Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Visualizzazione delle anomalie reattive
All'interno di una panoramica, puoi visualizzare le anomalie per le risorse Amazon RDS. In una pagina di analisi reattiva, nella sezione Metriche aggregate, puoi visualizzare un elenco di anomalie con le tempistiche corrispondenti. Sono inoltre presenti sezioni che visualizzano informazioni sui gruppi di log e sugli eventi correlati alle anomalie. Le anomalie causali in un'analisi reattiva hanno ciascuna una pagina corrispondente con i dettagli sull'anomalia.
Visualizzazione dell'analisi dettagliata di un'anomalia reattiva RDS
In questa fase, analizza l'anomalia per ottenere analisi dettagliate e consigli per le tue istanze database Amazon RDS.
L'analisi dettagliata è disponibile solo per le istanze DB di Amazon RDS con Performance Insights attivato.
Per visualizzare in dettaglio la pagina dei dettagli dell'anomalia
-
Nella pagina di approfondimento, trova una metrica aggregata con il tipo di risorsa AWS/RDS.
-
Seleziona Visualizza dettagli.
Viene visualizzata la pagina dei dettagli dell'anomalia. Il titolo inizia con Anomalia delle prestazioni del database e nomina la risorsa mostrata. Per impostazione predefinita, la console utilizza l'anomalia con la gravità più elevata, indipendentemente dal momento in cui si è verificata l'anomalia.
-
(Facoltativo) Se sono interessate più risorse, scegliete una risorsa diversa dall'elenco nella parte superiore della pagina.
Di seguito, puoi trovare le descrizioni dei componenti della pagina dei dettagli.
Panoramica delle risorse
La sezione superiore della pagina dei dettagli è Panoramica delle risorse. Questa sezione riassume l'anomalia delle prestazioni riscontrata dalla tua istanza database Amazon RDS.
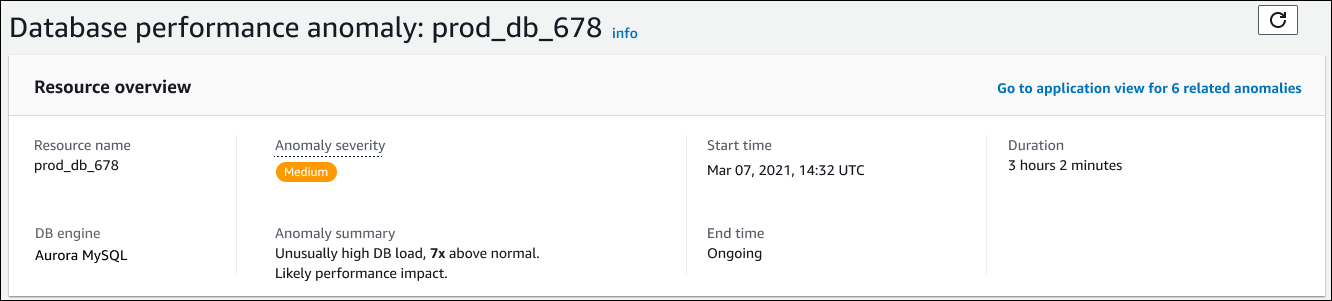
Questa sezione contiene i seguenti campi:
-
Nome della risorsa: il nome dell'istanza DB che presenta l'anomalia. In questo esempio, la risorsa è denominata prod_db_678.
-
Motore DB: il nome dell'istanza DB che presenta l'anomalia. In questo esempio, il motore è Aurora MySQL.
-
Gravità dell'anomalia: la misura dell'impatto negativo dell'anomalia sull'istanza. I livelli di gravità possibili sono Alta, Media e Bassa.
-
Riepilogo delle anomalie: breve riepilogo del problema. Un riepilogo tipico è il carico del DB insolitamente elevato.
-
Ora di inizio e ora di fine: l'ora in cui l'anomalia è iniziata e terminata. Se l'ora di fine è in corso, l'anomalia si verifica ancora.
-
Durata: la durata del comportamento anomalo. In questo esempio, l'anomalia è in corso e si verifica da 3 ore e 2 minuti.
