Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Overload degli indici secondari globali in DynamoDB
Sebbene Amazon DynamoDB abbia una quota predefinita di 20 indici secondari globali per tabella, in pratica, puoi indicizzare su più di 20 campi di dati. A differenza di una tabella in un sistema di gestione del database relazionale (RDBMS), in cui lo schema è uniforme, una tabella in può contenere molti tipi di elementi di dati diversi allo stesso tempo. Inoltre, lo stesso attributo in elementi diversi può contenere tipi di informazioni completamente diversi.
Si consideri il seguente esempio di layout di tabella DynamoDB che salva una varietà di diversi tipi di dati.
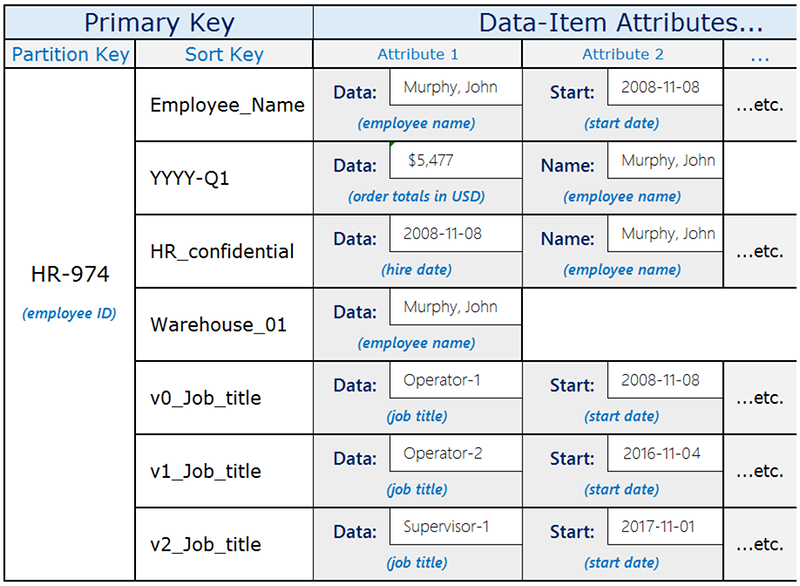
L'attributo Data, che è comune per tutte le voci ha un contenuto diverso in base alla voce padre. Se crei un indice secondario globale per la tabella che utilizza la chiave di ordinamento della tabella come chiave di partizione e l'attributo Data come chiave di ordinamento, puoi eseguire query diverse utilizzando quel singolo indice secondario globale. Queste query possono includere quanto segue:
Cercare un dipendente in base al nome nell'indice secondario globale, utilizzando
Employee_Namecome valore della chiave di partizione e il nome del dipendente (ad esempioMurphy, John) come valore della chiave di ordinamento.Utilizza l'indice secondario globale per trovare tutti i dipendenti che lavorano in un magazzino specifico cercando un ID magazzino (come
Warehouse_01).Ottieni una lista dei neoassunti eseguendo una query sull'indice secondario globale su
HR_confidentialcome valore di chiave di partizione e utilizzando un intervallo di date come valore della chiave di ordinamento.
