Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cluster Autoscaler
Suggerimento
Esplora le
Panoramica di
Kubernetes Cluster Autoscaler è una popolare soluzione Cluster Autoscaling gestita.DesiredReplicas campo dei tuoi gruppi di Auto Scaling EC2.
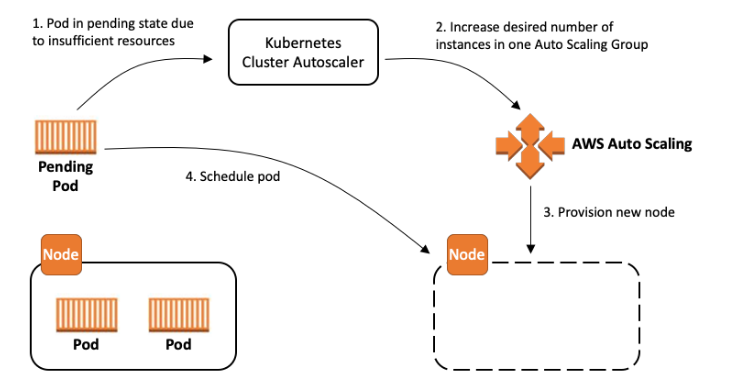
Questa guida fornirà un modello mentale per configurare Cluster Autoscaler e scegliere il miglior set di compromessi per soddisfare i requisiti della tua organizzazione. Sebbene non esista un'unica configurazione ottimale, esiste una serie di opzioni di configurazione che consentono di scendere a compromessi tra prestazioni, scalabilità, costi e disponibilità. Inoltre, questa guida fornirà suggerimenti e best practice per ottimizzare la configurazione per AWS.
Glossario
La seguente terminologia verrà utilizzata frequentemente in questo documento. Questi termini possono avere un significato ampio, ma sono limitati alle definizioni riportate di seguito ai fini del presente documento.
La scalabilità si riferisce alle prestazioni di Cluster Autoscaler all'aumentare del numero di pod e nodi del cluster Kubernetes. Quando vengono raggiunti i limiti di scalabilità, le prestazioni e la funzionalità di Cluster Autoscaler diminuiscono. Poiché Cluster Autoscaler supera i limiti di scalabilità, non può più aggiungere o rimuovere nodi nel cluster.
Le prestazioni si riferiscono alla rapidità con cui Cluster Autoscaler è in grado di prendere ed eseguire decisioni di scalabilità. Un Cluster Autoscaler dalle prestazioni perfette prenderebbe istantaneamente una decisione e attiverebbe un'azione di scalabilità in risposta a stimoli, ad esempio se un pod diventasse non programmabile.
La disponibilità significa che i pod possono essere programmati rapidamente e senza interruzioni. Ciò include quando è necessario pianificare i pod appena creati e quando un nodo ridimensionato interrompe tutti i pod rimanenti programmati.
Il costo è determinato dalla decisione alla base degli eventi di scalabilità orizzontale e scalabile in base agli eventi. Le risorse vengono sprecate se un nodo esistente viene sottoutilizzato o viene aggiunto un nuovo nodo troppo grande per i pod in entrata. A seconda del caso d'uso, la chiusura anticipata dei pod può comportare dei costi dovuti a una decisione aggressiva di ridimensionamento.
I gruppi di nodi sono un concetto astratto di Kubernetes per un gruppo di nodi all'interno di un cluster. Non è una vera risorsa Kubernetes, ma esiste come astrazione in Cluster Autoscaler, Cluster API e altri componenti. I nodi all'interno di un gruppo di nodi condividono proprietà come etichette e taint, ma possono essere costituiti da più zone di disponibilità o tipi di istanze.
I gruppi di Auto Scaling EC2 possono essere utilizzati come implementazione dei gruppi di nodi su EC2. I gruppi di Auto Scaling EC2 sono configurati per avviare istanze che si uniscono automaticamente ai rispettivi cluster Kubernetes e applicare etichette e tag alla risorsa Node corrispondente nell'API Kubernetes.
I gruppi di nodi gestiti EC2 sono un'altra implementazione dei gruppi di nodi su EC2. Eliminano la complessità della configurazione manuale di EC2 Autoscaling Scaling Groups e forniscono funzionalità di gestione aggiuntive come l'aggiornamento della versione del nodo e la chiusura graduale dei nodi.
