Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cluster elastici Amazon DocumentDB: come funzionano
Gli argomenti di questa sezione forniscono informazioni sui meccanismi e le funzioni alla base dei cluster elastici di Amazon DocumentDB.
Argomenti
Sharding elastico dei cluster di Amazon DocumentDB
I cluster elastici di Amazon DocumentDB utilizzano lo sharding basato su hash per partizionare i dati su un sistema di storage distribuito. Lo sharding, noto anche come partizionamento, divide set di dati di grandi dimensioni in piccoli set di dati su più nodi, consentendoti di scalare il database oltre i limiti di scalabilità verticale. I cluster elastici utilizzano la separazione, o «disaccoppiamento», di elaborazione e storage in Amazon DocumentDB, consentendoti di scalare indipendentemente l'uno dall'altro. Anziché ripartizionare le raccolte spostando piccoli blocchi di dati tra i nodi di calcolo, i cluster elastici copiano i dati in modo efficiente all'interno del sistema di storage distribuito.
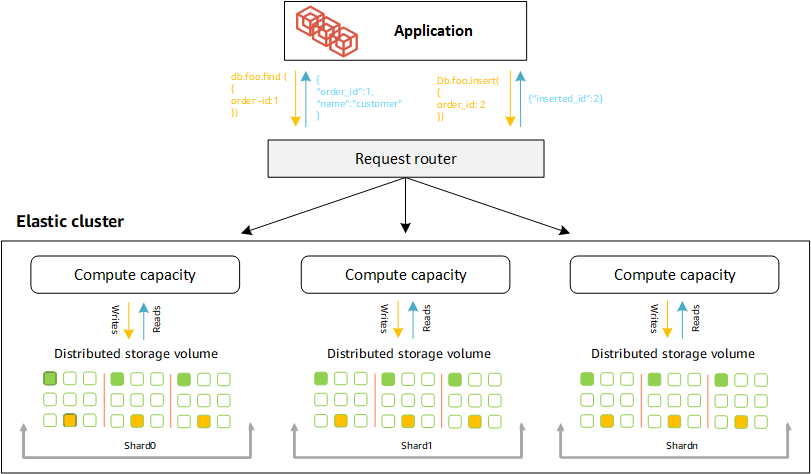
Definizioni degli shard
Definizioni della nomenclatura degli shard:
Shard: uno shard fornisce il calcolo per un cluster elastico. Avrà una singola istanza di writer e da 0 a 15 repliche di lettura. Per impostazione predefinita, uno shard avrà due istanze: una writer e una replica a lettura singola. È possibile configurare un massimo di 32 shard e ogni istanza di shard può avere un massimo di 64 vCPU.
Chiave shard: una chiave shard è un campo obbligatorio nei documenti JSON in raccolte frammentate utilizzate dai cluster elastici per distribuire il traffico di lettura e scrittura sullo shard corrispondente.
Raccolta condivisa: una raccolta condivisa è una raccolta i cui dati sono distribuiti su un cluster elastico in partizioni di dati.
Partizione: una partizione è una parte logica di dati suddivisi. Quando si crea una raccolta condivisa, i dati vengono organizzati automaticamente in partizioni all'interno di ogni frammento in base alla chiave dello shard. Ogni shard ha più partizioni.
