Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di indici secondari globali per query di aggregazione materializzate in DynamoDB
Il mantenimento di aggregazioni quasi in tempo reale e parametri chiave oltre a dati in rapida evoluzione sta acquisendo sempre più valore per permettere alle aziende di prendere decisioni in maniera veloce. Ad esempio, una libreria musicale potrebbe voler mostrare i brani più scaricati quasi in tempo reale, oppure una piattaforma di e-commerce potrebbe dover mostrare i prodotti di tendenza per categoria.
Poiché DynamoDB non supporta nativamente operazioni di aggregazione SUM simili COUNT o tra elementi, il calcolo di questi valori in fase di lettura richiederebbe la scansione di un gran numero di elementi, il che può essere lento e costoso. È invece possibile precalcolare le aggregazioni man mano che i dati cambiano e archiviare i risultati come normali elementi della tabella. Questo modello è chiamato aggregazione materializzata.
Argomenti
Scenario di esempio e modelli di accesso
Prendi in considerazione un'applicazione di libreria musicale con i seguenti requisiti:
L'applicazione registra i download di singoli brani ad alto volume (migliaia al secondo).
Gli utenti devono vedere i brani più scaricati in un determinato mese con una latenza di un millisecondo.
L'applicazione deve inoltre supportare query come «le 10 migliori canzoni del mese» e «tutte le canzoni scaricate in un determinato mese».
Calcolare il conteggio dei download in fase di lettura mediante la scansione di tutti i record di download può essere costoso su questa scala. È invece possibile mantenere un conteggio costante che si aggiorna a ogni download e archiviarlo in un modo che supporti l'esecuzione di query efficienti.
Perché precalcolare le aggregazioni
Esistono diversi approcci al calcolo delle aggregazioni. La tabella seguente mette a confronto le alternative più comuni e spiega perché l'aggregazione materializzata in DynamoDB è spesso la soluzione migliore per questo tipo di casi d'uso.
| Approccio | Compromessi | Quando utilizzarlo |
|---|---|---|
| Scansiona e conta in fase di lettura | Richiede la lettura di tutti i record di download per ogni query. La latenza aumenta con il volume dei dati e consuma una notevole capacità di lettura. | Adatto solo per set di dati molto piccoli in cui la latenza non è un problema. |
| Archivio di aggregazione esterno (ad esempio, Amazon ElastiCache) | Aggiunge complessità operativa con un servizio separato da gestire. Richiede la logica di sincronizzazione tra DynamoDB e la cache. | Quando sono necessarie letture inferiori al millisecondo o una logica di aggregazione complessa che vada oltre i semplici conteggi. |
| Application-level aggregazione in scrittura | Associa la logica di aggregazione al percorso di scrittura. Se l'applicazione fallisce dopo aver registrato il download ma prima di aggiornare il conteggio, l'aggregazione diventa incoerente. | Quando è necessaria un'aggregazione sincrona e fortemente coerente e si può tollerare una maggiore latenza di scrittura. |
| Aggregazione materializzata con Streams e Lambda | Disaccoppia l'aggregazione dal percorso di scrittura. L'aggregazione alla fine è coerente (in genere con pochi secondi di ritardo). Aggiunge i costi di chiamata Lambda. | Quando hai bisogno di aggregazioni quasi in tempo reale con bassa latenza di lettura e puoi tollerare una eventuale coerenza. Questo è l'approccio descritto in questa pagina. |
L'approccio di aggregazione materializzata semplifica il percorso di scrittura (basta registrare il download), trasferisce l'aggregazione su un processo asincrono e archivia il risultato in DynamoDB dove può essere interrogato con una latenza di un millisecondo.
Progettazione di tabelle
Questo design utilizza una singola tabella con due tipi di elementi che condividono la stessa chiave di partizione () ma utilizzano schemi di chiave di ordinamento diversi per distinguerli: songID
Record di download: eventi di download individuali. La chiave di ordinamento è la
DownloadID(un identificatore univoco per ogni download).Elementi di aggregazione mensili: numero di Pre-computed download per brano al mese. La chiave di ordinamento è il
YYYY-MMformato del mese (ad esempio,2018-01). Questi elementi contengono anche unDownloadCountattributo con il totale corrente.
Solo gli elementi di aggregazione mensili contengono l'Monthattributo. Questa distinzione è importante per la progettazione sparsa del GSI descritta più avanti.