Funzionamento del Cluster Autoscaler
Il Cluster Autoscaler viene in genere installato come implementazione
Verifica che:
-
La versione di Cluster Autoscaler corrisponde alla versione del Cluster. La compatibilità tra versioni non è testata
o supportata. -
Auto Discovery
è abilitato, a meno che non esistano casi d'uso avanzati specifici che impediscono l'uso di questa modalità.
Utilizza l'accesso meno privilegiato al ruolo IAM
Quando si utilizza l'Auto Discoveryautoscaling:SetDesiredCapacity e autoscaling:TerminateInstanceInAutoScalingGroup ai gruppi di Auto Scaling che hanno come ambito il cluster corrente.
Ciò impedirà a un Cluster Autoscaler in esecuzione in un cluster di modificare i gruppi di nodi in un cluster diverso anche se l'--node-group-auto-discoveryargomento non è stato limitato ai gruppi di nodi del cluster utilizzando i tag (ad esempio). k8s.io/cluster-autoscaler/<cluster-name>
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "autoscaling:SetDesiredCapacity", "autoscaling:TerminateInstanceInAutoScalingGroup" ], "Resource": "*", "Condition": { "StringEquals": { "aws:ResourceTag/k8s.io/cluster-autoscaler/enabled": "true", "aws:ResourceTag/k8s.io/cluster-autoscaler/my-cluster": "owned" } } }, { "Effect": "Allow", "Action": [ "autoscaling:DescribeAutoScalingGroups", "autoscaling:DescribeAutoScalingInstances", "autoscaling:DescribeLaunchConfigurations", "autoscaling:DescribeScalingActivities", "autoscaling:DescribeTags", "ec2:DescribeImages", "ec2:DescribeInstanceTypes", "ec2:DescribeLaunchTemplateVersions", "ec2:GetInstanceTypesFromInstanceRequirements", "eks:DescribeNodegroup" ], "Resource": "*" } ] }
Configurazione dei gruppi di nodi
Una scalabilità automatica efficace inizia con la corretta configurazione di un set di gruppi di nodi per il cluster. La selezione del giusto set di gruppi di nodi è fondamentale per massimizzare la disponibilità e ridurre i costi dei carichi di lavoro. AWS implementa i gruppi di nodi utilizzando i gruppi di Auto Scaling EC2, che sono flessibili per un gran numero di casi d'uso. Tuttavia, Cluster Autoscaler formula alcune ipotesi sui gruppi di nodi. Mantenere le configurazioni del gruppo EC2 Auto Scaling coerenti con questi presupposti ridurrà al minimo i comportamenti indesiderati.
Verifica che:
-
Ogni nodo in un gruppo di nodi ha proprietà di pianificazione identiche, come Labels, Taints e Resources.
-
Infatti MixedInstancePolicies, i tipi di istanza devono avere la stessa forma per CPU, memoria e GPU
-
Il primo tipo di istanza specificato nella politica verrà utilizzato per simulare la pianificazione.
-
Se la politica prevede tipi di istanze aggiuntivi con più risorse, le risorse potrebbero essere sprecate dopo la scalabilità orizzontale.
-
Se la tua policy prevede tipi di istanze aggiuntivi con meno risorse, i pod potrebbero non riuscire a pianificare le istanze.
-
-
I gruppi di nodi con molti nodi sono preferiti rispetto a molti gruppi di nodi con meno nodi. Questo avrà il maggiore impatto sulla scalabilità.
-
Ove possibile, preferisci le funzionalità EC2 quando entrambi i sistemi forniscono supporto (ad esempio regioni,) MixedInstancePolicy
Nota
Consigliamo di utilizzare EKS Managed Node Groups. I gruppi di nodi gestiti sono dotati di potenti funzionalità di gestione, tra cui funzionalità per Cluster Autoscaler come l'individuazione automatica dei gruppi di EC2 Auto Scaling e la chiusura graduale dei nodi.
