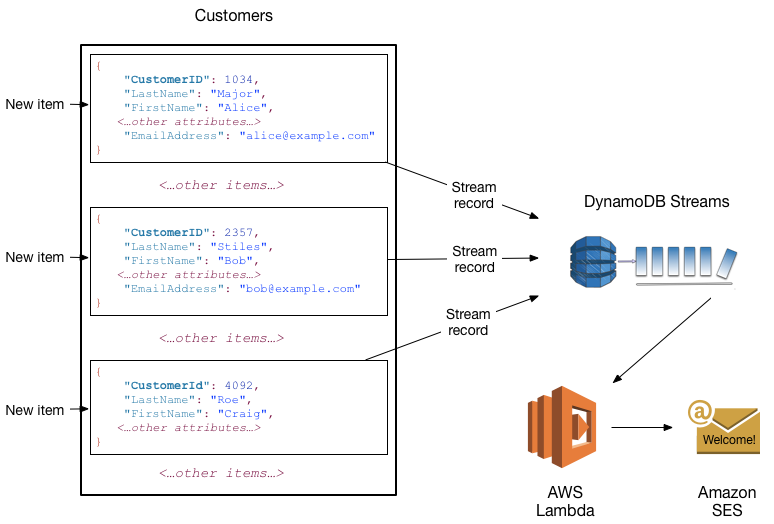
Puoi utilizzare DynamoDB Streams AWS Lambda insieme per creare un codice trigger che viene eseguito automaticamente ogni volta che un evento di interesse appare in uno stream. Ad esempio, considera la tabella Customers contenente le informazioni sui clienti di un'azienda. Supponiamo di voler inviare una e-mail di benvenuto a ogni nuovo cliente. È possibile abilitare un flusso su quella tabella e quindi associare il flusso a una funzione Lambda. La funzione Lambda viene eseguita ogni volta che viene visualizzato un nuovo record di flusso, ma vengono elaborati solo i nuovi elementi aggiunti alla tabella Customers. Per ogni elemento che ha un attributo EmailAddress, la funzione Lambda richiama Amazon Simple Email Service (Amazon SES) per inviare un messaggio e-mail a quell'indirizzo.
Nota
In questo esempio, l'ultimo cliente, Craig Roe, non riceverà un messaggio e-mail perché non ha un EmailAddress.
Oltre ai trigger, DynamoDB Streams consente soluzioni potenti come la replica dei dati all'interno e AWS tra le regioni, le viste materializzate dei dati nelle tabelle DynamoDB, l'analisi dei dati utilizzando le viste materializzate Kinesis e molto altro.
Per ulteriori informazioni, consulta Acquisizione dei dati di modifica per DynamoDB Streams.
