Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Partizioni e distribuzione dei dati in DynamoDB
Amazon DynamoDB memorizza i dati nelle partizioni. Una partizione è un'allocazione di storage per una tabella, supportata da unità a stato solido (SSD) e replicata automaticamente su più zone di disponibilità all'interno di una regione. AWS La gestione delle partizioni è gestita interamente da DynamoDB: non è mai necessario gestire le partizioni da soli.
Quando crei una tabella, lo stato iniziale della tabella è CREATING. Durante questa fase, DynamoDB assegna partizioni sufficienti alla tabella in modo che possa gestire i requisiti di velocità effettiva assegnata. Puoi iniziare a scrivere e leggere i dati della tabella dopo che lo stato della tabella diventa ACTIVE.
DynamoDB alloca partizioni aggiuntive a una tabella nelle seguenti situazioni:
-
Se aumenti le impostazioni di throughput assegnato della tabella oltre quelle supportate dalle partizioni esistenti.
-
Se una partizione esistente esaurisce la capacità ed è necessario più spazio di storage.
La gestione delle partizioni avviene automaticamente in background ed è trasparente per le tue applicazioni. La tua tabella rimane disponibile e supporta completamente i requisiti di throughput assegnati.
Per ulteriori dettagli, consultare Progettazione delle chiavi di partizione.
Anche gli indici secondari globali in DynamoDB sono costituiti da partizioni. I dati in un indice secondario globale sono memorizzati separatamente dai dati della tabella di base, ma le partizioni dell'indice si comportano in modo simile alle partizioni della tabella.
Distribuzione dei dati: chiave di partizione
Se la tabella ha una chiave primaria semplice (solo chiave di partizione), DynamoDB memorizza e recupera ciascun elemento in base al valore della chiave di partizione.
Per scrivere un elemento nella tabella, DynamoDB utilizza il valore della chiave di partizione come input per una funzione hash interna. Il valore di output dalla funzione hash determina la partizione in cui verrà memorizzato l'item.
Per leggere un elemento della tabella, è necessario specificare il valore della chiave di partizione per l'elemento. DynamoDB utilizza questo valore come input per la funzione hash, producendo così la partizione in cui è possibile trovare l'elemento.
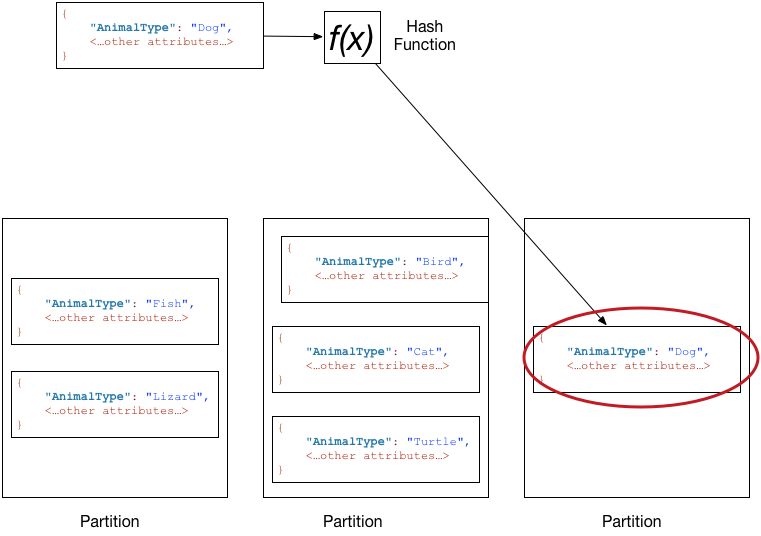
Il diagramma seguente mostra una tabella denominata Pets con più partizioni. La chiave primaria della tabella è AnimalType(viene mostrato solo questo attributo chiave). DynamoDB utilizza la funzione hash per determinare dove memorizzare un nuovo elemento, in questo caso in base al valore hash della stringa Dog. Tieni presenti che gli elementi non sono memorizzati in ordine. La posizione di ciascun item è determinata dal valore hash della chiave di partizione.
Nota
DynamoDB è ottimizzato per una distribuzione uniforme degli elementi sulle partizioni di una tabella, indipendentemente dal numero di partizioni presenti. Ti consigliamo di scegliere una chiave di partizione che possa avere un numero elevato di valori distinti rispetto al numero di item nella tabella.
