Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di un database Amazon DynamoDB come destinazione per AWS Database Migration Service
Puoi utilizzarlo AWS DMS per migrare i dati su una tabella Amazon DynamoDB. Amazon DynamoDB è un servizio di database NoSQL completamente gestito che offre prestazioni veloci e prevedibili con una scalabilità perfetta. AWS DMS supporta l'utilizzo di un database relazionale o MongoDB come fonte.
In DynamoDB, le tabelle, le voci e gli attributi sono i componenti principali da utilizzare. Una tabella è una raccolta di elementi e ogni elemento è una raccolta di attributi. DynamoDB utilizza le chiavi primarie, denominate chiavi di partizione, per identificare in modo univoco ciascuna voce in una tabella. Puoi inoltre utilizzare chiavi e indici secondari per fornire maggiore flessibilità nell'esecuzione di query.
È possibile utilizzare la mappatura degli oggetti per migrare i dati da un database di origine a una tabella DynamoDB di destinazione. La mappatura di oggetti consente di determinare dove sono posizionati i dati di origine nella destinazione.
Quando AWS DMS crea tabelle su un endpoint di destinazione DynamoDB, crea tante tabelle quante sono nell'endpoint del database di origine. AWS DMS imposta anche diversi valori dei parametri DynamoDB. Il costo per la creazione della tabella dipende dalla quantità di dati e dal numero di tabelle da migrare.
Nota
L'opzione Modalità SSL sulla AWS DMS console o sull'API non si applica ad alcuni servizi di streaming di dati e NoSQL come Kinesis e DynamoDB. Sono sicuri per impostazione predefinita, quindi AWS DMS mostra che l'impostazione della modalità SSL è uguale a none (modalità SSL = Nessuno). Per utilizzare SSL non è necessario eseguire alcuna configurazione aggiuntiva per l'endpoint. Ad esempio, l'utilizzo di DynamoDB come endpoint di destinazione è sicuro per impostazione predefinita. Tutte le chiamate API a DynamoDB utilizzano SSL, quindi non è necessaria un'opzione SSL aggiuntiva nell'endpoint. AWS DMS È possibile inserire dati e recuperarli in modo sicuro tramite gli endpoint SSL utilizzando il protocollo HTTPS, usato da AWS DMS per impostazione predefinita per la connessione a un database DynamoDB.
Per aumentare la velocità di trasferimento, AWS DMS supporta un caricamento completo multithread su un'istanza di destinazione di DynamoDB. DMS supporta questo multithreading con impostazioni delle attività che includono le seguenti:
-
MaxFullLoadSubTasks: imposta questa opzione per indicare il numero massimo di tabelle da caricare in parallelo. DMS carica ogni tabella nella corrispondente tabella di destinazione DynamoDB utilizzando un'attività secondaria dedicata. Il valore predefinito è 8. Il valore massimo è 49. -
ParallelLoadThreads— Utilizzate questa opzione per specificare il numero di thread da utilizzare per caricare ogni tabella nella relativa tabella di destinazione DynamoDB. AWS DMS Il valore predefinito è 0 (a thread singolo). Il valore massimo è 200. Puoi chiedere che questo limite massimo venga aumentato.Nota
DMS assegna ogni segmento di una tabella al proprio thread per il caricamento. Pertanto, impostare
ParallelLoadThreadsal numero massimo di segmenti specificati dall'utente per una tabella nella sorgente. -
ParallelLoadBufferSize: utilizza questa opzione per specificare il numero massimo di record da archiviare nel buffer utilizzato dai thread di caricamento parallelo per caricare i dati nella destinazione DynamoDB. Il valore predefinito è 50. Il valore massimo è 1.000. Utilizzare questo parametro conParallelLoadThreads;ParallelLoadBufferSizeè valido solo quando è presente più di un thread. -
Table-mapping impostazioni per singole tabelle: utilizza
table-settingsle regole per identificare le singole tabelle dall'origine che desideri caricare in parallelo. Inoltre utilizza queste regole per specificare come segmentare le righe di ciascuna tabella multithreaded per il caricamento. Per ulteriori informazioni, consulta Regole e operazioni delle impostazioni di tabella e raccolta.