Ottimizzazione per prestazioni e scalabilità
Le manopole principali per ottimizzare la scalabilità di Cluster Autoscaler sono le risorse fornite al processo, l'intervallo di scansione dell'algoritmo e il numero di gruppi di nodi nel cluster. Esistono altri fattori coinvolti nella vera complessità di runtime di questo algoritmo, come la pianificazione, la complessità dei plugin e il numero di pod. Questi sono considerati parametri non configurabili in quanto sono naturali del carico di lavoro del cluster e non possono essere regolati facilmente.
Cluster Autoscaler carica in memoria lo stato dell'intero cluster, inclusi pod, nodi e gruppi di nodi. In ogni intervallo di scansione, l'algoritmo identifica i pod non programmabili e simula la pianificazione per ogni gruppo di nodi. La regolazione di questi fattori comporta diversi compromessi che devono essere attentamente considerati in base al caso d'uso.
Scalabilità automatica verticale del Cluster Autoscaler
Il modo più semplice per scalare Cluster Autoscaler su cluster più grandi consiste nell'aumentare le richieste di risorse per la sua implementazione. È necessario aumentare sia la memoria che la CPU per i cluster di grandi dimensioni, sebbene ciò vari in modo significativo a seconda delle dimensioni del cluster. L'algoritmo di scalabilità automatica archivia tutti i pod e i nodi in memoria, il che può comportare un ingombro di memoria superiore a un gigabyte in alcuni casi. L'aumento delle risorse viene in genere eseguito manualmente. Se ritieni che l'ottimizzazione costante delle risorse crei un onere operativo, prendi in considerazione l'utilizzo di Addon Resizer o Vertical Pod Autoscaler
Ridurre il numero di gruppi di nodi
Ridurre al minimo il numero di gruppi di nodi è un modo per garantire che Cluster Autoscaler continui a funzionare bene su cluster di grandi dimensioni. Questo può essere difficile per alcune organizzazioni che strutturano i propri gruppi di nodi per team o per applicazione. Sebbene questo sia completamente supportato dall'API Kubernetes, è considerato un anti-pattern di Cluster Autoscaler con ripercussioni sulla scalabilità. Esistono molte ragioni per utilizzare più gruppi di nodi (ad esempio Spot o GPU), ma in molti casi esistono design alternativi che ottengono lo stesso effetto utilizzando un numero limitato di gruppi.
Verifica che:
-
L'isolamento dei pod viene eseguito utilizzando i namespace anziché i gruppi di nodi.
-
Ciò potrebbe non essere possibile nei cluster multi-tenant a bassa attendibilità.
-
Pod ResourceRequests e ResourceLimits sono impostati correttamente per evitare conflitti di risorse.
-
I tipi di istanze più grandi si tradurranno in un imballaggio in contenitori più ottimale e in una riduzione del sovraccarico del sistema per i pod.
-
-
NodeTaints oppure NodeSelectors vengono utilizzati per programmare i pod come eccezione, non come regola.
-
Le risorse regionali sono definite come un singolo gruppo di Auto Scaling EC2 con più zone di disponibilità.
Riduzione dell'intervallo di scansione
Un intervallo di scansione basso (ad esempio 10 secondi) assicurerà che Cluster Autoscaler risponda il più rapidamente possibile quando i pod diventano non programmabili. Tuttavia, ogni scansione genera molte chiamate API all'API Kubernetes e alle API EC2 Auto Scaling Group o EKS Managed Node Group. Queste chiamate API possono comportare una limitazione della velocità o addirittura l'indisponibilità del servizio per Kubernetes Control Plane.
L'intervallo di scansione predefinito è di 10 secondi, ma su AWS, l'avvio di un nodo richiede molto più tempo per lanciare una nuova istanza. Ciò significa che è possibile aumentare l'intervallo senza aumentare significativamente il tempo complessivo di scalabilità. Ad esempio, se occorrono 2 minuti per avviare un nodo, la modifica dell'intervallo a 1 minuto comporterà un compromesso tra chiamate API ridotte di 6 volte e incrementi di scalabilità più lenti del 38%.
Condivisione tra gruppi di nodi
Il Cluster Autoscaler può essere configurato per funzionare su un set specifico di gruppi di nodi. Utilizzando questa funzionalità, è possibile distribuire più istanze di Cluster Autoscaler, ognuna configurata per funzionare su un diverso set di gruppi di nodi. Questa strategia consente di utilizzare un numero arbitrario di gruppi di nodi, scambiando i costi con la scalabilità. Ti consigliamo di utilizzarla solo come ultima risorsa per migliorare le prestazioni.