Distribuzione dei dati tra shard configurati
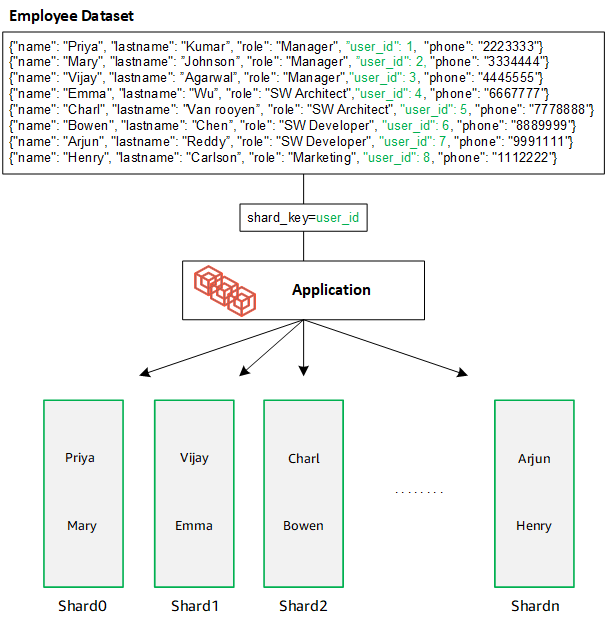
Crea una chiave shard con molti valori univoci. Una buona shard key partizionerà i dati in modo uniforme tra gli shard sottostanti, offrendo al carico di lavoro la velocità di trasmissione e le prestazioni migliori. L'esempio seguente sono i dati relativi ai nomi dei dipendenti che utilizzano una chiave shard denominata «user_id»:
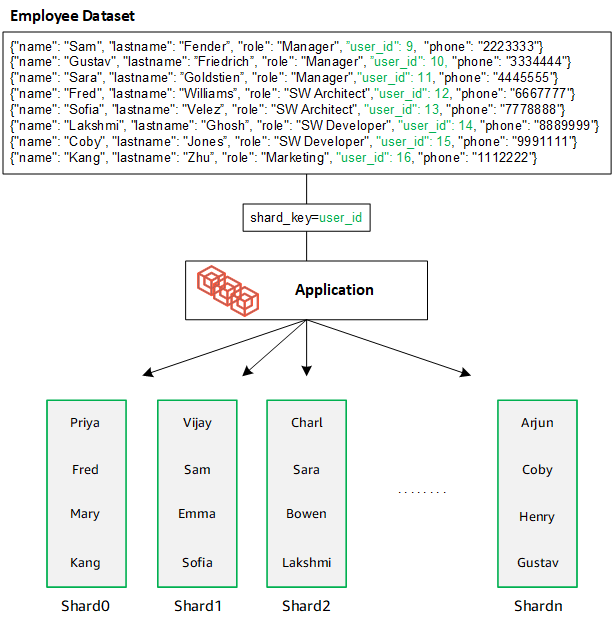
DocumentDB utilizza l'hash sharding per partizionare i dati tra gli shard sottostanti. I dati aggiuntivi vengono inseriti e distribuiti nello stesso modo:
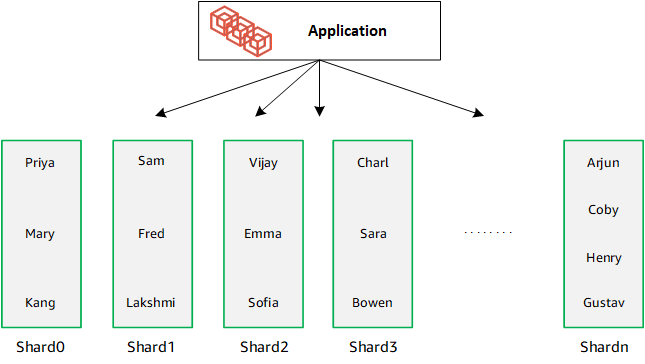
Quando ridimensioni il database aggiungendo shard aggiuntivi, Amazon DocumentDB ridistribuisce automaticamente i dati:
Migrazione elastica dei cluster
Amazon DocumentDB supporta la migrazione di dati condivisi MongoDB in cluster elastici. Sono supportati metodi di migrazione offline, online e ibridi. Per ulteriori informazioni, consulta Migrazione ad Amazon DocumentDB.
Scalabilità elastica dei cluster
I cluster elastici di Amazon DocumentDB offrono la possibilità di aumentare il numero di shard (scalabilità orizzontale) nel cluster elastico e il numero di vCPU applicate a ciascun shard (scalabilità verticale). È inoltre possibile ridurre il numero di shard e la capacità di elaborazione (vCPU) in base alle esigenze.