Nota
Quando si AWS DMS impostano i valori dei parametri DynamoDB per un'attività di migrazione, il valore predefinito del parametro Read Capacity Units (RCU) è impostato su 200.
Viene inoltre impostato il valore del parametro WCU (Write Capacity Unit, Unità di capacità in scrittura), ma tale valore dipende da diverse altre impostazioni:
-
Il valore predefinito per il parametro WCU è 200.
-
Se l'attività
ParallelLoadThreadsè impostata su un valore superiore a 1 (il valore di default è 0), allora il parametro WCU è impostato su 200 volte il valoreParallelLoadThreads. Le tariffe AWS DMS di utilizzo standard si applicano alle risorse utilizzate.
Migrazione da un database relazionale a una tabella DynamoDB
AWS DMS supporta la migrazione dei dati verso tipi di dati scalari DynamoDB. Durante la migrazione da un database relazionale, ad esempio Oracle o MySQL, a DynamoDB, potresti voler ristrutturare il modo in cui vengono archiviati i dati.
Attualmente AWS DMS supporta la ristrutturazione da singola tabella a tabella singola in base agli attributi di tipo scalare DynamoDB. Se esegui la migrazione dei dati in DynamoDB da una tabella di database relazionale, prelevi i dati da una tabella e li riformatti in attributi del tipo di dati scalare di DynamoDB. Questi attributi possono accettare i dati provenienti da più colonne e puoi mappare direttamente una colonna a un attributo.
AWS DMS supporta i seguenti tipi di dati scalari DynamoDB:
-
Stringa
-
Numero
-
Booleano
Nota
I dati NULL dall'origine vengono ignorati sulla destinazione.
Prerequisiti per l'utilizzo di DynamoDB come destinazione per AWS Database Migration Service
Prima di iniziare a utilizzare un database DynamoDB come destinazione, assicurati AWS DMS di creare un ruolo IAM. Questo ruolo IAM dovrebbe consentire di AWS DMS assumere e concedere l'accesso alle tabelle DynamoDB in cui viene effettuata la migrazione. Nella seguente policy IAM viene mostrato il set minimo di autorizzazioni di accesso.
Il ruolo utilizzato per la migrazione a DynamoDB deve disporre delle seguenti autorizzazioni.
Limitazioni nell'utilizzo di DynamoDB come destinazione per AWS Database Migration Service
Le seguenti limitazioni si applicano quando si utilizza DynamoDB come destinazione:
-
DynamoDB limita la precisione del tipo di dati Number a 38 posizioni. Archivia tutti i tipi di dati con una precisione superiore come String. Devi specificare esplicitamente questo valore mediante la caratteristica di mappatura degli oggetti.
-
Poiché DynamoDB non dispone di un tipo di dati Date, i dati che utilizzano il tipo di dati Date vengono convertiti in stringhe.
-
DynamoDB non consente gli aggiornamenti degli attributi di chiave primaria. Questa restrizione è importante quando si utilizza la replica continua con l'acquisizione dei dati di modifica (CDC), perché può causare la presenza di dati indesiderati nella destinazione. A seconda del tipo di mappatura degli oggetti, un'operazione CDC che aggiorna la chiave primaria può eseguire una delle due seguenti azioni: Può restituire un errore o inserire un nuovo elemento con la chiave primaria aggiornata e dati incompleti.
-
AWS DMS supporta solo la replica di tabelle con chiavi primarie non composite. L'eccezione è se si specifica una mappatura degli oggetti per la tabella di destinazione con una chiave di partizione personalizzata o una chiave di ordinamento o con entrambe.
-
AWS DMS non supporta i dati LOB a meno che non si tratti di un CLOB. AWS DMS converte i dati CLOB in una stringa DynamoDB durante la migrazione dei dati.