Il Cluster Autoscaler non è stato originariamente progettato per questa configurazione, quindi presenta alcuni effetti collaterali. Poiché gli shard non comunicano, è possibile che più autoscaler tentino di pianificare un pod non programmabile. Ciò può comportare una scalabilità non necessaria di più gruppi di nodi. Questi nodi aggiuntivi verranno ridimensionati dopo ilscale-down-delay.
metadata: name: cluster-autoscaler namespace: cluster-autoscaler-1 ... --nodes=1:10:k8s-worker-asg-1 --nodes=1:10:k8s-worker-asg-2 --- metadata: name: cluster-autoscaler namespace: cluster-autoscaler-2 ... --nodes=1:10:k8s-worker-asg-3 --nodes=1:10:k8s-worker-asg-4
Verifica che:
-
Ogni shard è configurato per puntare a un set unico di gruppi di Auto Scaling EC2
-
Ogni shard viene distribuito in un namespace separato per evitare conflitti elettorali tra i leader
Ottimizzazione dei costi e della disponibilità
Spot Instances
Puoi utilizzare le istanze Spot nei tuoi gruppi di nodi e risparmiare fino al 90% sul prezzo su richiesta. Con un compromesso, le istanze Spot possono essere interrotte in qualsiasi momento quando EC2 ha bisogno di recuperare la capacità. Si verificheranno errori di capacità insufficiente quando il gruppo EC2 Auto Scaling non può aumentare a causa della mancanza di capacità disponibile. Massimizzare la diversità selezionando più famiglie di istanze può aumentare le possibilità di ottenere la scalabilità desiderata attingendo a molti pool di capacità Spot e ridurre l'impatto delle interruzioni delle istanze Spot sulla disponibilità del cluster. Le policy di istanza miste con istanze spot sono un ottimo modo per aumentare la diversità senza aumentare il numero di gruppi di nodi. Tieni presente che se hai bisogno di risorse garantite, utilizza le On-Demand istanze anziché le istanze Spot.
È fondamentale che tutti i tipi di istanza abbiano una capacità di risorse simile durante la configurazione delle politiche per istanze miste. Il simulatore di pianificazione di Autoscaler utilizza il primo di. InstanceType MixedInstancePolicy Se i tipi di istanza successivi sono più grandi, le risorse potrebbero essere sprecate dopo un ampliamento. Se sono più piccoli, i pod potrebbero non riuscire a programmarsi sulle nuove istanze a causa della capacità insufficiente. Ad esempio, le istanze M4, M5, M5a e M5n hanno tutte quantità di CPU e memoria simili e sono ottime candidate per un. MixedInstancePolicy Lo strumento EC2 Instance Selector può aiutarti a identificare tipi di istanze
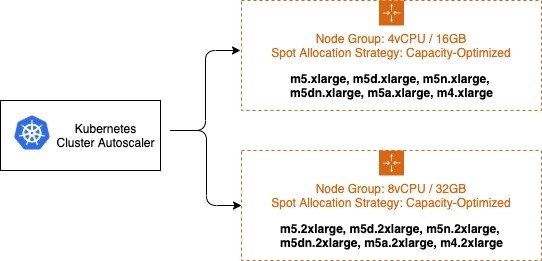
Si consiglia di isolare On-Demand e individuare la capacità in gruppi di Auto Scaling EC2 separati. Questa soluzione è preferibile rispetto all'utilizzo di una strategia di capacità di base, poiché le proprietà di pianificazione sono fondamentalmente diverse. Poiché le istanze Spot vengono interrotte in qualsiasi momento (quando EC2 ha bisogno di recuperare la capacità), gli utenti spesso alterano i nodi presvuotabili, richiedendo un'esplicita tolleranza dei pod rispetto al comportamento di prelazione. Queste contaminazioni determinano proprietà di pianificazione diverse per i nodi, quindi devono essere separati in più gruppi di Auto Scaling EC2.
