Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risolutori
Nelle sezioni precedenti, hai appreso i componenti dello schema e dell'origine dati. Ora, dobbiamo affrontare il modo in cui lo schema e le fonti di dati interagiscono. Tutto inizia con il resolver.
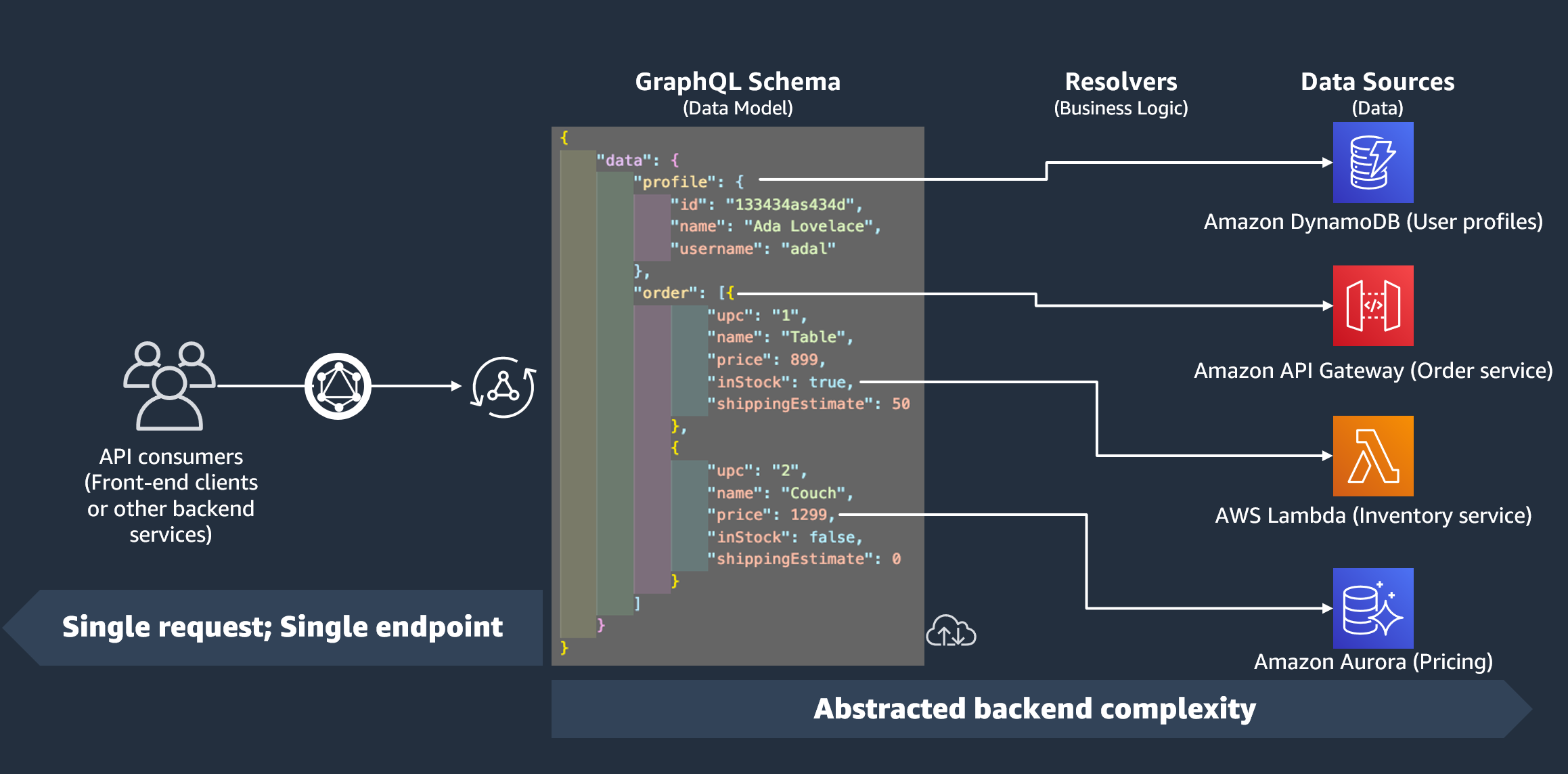
Un resolver è un'unità di codice che gestisce il modo in cui i dati di quel campo verranno risolti quando viene effettuata una richiesta al servizio. I resolver sono associati a campi specifici all'interno dei tipi dello schema. Sono più comunemente usati per implementare le operazioni di modifica dello stato per le operazioni sui campi di interrogazione, mutazione e sottoscrizione. Il resolver elaborerà la richiesta del client, quindi restituirà il risultato, che può essere un gruppo di tipi di output come oggetti o scalari:
Runtime del resolver
In AWS AppSync, devi prima specificare un runtime per il tuo resolver. Un runtime del resolver indica l'ambiente in cui viene eseguito un resolver. Determina anche la lingua in cui verranno scritti i resolver. AWS AppSync attualmente supporta APPSYNC_JS for JavaScript e Velocity Template Language (VTL). Vedi le funzionalità JavaScript di runtime per i resolver e le funzioni per o il riferimento all'utilità dei modelli di mappatura Resolver per JavaScript VTL.
