Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fonti di dati
Nella sezione precedente, abbiamo appreso che uno schema definisce la forma dei dati. Tuttavia, non abbiamo mai spiegato da dove provenissero quei dati. Nei progetti reali, lo schema è come un gateway che gestisce tutte le richieste fatte al server. Quando viene effettuata una richiesta, lo schema funge da singolo endpoint che si interfaccia con il client. Lo schema accederà, elaborerà e inoltrerà i dati dalla fonte dati al client. Guarda l'infografica qui sotto:
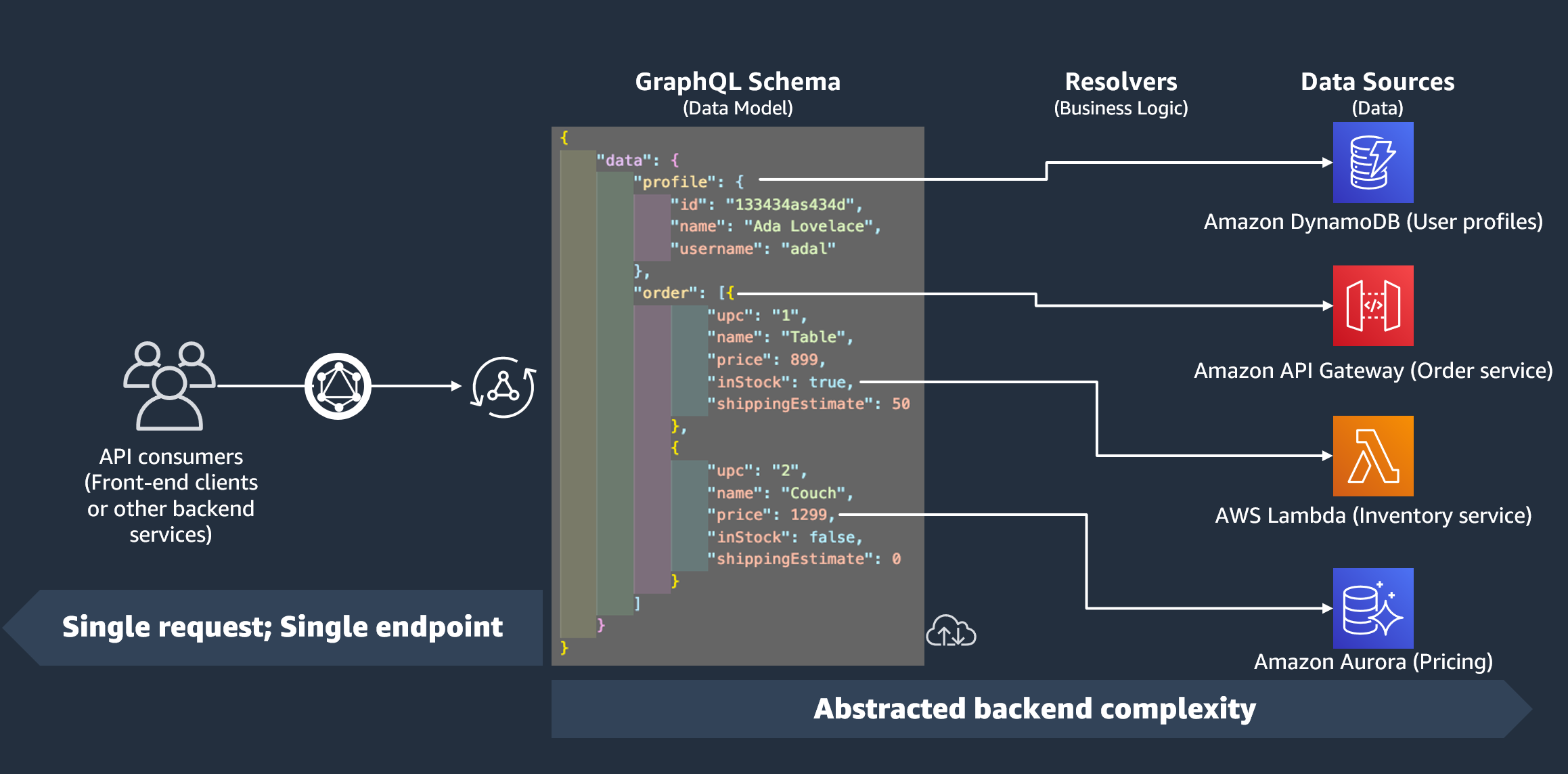
AWS AppSync e GraphQL implementano in modo eccellente le soluzioni Backend For Frontend (BFF). Lavorano in tandem per ridurre la complessità su larga scala astraendo il backend. Se il tuo servizio utilizza diverse fonti di dati e/o microservizi, puoi essenzialmente eliminare parte della complessità definendo la forma dei dati di ciascuna fonte (sottografo) in un unico schema (supergrafo). Ciò significa che l'API GraphQL non si limita a utilizzare un'unica fonte di dati. Puoi associare un numero qualsiasi di fonti di dati all'API GraphQL e specificare nel codice come interagiranno con il servizio.