Cluster Autoscaler si basa sul concetto di Expander--expander=least-waste è una buona impostazione predefinita per uso generale e, se intendi utilizzare più gruppi di nodi per la diversificazione delle istanze Spot (come descritto nell'immagine precedente), potrebbe aiutare a ottimizzare ulteriormente i costi dei gruppi di nodi scalando il gruppo che sarebbe meglio utilizzato dopo l'attività di scalabilità.
Assegnazione di priorità a un gruppo di nodi /ASG
È inoltre possibile configurare la scalabilità automatica basata sulla priorità utilizzando l'espansore Priority. --expander=priorityconsente al cluster di dare priorità a un gruppo di nodi /ASG e, se non è in grado di scalare per qualsiasi motivo, sceglierà il gruppo di nodi successivo nell'elenco con priorità. Ciò è utile in situazioni in cui, ad esempio, si desidera utilizzare i tipi di istanza P3 perché la loro GPU offre prestazioni ottimali per il carico di lavoro, ma come seconda opzione è possibile utilizzare anche i tipi di istanze P2.
apiVersion: v1 kind: ConfigMap metadata: name: cluster-autoscaler-priority-expander namespace: kube-system data: priorities: |- 10: - .*p2-node-group.* 50: - .*p3-node-group.*
Cluster Autoscaler cercherà di scalare il gruppo Auto Scaling EC2 corrispondente al nome p3-node-group. Se questa operazione non riesce all'interno--max-node-provision-time, tenterà di scalare un gruppo di Auto Scaling EC2 corrispondente al nome p2-node-group. Questo valore predefinito è di 15 minuti e può essere ridotto per una selezione del gruppo di nodi più reattiva, tuttavia, se il valore è troppo basso, può causare scale-out non necessari.
Overprovisioning
Cluster Autoscaler riduce al minimo i costi garantendo che i nodi vengano aggiunti al cluster solo quando necessario e rimossi quando non vengono utilizzati. Ciò influisce in modo significativo sulla latenza di implementazione perché molti pod saranno costretti ad attendere la scalabilità di un nodo prima di poter essere pianificati. I nodi possono richiedere più minuti per diventare disponibili, il che può aumentare la latenza di pianificazione del pod di un ordine di grandezza.
Questo può essere mitigato usando overprovisioning
L'overprovisioning presenta altri vantaggi meno evidenti. Senza overprovisioning, uno degli effetti collaterali di un cluster altamente utilizzato è che i pod prenderanno decisioni di pianificazione meno ottimali utilizzando la regola di Pod o Node Affinity. preferredDuringSchedulingIgnoredDuringExecution Un caso d'uso comune consiste nel separare i pod per un'applicazione ad alta disponibilità tra le zone di disponibilità utilizzando. AntiAffinity L'overprovisioning può aumentare in modo significativo la possibilità che sia disponibile un nodo della zona corretta.
La quantità di capacità sovradimensionata è una decisione aziendale attenta per l'organizzazione. Fondamentalmente, si tratta di un compromesso tra prestazioni e costi. Un modo per prendere questa decisione è determinare la frequenza media di scalabilità e dividerla per il tempo necessario per scalare un nuovo nodo. Ad esempio, se in media è necessario un nuovo nodo ogni 30 secondi ed EC2 impiega 30 secondi per fornire un nuovo nodo, un singolo nodo di overprovisioning assicurerà che sia sempre disponibile un nodo aggiuntivo, riducendo la latenza di pianificazione di 30 secondi al costo di una singola istanza EC2 aggiuntiva. Per migliorare le decisioni di pianificazione zonale, esegui il overprovisioning di un numero di nodi pari al numero di zone di disponibilità nel tuo gruppo di Auto Scaling EC2 per garantire che lo scheduler possa selezionare la zona migliore per i pod in entrata.
Previeni lo sfratto da Scale Down
Alcuni carichi di lavoro sono costosi da espellere. L'analisi dei big data, le attività di machine learning e i test runner alla fine verranno completati, ma devono essere riavviati se interrotti. Cluster Autoscaler tenterà di ridimensionare qualsiasi nodo al di sotto della soglia di scale-down-utilization-, interrompendo così tutti i pod rimanenti sul nodo. Ciò può essere evitato assicurando che i pod costosi da rimuovere siano protetti da un'etichetta riconosciuta da Cluster Autoscaler.