-
Quando si utilizza DynamoDB come destinazione, solo la tabella di controllo Apply Exceptions (
dmslogs.awsdms_apply_exceptions) è supportata. Per ulteriori informazioni sulle tabelle di controllo, consultare Impostazioni delle attività delle tabelle di controllo. AWS DMS non supporta l'impostazione delle attività
TargetTablePrepMode=TRUNCATE_BEFORE_LOADper DynamoDB come destinazione.AWS DMS non supporta l'impostazione delle attività
TaskRecoveryTableEnabledper DynamoDB come destinazione.BatchApplynon è supportato per un endpoint DynamoDB.-
AWS DMS non può migrare gli attributi i cui nomi corrispondono a parole riservate in DynamoDB. Per ulteriori informazioni, consulta le parole riservate in DynamoDB nella Amazon DynamoDB Developer Guide.
Utilizzo della mappatura degli oggetti per la migrazione dei dati a DynamoDB
AWS DMS utilizza regole di mappatura delle tabelle per mappare i dati dalla tabella DynamoDB di origine alla tabella DynamoDB di destinazione. Per mappare i dati a una destinazione DynamoDB, è necessario utilizzare una regola di mappatura delle tabelle denominata object-mapping. La mappatura degli oggetti consente di definire i nomi degli attributi e i dati da migrare. Quando utilizzi la mappatura degli oggetti, devi disporre di regole di selezione.
DynamoDB non dispone di una struttura preimpostata oltre a una chiave di partizione e una chiave di ordinamento opzionale. Se hai una chiave primaria non composita, la usa. AWS DMS Se disponi di una chiave primaria composita o desideri utilizzare una chiave di ordinamento, definisci tali chiavi e gli altri attributi nella tabella DynamoDB di destinazione.
Per creare una regola di mappatura degli oggetti, è necessario specificare il parametro rule-type come object-mapping. Questa regola specifica il tipo di mappatura degli oggetti da utilizzare.
Di seguito è riportata la struttura per la regola:
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" }, "target-table-name": "<table_name>" } ] }
AWS DMS attualmente supporta map-record-to-record e è map-record-to-document l'unico valore valido per il rule-action parametro. Questi valori specificano AWS DMS cosa viene fatto di default ai record che non sono esclusi dall'elenco degli exclude-columns attributi. Questi valori non influiscono in alcun modo sulle mappature degli attributi.
-
Puoi utilizzare
map-record-to-recordper la migrazione da un database relazionale a DynamoDB. Questo parametro utilizza la chiave primaria dal database relazionale come chiave di partizione in DynamoDB e crea un attributo per ogni colonna nel database di origine. Quando viene utilizzatomap-record-to-record, per qualsiasi colonna della tabella di origine non elencata nell'elencoexclude-columnsdegli attributi, AWS DMS crea un attributo corrispondente sull'istanza DynamoDB di destinazione. Questa operazione avviene indipendentemente dal fatto che tale colonna di origine venga utilizzata o meno in una mappatura degli attributi. -
Puoi utilizzare
map-record-to-documentper inserire le colonne origine in una singola mappa piana DynamoDB nella destinazione utilizzando il nome di attributo "_doc". Quando viene utilizzatomap-record-to-document, AWS DMS inserisce i dati in un unico attributo di mappa DynamoDB flat sull'origine. Questo attributo è denominato "_doc". Questo posizionamento si applica a qualsiasi colonna della tabella di origine non elencata nell'elenco di attributiexclude-columns.
Uno dei modi per comprendere la differenza tra i parametri rule-action, map-record-to-record e map-record-to-document è di osservare i due parametri in azione. Per questo esempio, supponiamo che tu stia iniziando con una riga di tabella del database relazionale con la struttura e i dati seguenti:

Per eseguire la migrazione di queste informazioni a DynamoDB, crei le regole per mappare i dati in una voce di tabella DynamoDB. Nota le colonne elencate per il parametro exclude-columns. Queste colonne non sono mappate direttamente alla destinazione. La mappatura degli attributi viene invece utilizzata per combinare i dati in nuovi elementi, ad esempio dove FirstNamee LastNamevengono raggruppati insieme per diventare CustomerNameil target DynamoDB. NickNamee il reddito non è escluso.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
Utilizzando il rule-action parametro map-record-to-record, i dati NickNamee le entrate vengono mappati su elementi con lo stesso nome nel target DynamoDB.