Struttura del resolver
Dal punto di vista del codice, i resolver possono essere strutturati in un paio di modi. Esistono resolver di unità e pipeline.
Risolver di unità
Un resolver di unità è composto da codice che definisce un singolo gestore di richieste e risposte che vengono eseguiti su un'origine dati. Il gestore di richieste accetta un oggetto di contesto come argomento e restituisce il payload della richiesta utilizzato per chiamare l'origine dei dati. Il gestore della risposta riceve un payload dall'origine dati con il risultato della richiesta eseguita. Il gestore di risposte trasforma il payload in una risposta GraphQL per risolvere il campo GraphQL.
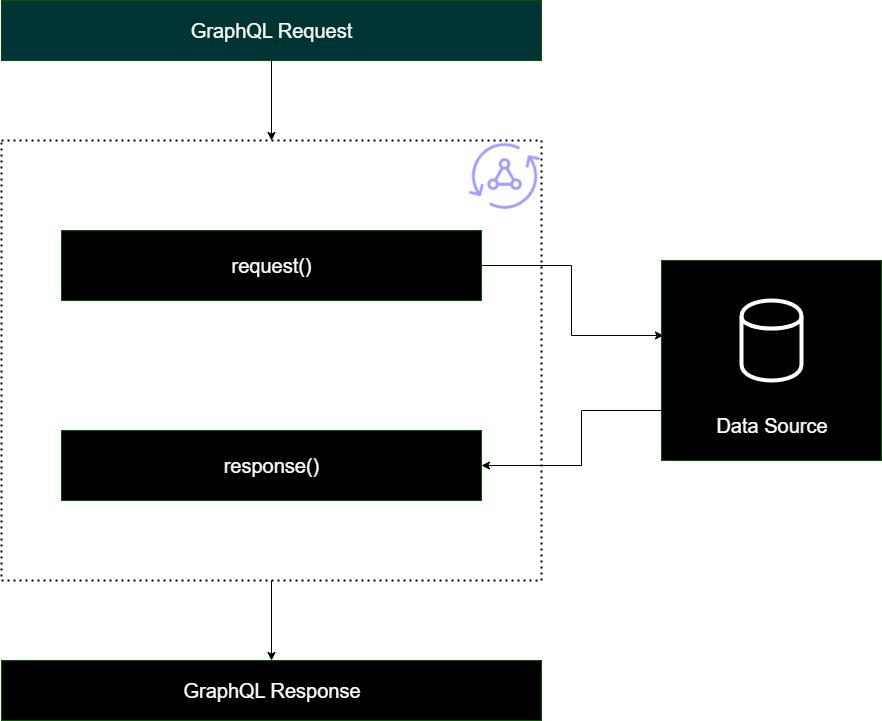
Risolutori per pipeline
Quando si implementano i risolutori di pipeline, esiste una struttura generale che seguono:
-
Prima della fase: quando viene effettuata una richiesta dal client, ai resolver per i campi dello schema utilizzati (in genere le query, le mutazioni, le sottoscrizioni) vengono trasmessi i dati della richiesta. Il resolver inizierà a elaborare i dati della richiesta con un gestore del passaggio precedente, che consente di eseguire alcune operazioni di preelaborazione prima che i dati passino attraverso il resolver.
-
Funzione/i: dopo l'esecuzione del passaggio precedente, la richiesta viene passata all'elenco delle funzioni. La prima funzione dell'elenco verrà eseguita sulla fonte di dati. Una funzione è un sottoinsieme del codice del resolver contenente il proprio gestore di richieste e risposte. Un gestore di richieste raccoglierà i dati della richiesta ed eseguirà operazioni sulla fonte dei dati. Il gestore della risposta elaborerà la risposta dell'origine dati prima di restituirla all'elenco. Se è presente più di una funzione, i dati della richiesta verranno inviati alla funzione successiva nell'elenco da eseguire. Le funzioni nell'elenco verranno eseguite in serie nell'ordine definito dallo sviluppatore. Una volta eseguite tutte le funzioni, il risultato finale viene passato alla fase successiva.