Il diagramma seguente mostra il layout della tabella con entrambi i tipi di elementi:
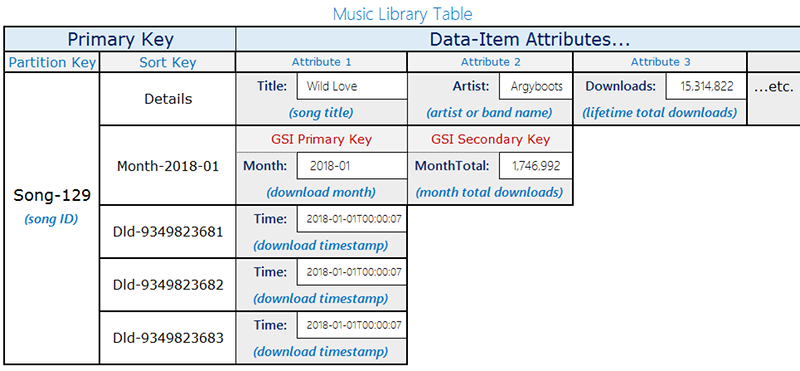
| Tipo di elemento | Chiave di partizione (SongID) | Chiave di ordinamento | Attributi aggiuntivi |
|---|---|---|---|
| Scarica il record | song1 |
download-abc123 |
UserID, Timestamp |
| Aggregazione mensile | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
Pipeline di aggregazione con Streams e AWS Lambda
La pipeline di aggregazione funziona come segue:
Quando viene scaricato un brano, l'applicazione scrive un nuovo elemento nella tabella con
Partition-Key=songIDe.Sort-Key=DownloadIDDynamoDB Streams acquisisce questa scrittura come record di flusso.
Una funzione Lambda, collegata allo stream, elabora il nuovo record. Identifica il mese
songIDe il mese corrente, quindi aggiorna l'elemento di aggregazione mensile corrispondente incrementando l'attributo.DownloadCountL'elemento di aggregazione aggiornato è quindi disponibile per l'interrogazione tramite il GSI sparso.
La funzione Lambda utilizza una UpdateItem chiamata con un'ADDespressione per incrementare atomicamente il numero di download. In questo modo si evitano condizioni di gara tra lettura-modifica-scrittura:
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
Nota
Se un'esecuzione Lambda fallisce dopo aver scritto il valore di aggregazione aggiornato, è possibile ritentare il record dello stream. Poiché l'ADDoperazione incrementa il conteggio ogni volta che viene eseguita, un nuovo tentativo incrementerebbe il conteggio più di una volta per lo stesso download, lasciandoti con un valore approssimativo. Per la maggior parte dei casi d'uso relativi all'analisi e alla classificazione, questo piccolo margine di errore è accettabile. Se hai bisogno di conteggi esatti, prendi in considerazione l'aggiunta di una logica di idempotenza, ad esempio utilizzando un'espressione di condizione che verifichi se lo specifico è già stato elaborato. DownloadID
Design GSI sparso
Per interrogare in modo efficiente i risultati aggregati, crea un indice secondario globale con il seguente schema chiave:
Chiave di partizione GSI:
Month(String)Chiave di ordinamento GSI:
DownloadCount(Numero)
Questo GSI è scarso perché solo gli elementi di aggregazione mensili contengono l'attributo. Month I singoli record di download non hanno questo attributo, quindi vengono automaticamente esclusi dall'indice. Ciò significa che il GSI contiene solo gli elementi di aggregazione precalcolati, una piccola frazione del totale degli elementi della tabella.
Un GSI scarso offre due vantaggi principali:
Costo inferiore: poiché nell'indice vengono replicati solo gli elementi di aggregazione, si consumano molta meno capacità di scrittura e storage rispetto a un indice che include tutti gli elementi della tabella.
Query più veloci: l'indice contiene solo i dati necessari per eseguire le query, quindi le letture sono efficienti e restituiscono risultati con una latenza di un millisecondo.
Per ulteriori informazioni sul funzionamento degli indici sparsi, consulta. Trai vantaggio degli indici di tipo sparse
Interrogazione del GSI
Con un GSI sparso, è possibile rispondere in modo efficiente a diversi tipi di domande:
Ottieni la canzone più scaricata in un determinato mese:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
Se ScanIndexForward si imposta su, false i risultati vengono ordinati DownloadCount in ordine decrescente e viene Limit=1 restituito solo il brano migliore.
Visualizza le 10 migliori canzoni di un determinato mese:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
Scarica tutti i brani in un determinato mese (ordinati per numero di download):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
Considerazioni
Tieni presente quanto segue quando implementi questo modello:
Coerenza finale: i valori di aggregazione vengono aggiornati in modo asincrono tramite DynamoDB Streams e Lambda. In genere c'è un ritardo di alcuni secondi tra la registrazione di un download e l'aggiornamento dell'aggregazione. Ciò significa che il GSI riflette dati quasi in tempo reale, non dati in tempo reale.
Concorrenza Lambda: se la tabella ha un volume di scrittura elevato, più chiamate Lambda possono tentare di aggiornare contemporaneamente lo stesso elemento di aggregazione. L'
ADDoperazione atomica lo gestisce in modo sicuro, ma è necessario monitorare la concorrenza Lambda e le metriche di limitazione per garantire che la funzione possa tenere il passo con il flusso.Capacità di scrittura GSI: poiché il GSI sparso contiene solo elementi di aggregazione, richiede una capacità di scrittura significativamente inferiore rispetto alla tabella base. Tuttavia, è comunque necessario fornire una capacità sufficiente (o utilizzare la modalità on-demand) per gestire la frequenza degli aggiornamenti di aggregazione.
Conteggi approssimativi: come notato in precedenza, i nuovi tentativi Lambda possono far sì che i conteggi vengano leggermente sovrastimati. Per i casi d'uso che richiedono conteggi esatti, implementa i controlli di idempotenza nella funzione Lambda.