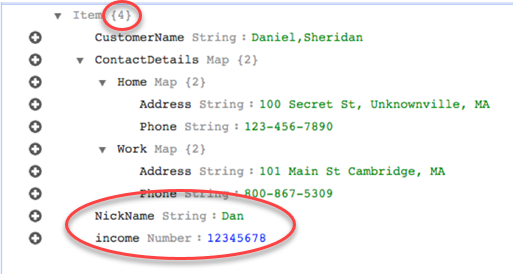
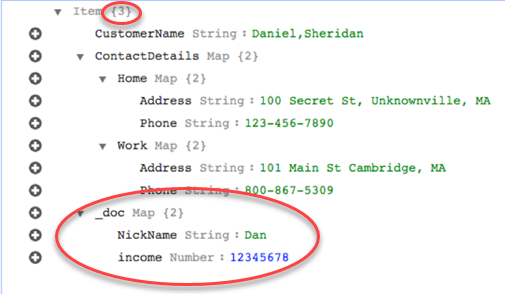
Tuttavia, supponi di utilizzare le stesse regole ma di modificare il parametro rule-action in map-record-to-document. In questo caso, le colonne non elencate nel exclude-columns parametro NickNamee le entrate vengono mappate su un elemento _doc.
Utilizzo di espressioni di condizioni personalizzate con mappatura degli oggetti
Puoi utilizzare una funzionalità di DynamoDB denominata espressioni condizionali per gestire i dati scritti in una tabella DynamoDB. Per ulteriori informazioni sulle espressioni condizionali in DynamoDB, consulta Espressioni di condizione.
Un membro di espressione condizionale è costituito dai seguenti elementi:
-
un'espressione (obbligatoria)
-
valori degli attributi di espressione (obbligatori). Specifica una struttura json di DynamoDB del valore dell'attributo. Questo è utile per confrontare un attributo con un valore in DynamoDB che potresti non conoscere fino al runtime. È possibile definire il valore di un attributo di espressione come segnaposto per un valore effettivo.
-
nomi degli attributi di espressione (obbligatori). Questo aiuta a evitare potenziali conflitti con parole riservate di DynamoDB, nomi di attributo contenenti caratteri speciali e simili.
-
opzioni per i casi in cui utilizzare l'espressione condizionale (opzionali). I valori predefiniti sono apply-during-cdc = false e apply-during-full-load = true
Di seguito è riportata la struttura per la regola:
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
L'esempio seguente evidenzia le sezioni utilizzate per l'espressione condizionale.

Utilizzo della mappatura degli attributi con la mappatura degli oggetti
La mappatura degli attributi consente di specificare una stringa di modello mediante i nomi di colonna di origine per ristrutturare i dati sulla destinazione. Non viene eseguita alcuna formattazione oltre a quella che l'utente specifica nel modello.
L'esempio seguente mostra la struttura del database di origine e la struttura desiderata della destinazione DynamoDB. In primo luogo è riportata la struttura dell'origine, in questo caso un database Oracle, quindi la struttura dei dati in DynamoDB. Al termine dell'esempio, il file JSON viene utilizzato per creare la struttura di destinazione desiderata.
La struttura dei dati Oracle è la seguente:
| FirstName | LastName | StoreId | HomeAddress | HomePhone | WorkAddress | WorkPhone | DateOfBirth |
|---|---|---|---|---|---|---|---|
| Chiave primaria | N/A | ||||||
| Randy | Marsh | 5 | 221B Baker Street | 1234567890 | 31 Spooner Street, Quahog | 9876543210 | 02/29/1988 |
La struttura dei dati DynamoDB è la seguente:
| CustomerName | StoreId | ContactDetails | DateOfBirth |
|---|---|---|---|
| Chiave di partizione | Chiave ordinamento | N/A | |
|
|
|
|
Il seguente file JSON mostra la mappatura degli oggetti e la mappatura delle colonne utilizzate per ottenere la struttura DynamoDB:
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ] }
Un altro modo per utilizzare la mappatura delle colonne consiste nell'utilizzo del formato DynamoDB come tipo di documento. Il seguente codice di esempio utilizza dynamodb-map come attribute-sub-type per la mappatura degli attributi.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
In alternativa a dynamodb-map, è possibile utilizzare dynamodb-list come attribute-sub-type per la mappatura degli attributi, come mostrato nell'esempio seguente.