Metrica principale
La sezione Metrica principale riassume l'anomalia casuale, che è l'anomalia di primo livello all'interno dell'analisi. Puoi pensare all'anomalia causale come al problema generale riscontrato dalla tua istanza DB.
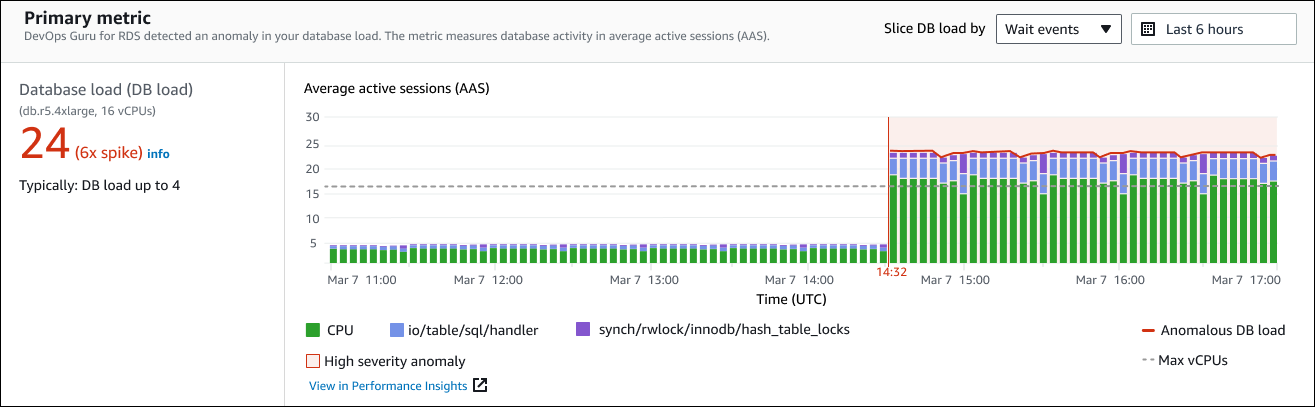
Il pannello di sinistra fornisce ulteriori dettagli sul problema. In questo esempio, il riepilogo include le seguenti informazioni:
-
Caricamento del database (caricamento del database): una categorizzazione dell'anomalia come problema di caricamento del database. La metrica corrispondente in Performance Insights è
DBLoad. Questa metrica viene pubblicata anche su Amazon CloudWatch. -
db.r5.4xlarge — La classe dell'istanza DB. Il numero di vCPUs, che in questo esempio è 16, corrisponde alla linea tratteggiata nel grafico delle sessioni attive medie (AAS).
-
24 (picco 6x) — Il carico del DB, misurato in sessioni attive medie (AAS) durante l'intervallo di tempo riportato nell'analisi. Pertanto, in qualsiasi momento durante il periodo dell'anomalia, sul database erano attive in media 24 sessioni. Il carico del DB è 6 volte il normale carico del DB per questa istanza.
-
In genere: carico del DB fino a 4: la linea di base del carico del DB, misurata in AAS, durante un carico di lavoro tipico. Il valore 4 indica che, durante le normali operazioni, sul database sono attive in media 4 o meno sessioni in un dato momento.
Per impostazione predefinita, il grafico di caricamento viene suddiviso in base agli eventi di attesa. Ciò significa che per ogni barra del grafico, l'area colorata più grande rappresenta l'evento di attesa che contribuisce maggiormente al carico totale del DB. Il grafico mostra l'ora (in rosso) in cui è iniziato il problema. Concentra la tua attenzione sugli eventi di attesa che occupano più spazio nella barra:
-
CPU -
IO:wait/io/sql/table/handler
Gli eventi di attesa precedenti appaiono più del normale per questo database Aurora MySQL. Per informazioni su come ottimizzare le prestazioni utilizzando gli eventi di attesa in Amazon Aurora, consulta Tuning with wait events for Aurora MySQL e Tuning with wait events for Aurora PostgreSQL nella Amazon Aurora User Guide. Per informazioni su come ottimizzare le prestazioni utilizzando gli eventi di attesa in RDS per PostgreSQL, consulta Tuning with wait events for RDS for PostgreSQL nella Amazon RDS User Guide.
Metriche correlate
La sezione Metriche correlate elenca le anomalie contestuali, che sono risultati specifici all'interno dell'anomalia causale. Questi risultati forniscono informazioni aggiuntive sui problemi di prestazioni.