Come puoi vedere nell'infografica, lo schema GraphQL contiene tutte le informazioni di cui i client hanno bisogno per richiedere dati. Ciò significa che tutto può essere elaborato in un'unica richiesta anziché in più richieste come nel caso di REST. Queste richieste passano attraverso lo schema, che è l'unico endpoint del servizio. Quando le richieste vengono elaborate, un resolver (spiegato nella sezione successiva) esegue il proprio codice per elaborare i dati dalla fonte di dati pertinente. Quando viene restituita la risposta, il sottografo collegato all'origine dati verrà popolato con i dati dello schema.
AWS AppSync supporta molti tipi di fonti di dati diversi. Nella tabella seguente, descriveremo ogni tipo, elencheremo alcuni dei vantaggi di ciascuno e forniremo link utili per un contesto aggiuntivo.
| Origine dati | Description | Vantaggi | Informazioni supplementari |
|---|---|---|---|
| Amazon DynamoDB | «Amazon DynamoDB è un servizio di database NoSQL completamente gestito che offre prestazioni veloci e prevedibili con una scalabilità perfetta. DynamoDB consente di scaricare gli oneri di gestione e dimensionamento di un database distribuito in modo da non doversi più preoccupare di provisioning dell'hardware, installazione e configurazione, replica, applicazione di patch al software e dimensionamento del cluster. DynamoDB offre anche la crittografia a riposo, che elimina l'onere operativo e la complessità associati alla protezione dei dati sensibili». |
|
|
| AWS Lambda | "AWS Lambda è un servizio di elaborazione che consente di eseguire codice senza effettuare il provisioning o la gestione di server. Lambda esegue il codice su un'infrastruttura di elaborazione ad alta disponibilità e gestisce tutta l'amministrazione delle risorse di elaborazione, compresa la manutenzione del server e del sistema operativo, il provisioning e la scalabilità automatica della capacità e la registrazione. Con Lambda, tutto ciò che devi fare è fornire il codice in uno dei runtime linguistici supportati da Lambda». |
|
|
| OpenSearch | «Amazon OpenSearch Service è un servizio gestito che semplifica l'implementazione, il funzionamento e la scalabilità OpenSearch dei cluster nel AWS cloud. Amazon OpenSearch Service supporta un sistema operativo OpenSearch Elasticsearch legacy (fino alla versione 7.10, l'ultima versione open source del software). Quando si crea un cluster, è possibile scegliere il motore di ricerca da usare. OpenSearchè un motore di ricerca e analisi completamente open source per casi d'uso come l'analisi dei log, il monitoraggio delle applicazioni in tempo reale e l'analisi dei clickstream. Per ulteriori informazioni, consulta la documentazione relativa ad OpenSearch Amazon OpenSearch Service fornisce tutte le risorse per il OpenSearch cluster e lo avvia. Inoltre, rileva e sostituisce automaticamente i nodi di OpenSearch servizio guasti, riducendo il sovraccarico associato alle infrastrutture autogestite. Puoi scalare il cluster con una singola chiamata API o pochi clic nella console». |
|
|
| Endpoint HTTP | Puoi utilizzare gli endpoint HTTP come fonti di dati. AWS AppSync può inviare richieste agli endpoint con le informazioni pertinenti come parametri e payload. La risposta HTTP verrà esposta al resolver, che restituirà la risposta finale al termine delle sue operazioni. |
|
|
| Amazon EventBridge | "EventBridge è un servizio serverless che utilizza gli eventi per connettere tra loro i componenti delle applicazioni, semplificando la creazione di applicazioni scalabili basate sugli eventi. Utilizzatelo per indirizzare gli eventi da fonti quali applicazioni, AWS servizi e software di terze parti sviluppati internamente alle applicazioni destinate ai consumatori all'interno dell'organizzazione. EventBridge offre un modo semplice e coerente per importare, filtrare, trasformare e fornire eventi in modo da poter creare nuove applicazioni rapidamente». |
|
|
| Database relazionali | «Amazon Relational Database Service (Amazon RDS) è un servizio Web che semplifica la configurazione, il funzionamento e la scalabilità di un database relazionale nel cloud. AWS Fornisce una capacità ridimensionabile e conveniente per un database relazionale standard del settore e gestisce le attività comuni di amministrazione dei database». |
|
|
| Nessuna fonte di dati | Se non hai intenzione di utilizzare un servizio di origine dati, puoi impostarlo sunone. Una fonte di none dati, sebbene sia ancora esplicitamente classificata come fonte di dati, non è un supporto di archiviazione. Nonostante ciò, è ancora utile in alcuni casi per la manipolazione e il trasferimento dei dati. |
|
Suggerimento
Per ulteriori informazioni su come interagiscono le sorgenti di dati AWS AppSync, consulta Allegare un'origine dati.