{ "target-attribute-name": "ContactDetailsList", "attribute-type": "document", "attribute-sub-type": "dynamodb-list", "value": { "L": [ { "N": "${FirstName}" }, { "N": "${HomeAddress}" }, { "N": "${HomePhone}" }, { "N": "${WorkAddress}" }, { "N": "${WorkPhone}" } ] } }
Esempio 1: utilizzo della mappatura degli attributi con la mappatura degli oggetti
L'esempio seguente migra i dati da due tabelle di database MySQL, nfl_data e sport_team, a due tabelle DynamoDB denominate NFLTeams e. SportTeams Di seguito sono riportati la struttura delle tabelle e il file JSON utilizzato per mappare i dati dalle tabelle di database MySQL alle tabelle DynamoDB.
Di seguito è riportata la struttura della tabella di database MySQL nfl_data:
mysql> desc nfl_data; +---------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+-------+ | Position | varchar(5) | YES | | NULL | | | player_number | smallint(6) | YES | | NULL | | | Name | varchar(40) | YES | | NULL | | | status | varchar(10) | YES | | NULL | | | stat1 | varchar(10) | YES | | NULL | | | stat1_val | varchar(10) | YES | | NULL | | | stat2 | varchar(10) | YES | | NULL | | | stat2_val | varchar(10) | YES | | NULL | | | stat3 | varchar(10) | YES | | NULL | | | stat3_val | varchar(10) | YES | | NULL | | | stat4 | varchar(10) | YES | | NULL | | | stat4_val | varchar(10) | YES | | NULL | | | team | varchar(10) | YES | | NULL | | +---------------+-------------+------+-----+---------+-------+
Di seguito è riportata la struttura della tabella di database MySQL sport_team:
mysql> desc sport_team; +---------------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------------------+--------------+------+-----+---------+----------------+ | id | mediumint(9) | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | | abbreviated_name | varchar(10) | YES | | NULL | | | home_field_id | smallint(6) | YES | MUL | NULL | | | sport_type_name | varchar(15) | NO | MUL | NULL | | | sport_league_short_name | varchar(10) | NO | | NULL | | | sport_division_short_name | varchar(10) | YES | | NULL | |
Di seguito sono riportate le regole di mappatura delle tabelle utilizzate per mappare le due tabelle alle due tabelle DynamoDB:
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${ stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams", "mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ] }
Di seguito è riportato l'output di esempio per la tabella DynamoDB NFLTeams:
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE" }
L'output di esempio per la tabella SportsTeams DynamoDB è mostrato di seguito:
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts" }
Tipi di dati di destinazione per DynamoDB
L'endpoint DynamoDB per AWS DMS supporta la maggior parte dei tipi di dati DynamoDB. La tabella seguente mostra i tipi di dati di AWS DMS destinazione di Amazon supportati durante l'utilizzo AWS DMS e la mappatura predefinita AWS DMS dei tipi di dati.
Per ulteriori informazioni sui tipi di AWS DMS dati, consultaTipi di dati per AWS Database Migration Service.
Quando AWS DMS migriamo dati da database eterogenei, mappiamo i tipi di dati dal database di origine a tipi di dati intermedi denominati tipi di dati. AWS DMS Mappiamo quindi i tipi di dati intermedi ai tipi di dati di destinazione. La tabella seguente mostra ogni tipo di AWS DMS dati e il tipo di dati a cui è mappato in DynamoDB:
| AWS DMS tipo di dati | Tipo di dati DynamoDB |
|---|---|
|
Stringa |
Stringa |
|
WString |
Stringa |
|
Booleano |
Booleano |
|
Data |
Stringa |
|
DateTime |
Stringa |
|
INT1 |
Numero |
|
INT2 |
Numero |
|
INT4 |
Numero |
|
INT8 |
Numero |
|
Numerico |
Numero |
|
Real4 |
Numero |
|
Real8 |
Numero |
|
UINT1 |
Numero |
|
UINT2 |
Numero |
|
UINT4 |
Numero |
| UINT8 | Numero |
| CLOB | Stringa |