-
Dopo la fase: la fase successiva è una funzione di gestione che consente di eseguire alcune operazioni finali sulla risposta finale della funzione prima di passarla alla risposta GraphQL.
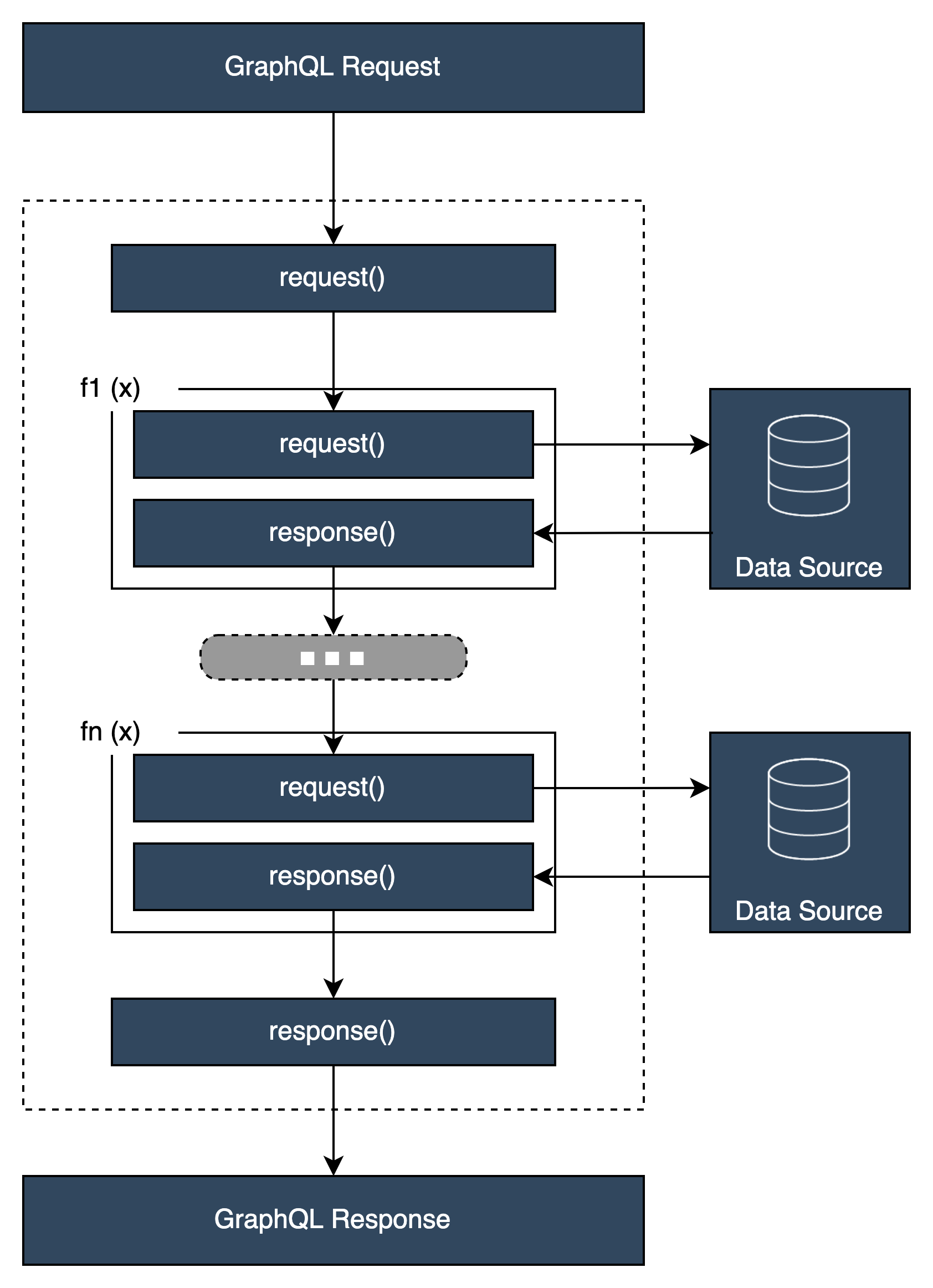
Struttura del gestore Resolver
I gestori sono in genere funzioni chiamate e: Request Response
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
In un risolutore di unità, ci sarà solo un set di queste funzioni. In un resolver a pipeline, ci sarà un set di queste per la fase prima e dopo e un set aggiuntivo per funzione. Per vedere come potrebbe apparire, esaminiamo un tipo semplice: Query
type Query { helloWorld: String! }
Questa è una semplice interrogazione con un campo chiamato helloWorld of typeString. Supponiamo di voler sempre che questo campo restituisca la stringa «Hello World». Per implementare questo comportamento, dobbiamo aggiungere il resolver a questo campo. In un risolutore di unità, potremmo aggiungere qualcosa del genere:
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
requestPuò semplicemente essere lasciato vuoto perché non stiamo richiedendo o elaborando dati. Possiamo anche supporre che la nostra fonte di dati siaNone, indicando che questo codice non deve eseguire alcuna chiamata. La risposta restituisce semplicemente «Hello World». Per testare questo resolver, dobbiamo fare una richiesta utilizzando il tipo di query:
query helloWorldTest { helloWorld }
Questa è una query chiamata helloWorldTest che restituisce il helloWorld campo. Quando viene eseguito, il helloWorld field resolver esegue e restituisce anche la risposta:
{ "data": { "helloWorld": "Hello World" } }
Restituire costanti come questa è la cosa più semplice che si possa fare. In realtà, restituirai input, elenchi e altro. Ecco un esempio più complicato:
type Book { id: ID! title: String } type Query { getBooks: [Book] }
Qui stiamo restituendo un elenco diBooks. Supponiamo di utilizzare una tabella DynamoDB per archiviare i dati dei libri. I nostri gestori potrebbero avere il seguente aspetto:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
La nostra richiesta ha utilizzato un'operazione di scansione integrata per cercare tutte le voci della tabella, memorizzato i risultati nel contesto e quindi li ha passati alla risposta. La risposta ha preso gli elementi del risultato e li ha restituiti nella risposta:
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
Contesto del risolutore
In un resolver, ogni fase della catena di gestori deve essere a conoscenza dello stato dei dati dei passaggi precedenti. Il risultato di un gestore può essere memorizzato e passato a un altro come argomento. GraphQL definisce quattro argomenti di base del resolver:
| Argomenti di base del resolver | Description |
|---|---|
obj, root, parent e così via. |
Il risultato del genitore. |
args |
Gli argomenti forniti al campo nella query GraphQL. |
context |
Un valore che viene fornito a ogni resolver e contiene importanti informazioni contestuali come l'utente attualmente connesso o l'accesso a un database. |
info |
Un valore che contiene informazioni specifiche sul campo relative alla query corrente e i dettagli dello schema. |
Nel AWS AppSync, l'argomento context (ctx) può contenere tutti i dati sopra menzionati. È un oggetto creato su richiesta e contiene dati come credenziali di autorizzazione, dati sui risultati, errori, metadati di richiesta, ecc. Il contesto è un modo semplice per i programmatori di manipolare i dati provenienti da altre parti della richiesta. Riprendi questo frammento:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
Alla richiesta viene fornito il contesto (ctx) come argomento; questo è lo stato della richiesta. Esegue una scansione di tutti gli elementi di una tabella, quindi memorizza il risultato nel contesto inresult. Il contesto viene quindi passato all'argomento response, che accede a result e ne restituisce il contenuto.
Richieste e analisi
Quando si effettua una query sul servizio GraphQL, questa deve essere sottoposta a un processo di analisi e convalida prima di essere eseguita. La tua richiesta verrà analizzata e tradotta in un albero di sintassi astratto. Il contenuto dell'albero viene convalidato eseguendo diversi algoritmi di convalida rispetto allo schema. Dopo la fase di convalida, i nodi dell'albero vengono attraversati ed elaborati. I resolver vengono richiamati, i risultati vengono archiviati nel contesto e viene restituita la risposta. Ad esempio, prendiamo questa query:
query { Person { //object type name //scalar age //scalar } }
Stiamo tornando Person con i campi a e. name age Quando si esegue questa query, l'albero avrà un aspetto simile a questo:
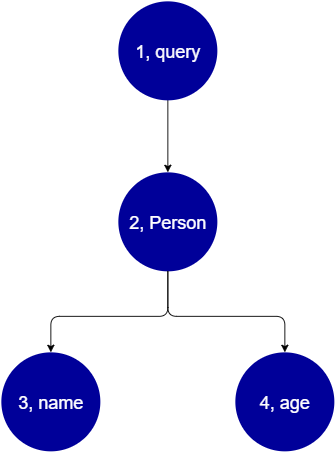
Dall'albero, sembra che questa richiesta cercherà la radice di Query nello schema. All'interno della query, il Person campo verrà risolto. Dagli esempi precedenti, sappiamo che questo potrebbe essere un input dell'utente, un elenco di valori, ecc. Person è molto probabilmente legato a un tipo di oggetto che contiene i campi di cui abbiamo bisogno (nameeage). Una volta trovati, questi due campi secondari vengono risolti nell'ordine indicato (nameseguiti daage). Una volta che l'albero è stato completamente risolto, la richiesta viene completata e verrà rispedita al client.