Per le migliori pratiche di scalabilità, consulta. Scalabilità dei cluster elastici
Nota
Cluster-level è disponibile anche il ridimensionamento. Per ulteriori informazioni, consulta Scalabilità dei cluster Amazon DocumentDB.
Affidabilità elastica del cluster
Amazon DocumentDB è progettato per essere affidabile, durevole e resistente ai guasti. Per migliorare la disponibilità, i cluster elastici distribuiscono due nodi per shard posizionati in diverse zone di disponibilità. Amazon DocumentDB include diverse funzionalità automatiche che lo rendono una soluzione di database affidabile. Per ulteriori informazioni, consulta Affidabilità di Amazon DocumentDB.
Archiviazione e disponibilità di cluster elastici
I dati di Amazon DocumentDB sono archiviati in un volume cluster, che è un singolo volume virtuale che utilizza unità a stato solido (SSD). Un volume cluster è composto da sei copie dei dati, che vengono replicate automaticamente su più zone di disponibilità in una singola regione. AWS Questa replica contribuisce a garantire l'estrema durata dei tuoi dati e a ridurre il rischio di perdita dei dati. Consente inoltre di assicurare che il cluster non sia più disponibile durante un failover perché le copie dei dati sono già presenti in altre zone di disponibilità. Per ulteriori dettagli sullo storage, l'alta disponibilità e la replica, vedere. Amazon DocumentDB: come funziona
Differenze funzionali tra Amazon DocumentDB 4.0 e cluster elastici
Esistono le seguenti differenze funzionali tra Amazon DocumentDB 4.0 e i cluster elastici.
I risultati provengono da
topecollStatssono partizionati per frammenti. Per le raccolte suddivise, i dati vengono distribuiti tra più partizioni e icollStatsreport vengono aggregati dalle partizioni.collScansLe statistiche di raccolta da
topecollStatsper le raccolte suddivise vengono reimpostate quando viene modificato il numero di frammenti del cluster.Il ruolo integrato di backup ora supporta.
serverStatusAzione: gli sviluppatori e le applicazioni con ruolo di backup possono raccogliere statistiche sullo stato del cluster Amazon DocumentDB.Il
SecondaryDelaySecscampo viene sostituitoslaveDelayinreplSetGetConfigoutput.Il
hellocomando sostituisceisMaster:hellorestituisce un documento che descrive il ruolo del cluster elastico.L'
$elemMatchoperatore nei cluster elastici corrisponde solo ai documenti nel primo livello di nidificazione di un array. In Amazon DocumentDB 4.0, l'operatore attraversa tutti i livelli prima di restituire i documenti corrispondenti. Esempio:
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
La proiezione «$» in Amazon DocumentDB 4.0 restituisce tutti i documenti con tutti i campi. Con i cluster elastici, il
findcomando con una proiezione «$» restituisce documenti che corrispondono al parametro di query contenente solo il campo corrispondente alla proiezione «$».Nei cluster elastici, i
findcomandi con$regexparametri di$optionsquery restituiscono un errore: «Impossibile impostare opzioni sia in $regex che in $options».
Con i cluster elastici,
$indexOfCPora restituisce «-1" quando:la sottostringa non si trova in, o
string expressionstartè un numero maggiore diend, ostartè un numero maggiore della lunghezza in byte della stringa.
In Amazon DocumentDB 4.0,
$indexOfCPrestituisce «0" quando lastartposizione è un numero maggioreendo la lunghezza in byte della stringa.Con i cluster elastici, le operazioni di proiezione
_id fields, ad esempio{"_id.nestedField" : 1}, restituiscono documenti che includono solo il campo proiettato. Nel frattempo, in Amazon DocumentDB 4.0, i comandi di proiezione di campo annidati non filtrano alcun documento.