Verifica che:
-
I pod costosi da sfrattare hanno l'annotazione
cluster-autoscaler.kubernetes.io/safe-to-evict=false
Casi d'uso avanzati
Volumi EBS
Lo storage persistente è fondamentale per la creazione di applicazioni con stato, come database o cache distribuite. I volumi EBS
Verifica che:
-
Il bilanciamento del gruppo di nodi è abilitato impostando
balance-similar-node-groups=true. -
I gruppi di nodi sono configurati con impostazioni identiche, fatta eccezione per zone di disponibilità e volumi EBS diversi.
Co-Scheduling
I processi di formazione distribuiti di Machine Learning traggono vantaggio in modo significativo dalla latenza ridotta delle configurazioni dei nodi della stessa zona. Questi carichi di lavoro distribuiscono più pod in una zona specifica. Ciò può essere ottenuto impostando Pod Affinity per tutti i pod co-programmati o utilizzando Node Affinity. topologyKey: failure-domain.beta.kubernetes.io/zone Cluster Autoscaler ridimensionerà quindi una zona specifica per soddisfare le richieste. Potresti voler allocare più gruppi di Auto Scaling EC2, uno per zona di disponibilità, per abilitare il failover per l'intero carico di lavoro co-programmato.
Verifica che:
-
Il bilanciamento dei gruppi di nodi è abilitato impostando
balance-similar-node-groups=false -
Node Affinity and/or
Pod Preemption viene utilizzata quando i cluster includono gruppi di nodi regionali e zonali. -
Usa Node Affinity
per forzare o incoraggiare i pod regionali a evitare i gruppi di nodi zonali e viceversa. -
Se i pod zonali si collegano a gruppi di nodi regionali, ciò comporterà uno squilibrio della capacità dei pod regionali.
-
Se i tuoi carichi di lavoro zonali sono in grado di tollerare interruzioni e spostamenti, configura Pod Preemption per consentire ai pod
su scala regionale di forzare la priorità e la riprogrammazione in una zona meno contesa.
-
Acceleratori
Alcuni cluster sfruttano acceleratori hardware specializzati come la GPU. Durante la scalabilità orizzontale, il plug-in del dispositivo acceleratore può impiegare diversi minuti per pubblicizzare la risorsa nel cluster. Cluster Autoscaler ha simulato che questo nodo avrà l'acceleratore, ma finché l'acceleratore non sarà pronto e non aggiornerà le risorse disponibili del nodo, i pod in sospeso non possono essere programmati sul nodo. Ciò può comportare la ripetizione inutile della scalabilità orizzontale
Inoltre, i nodi con acceleratori e un elevato utilizzo della CPU o della memoria non verranno presi in considerazione per la riduzione, anche se l'acceleratore non è utilizzato. Questo comportamento può essere costoso a causa del costo relativo degli acceleratori. Al contrario, Cluster Autoscaler può applicare regole speciali per considerare i nodi da ridimensionare se hanno acceleratori non occupati.
Per garantire il comportamento corretto in questi casi, puoi configurare il kubelet sui nodi dell'acceleratore per etichettare il nodo prima che si unisca al cluster. Cluster Autoscaler utilizzerà questo selettore di etichette per attivare il comportamento ottimizzato dell'acceleratore.
Verifica che:
-
Il Kubelet per i nodi GPU è configurato con
--node-labels k8s.amazonaws.com/accelerator=$ACCELERATOR_TYPE -
I nodi con acceleratori aderiscono alla regola delle proprietà di pianificazione identica sopra indicata.
Scalabilità da 0
Cluster Autoscaler è in grado di scalare i gruppi di nodi da e verso lo zero, il che può portare a significativi risparmi sui costi. Rileva le risorse di CPU, memoria e GPU di un gruppo di Auto Scaling ispezionando quanto specificato InstanceType nel suo o. LaunchConfiguration LaunchTemplate Alcuni pod richiedono risorse aggiuntive come WindowsENI or o specifiche PrivateIPv4Address NodeSelectors o Taints che non possono essere scoperte tramite. LaunchConfiguration Cluster Autoscaler può tenere conto di questi fattori scoprendoli dai tag del gruppo Auto Scaling di EC2. Ad esempio:
Key: k8s.io/cluster-autoscaler/node-template/resources/$RESOURCE_NAME Value: 5 Key: k8s.io/cluster-autoscaler/node-template/label/$LABEL_KEY Value: $LABEL_VALUE Key: k8s.io/cluster-autoscaler/node-template/taint/$TAINT_KEY Value: NoSchedule
Nota
Tieni presente che quando si esegue la scalabilità a zero, la capacità viene restituita a EC2 e potrebbe non essere più disponibile in futuro.