Distribuzione dei dati: chiave di partizione e chiave di ordinamento
Se la tabella ha una chiave primaria composita (chiave di partizione e chiave di ordinamento), DynamoDB calcola il valore hash della chiave di partizione come descritto in Distribuzione dei dati: chiave di partizione. Tuttavia, tende a mantenere gli elementi che hanno lo stesso valore della chiave di partizione vicini e ordinati in base al valore dell’attributo della chiave di ordinamento. L’insieme di elementi che hanno lo stesso valore della chiave di partizione è denominato raccolta di elementi. Le raccolte di elementi sono ottimizzate per il recupero efficiente degli intervalli di elementi all’interno della raccolta. Se la tabella non ha indici secondari locali, DynamoDB suddividerà automaticamente la raccolta di elementi su tutte le partizioni necessarie per archiviare i dati e garantire il throughput di lettura e scrittura.
Per scrivere un elemento nella tabella, DynamoDB calcola il valore hash della chiave di partizione per determinare quale partizione lo deve contenere. In quella partizione, diversi item potrebbero avere lo stesso valore della chiave di partizione. Pertanto, DynamoDB memorizza l'elemento tra gli altri con la stessa chiave di partizione, in ordine crescente e per chiave di ordinamento.
Per leggere un elemento della tabella, è necessario specificare il valore della chiave di partizione e della chiave di ordinamento. DynamoDB calcola il valore hash della chiave di partizione, producendo la partizione in cui è possibile trovare l'elemento.
Se gli elementi desiderati hanno lo stesso valore della chiave di partizione è possibile leggere più elementi dalla tabella in una singola operazione (Query). DynamoDB restituisce tutti gli elementi con tale valore della chiave di partizione. Facoltativamente, puoi applicare una condizione alla chiave di ordinamento in modo che restituisca solo gli elementi all'interno di un determinato intervallo di valori.
Supponiamo che la tabella Pets abbia una chiave primaria composita composta da AnimalType(chiave di partizione) e Name (chiave di ordinamento). Il seguente diagramma mostra DynamoDB che scrive un elemento con un valore della chiave di partizione uguale a Dog e un valore della chiave di ordinamento uguale a Fido.
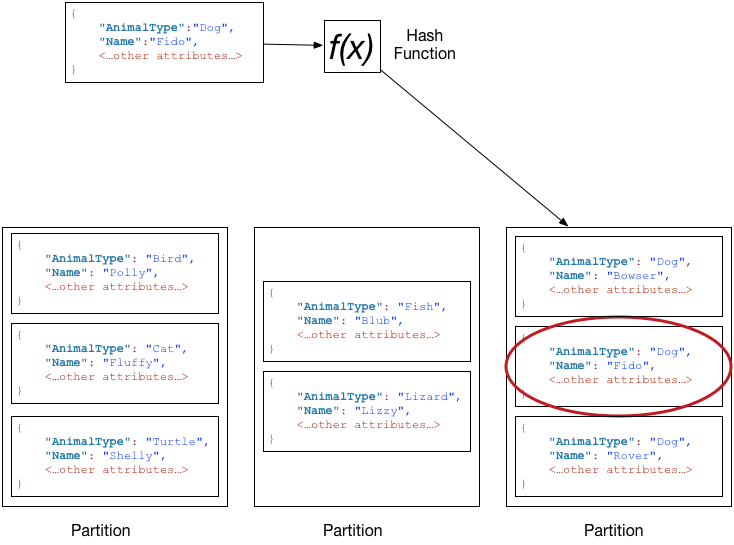
Per leggere lo stesso elemento dalla tabella Pets, DynamoDB calcola il valore hash di Dog, producendo la partizione in cui sono memorizzati questi elementi. DynamoDB esegue quindi la scansione dei valori degli attributi della chiave di ordinamento finché non trova Fido.
Per leggere tutti gli elementi con un AnimalTypeof Dog, puoi eseguire un'Queryoperazione senza specificare una condizione di chiave di ordinamento. Come impostazione predefinita, le voci vengono restituite nell'ordine in cui sono memorizzate (ovvero in ordine crescente per chiave di ordinamento). Facoltativamente, puoi richiedere l'ordine decrescente.
Per eseguire la query solo di alcune voci Dog, puoi applicare una condizione alla chiave di ordinamento (ad esempio, solo le voci Dog dove Name inizia con una lettera compresa nell'intervallo da A a K).
Nota
In una tabella DynamoDB, non esiste un limite superiore per il numero di valori delle chiavi di ordinamento distinti per valore di chiave di partizione. Se c'è bisogno di memorizzare miliardi di elementi Dog nella tabella Pets, DynamoDB assegna automaticamente l'archiviazione sufficiente per gestire questo requisito.