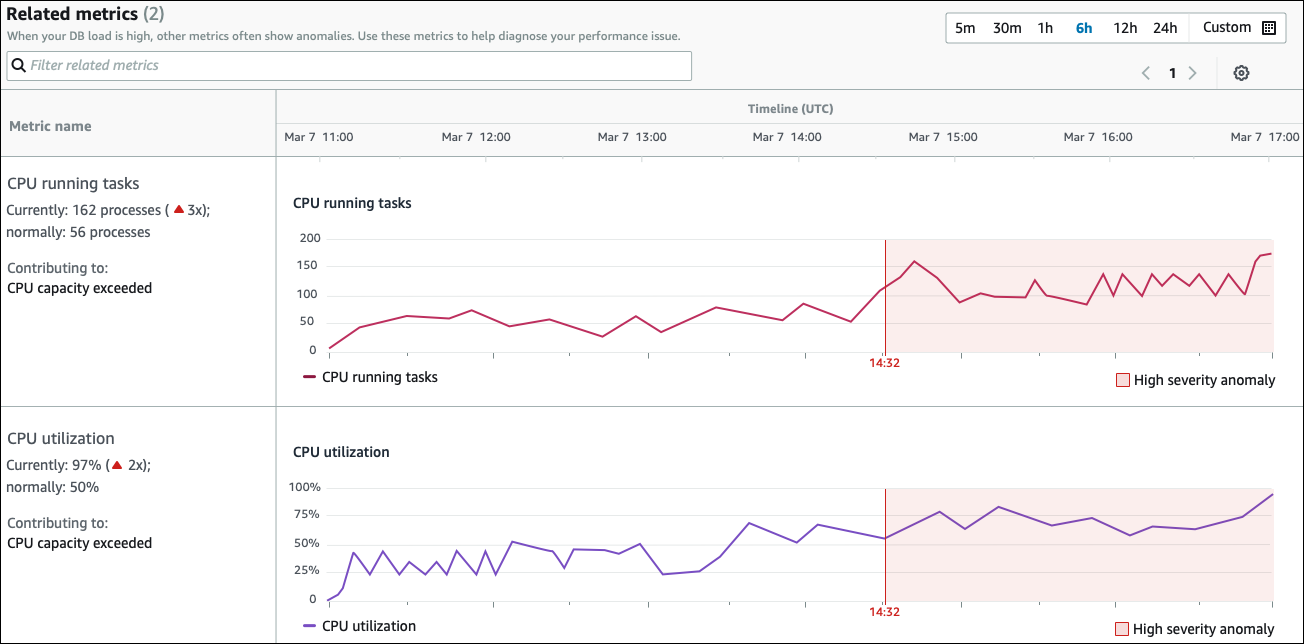
La tabella delle metriche correlate ha due colonne: Nome delle metriche e Cronologia (UTC). Ogni riga della tabella corrisponde a una metrica specifica.
La prima colonna di ogni riga contiene le seguenti informazioni:
-
Name— Il nome della metrica. La prima riga identifica la metrica come attività di esecuzione della CPU. -
Attualmente: il valore corrente della metrica. Nella prima riga, il valore corrente è 162 processi (3x).
-
Normalmente: la linea di base di questa metrica per questo database quando funziona normalmente. DevOpsGuru for RDS calcola la linea di base come valore del 95° percentile in 1 settimana di cronologia. La prima riga indica che sulla CPU sono in genere in esecuzione 56 processi.
-
Contribuire a: il risultato associato a questa metrica. Nella prima riga, la metrica delle attività di esecuzione della CPU è associata all'anomalia della capacità della CPU superata.
La colonna Cronologia mostra un grafico a linee per la metrica. L'area ombreggiata mostra l'intervallo di tempo in cui DevOps Guru for RDS ha indicato il risultato come di elevata gravità.
Analisi e raccomandazioni
Mentre l'anomalia causale descrive il problema generale, un'anomalia contestuale descrive un risultato specifico che richiede un'indagine. Ogni risultato corrisponde a una serie di metriche correlate.
Nel seguente esempio di sezione Analisi e raccomandazioni, l'elevata anomalia di carico del DB presenta due risultati.