Parametri aggiuntivi
Ci sono molte opzioni di configurazione che possono essere utilizzate per ottimizzare il comportamento e le prestazioni di Cluster Autoscaler. Un elenco completo dei parametri è disponibile su GitHub
| Parametro | Description | Predefinita |
|---|---|---|
|
intervallo di scansione |
Con quale frequenza il cluster viene rivalutato per aumentarne o ridurne la scalabilità |
10 secondi |
|
max-empty-bulk-delete |
Numero massimo di nodi vuoti che possono essere eliminati contemporaneamente. |
10 |
|
scale-down-delay-after-add |
Quanto tempo dopo la scalabilità verso l'alto, la valutazione della scala verso il basso riprende |
10 minuti |
|
ridimensionamento, ritardo dopo l'eliminazione |
Quanto tempo dopo l'eliminazione del nodo riprende la valutazione della scala verso il basso, il valore predefinito è scan-interval |
intervallo di scansione |
|
scale-down-delay-after-failure |
Quanto tempo dopo l'errore di scalabilità riprende la valutazione |
3 minuti |
|
ridimensionamento del tempo non necessario |
Per quanto tempo non deve essere necessario un nodo prima che sia idoneo per la scalabilità verso il basso |
10 minuti |
|
scalare verso il basso in tempo non pronto |
Per quanto tempo un nodo non pronto non deve essere necessario prima che sia idoneo per la scalabilità verso il basso |
20 minuti |
|
soglia di utilizzo di scala ridotta |
Livello di utilizzo del nodo, definito come la somma delle risorse richieste divisa per la capacità, al di sotto del quale è possibile considerare la possibilità di ridimensionare un nodo |
0,5 |
|
scale-down-non-empty-candidates-count |
Numero massimo di nodi non vuoti considerati in un'iterazione come candidati per lo scale-down with drain. Un valore inferiore significa una migliore reattività della CA, ma è possibile una latenza di scalabilità inferiore. Un valore più elevato può influire sulle prestazioni della CA con cluster di grandi dimensioni (centinaia di nodi). Imposta su un valore non positivo per disattivare questa euristica: CA non limiterà il numero di nodi che considera. » |
30 |
|
rapporto ridimensionamento del pool di candidati |
Un rapporto di nodi che sono considerati come candidati aggiuntivi non vuoti per la riduzione quando alcuni candidati dell'iterazione precedente non sono più validi. Un valore inferiore significa una migliore reattività della CA, ma è possibile una latenza di scalabilità più lenta. Un valore più elevato può influire sulle prestazioni della CA con cluster di grandi dimensioni (centinaia di nodi). Imposta su 1.0 per disattivare questa euristica: CA accetterà tutti i nodi come candidati aggiuntivi. |
0.1 |
|
scale-down-candidates-pool-min-count |
Numero minimo di nodi considerati come candidati aggiuntivi non vuoti per la riduzione quando alcuni candidati dell'iterazione precedente non sono più validi. Nel calcolare la dimensione del pool per i candidati aggiuntivi, prendiamo |
50 |
Risorse aggiuntive
Questa pagina contiene un elenco di presentazioni e demo di Cluster Autoscaler. Se desideri aggiungere una presentazione o una demo qui, invia una pull request.
| Presentation/Demo | Presentatori |
|---|---|
|
Scalabilità automatica e ottimizzazione dei costi su Kubernetes: da 0 a 100 |
Guy Templeton, Skyscanner e Jiaxin Shan, Amazon |
|
Maciek Pytel e Marcin Wielgus |
Riferimenti
-
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md
-
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
-
https://github.com/aws/amazon-ec2-instance-selector
-
https://github.com/aws/aws-node-termination-handler