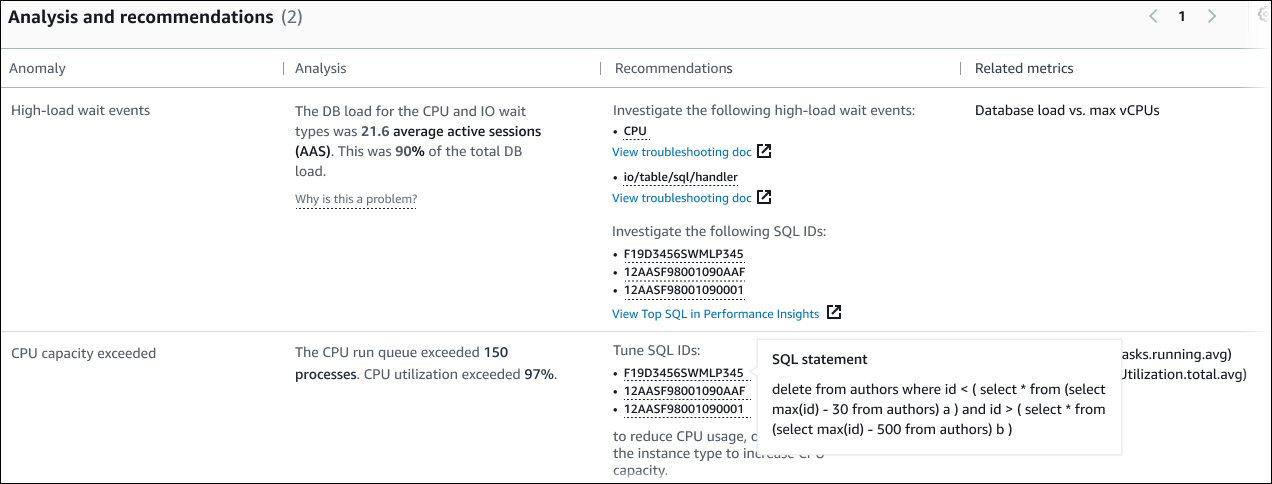
La tabella contiene le seguenti colonne:
-
Anomalia: una descrizione generale di questa anomalia contestuale. In questo esempio, la prima anomalia è rappresentata da eventi di attesa ad alto carico e la seconda è il superamento della capacità della CPU.
-
Analisi: una spiegazione dettagliata dell'anomalia.
Nella prima anomalia, tre tipi di attesa contribuiscono al 90% del carico del DB. Nella seconda anomalia, la coda di esecuzione della CPU superava i 150, il che significa che in un dato momento, più di 150 sessioni erano in attesa del tempo della CPU. L'utilizzo della CPU era superiore al 97%, il che significa che per tutta la durata del problema, la CPU è stata occupata il 97% delle volte. Pertanto, la CPU era occupata quasi ininterrottamente, mentre una media di 150 sessioni attendeva l'esecuzione sulla CPU.
-
Raccomandazioni: la risposta suggerita dell'utente all'anomalia.
Nella prima anomalia, DevOps Guru for RDS consiglia di esaminare gli eventi di attesa e.
cpuio/table/sql/handlerPer informazioni su come ottimizzare le prestazioni del database in base a questi eventi, consulta cpu e io/table/sql/handlernella Amazon Aurora User Guide.Nella seconda anomalia, DevOps Guru for RDS consiglia di ridurre il consumo di CPU ottimizzando tre istruzioni SQL. Puoi passare il mouse sui link per visualizzare il testo SQL.
-
Metriche correlate: metriche che forniscono misurazioni specifiche dell'anomalia. Per ulteriori informazioni su questi parametri, consulta il riferimento ai parametri per Amazon Aurora nella Guida per l'utente di Amazon Aurora o il riferimento ai parametri per Amazon RDS nella Guida per l'utente di Amazon RDS.
Nella prima anomalia, DevOps Guru for RDS consiglia di confrontare il carico del DB con la CPU massima per l'istanza. Nella seconda anomalia, si consiglia di esaminare la coda di esecuzione della CPU, l'utilizzo della CPU e la frequenza di esecuzione SQL.
