Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Concetti di Kubernetes
Amazon Elastic Kubernetes Service (Amazon EKS) AWS è un servizio gestito basato sul progetto open source Kubernetes.
Questa pagina divide i concetti di Kubernetes in tre sezioni: Perché Kubernetes?, Cluster e Carichi di lavoro. La prima sezione descrive il valore dell’esecuzione di un servizio Kubernetes, in particolare come servizio gestito quale Amazon EKS. La sezione Carichi di lavoro illustra come le applicazioni Kubernetes vengono create, archiviate, eseguite e gestite. La sezione Cluster illustra i diversi componenti che formano i cluster Kubernetes e quali sono le tue responsabilità per la creazione e la manutenzione di questi cluster.
Durante la lettura di questo contenuto, i link ti condurranno a ulteriori descrizioni dei concetti di Kubernetes nella documentazione di Amazon EKS e Kubernetes, nel caso in cui desideri approfondire uno degli argomenti trattati qui. Per dettagli su come Amazon EKS implementa il piano di controllo e le funzionalità di calcolo di Kubernetes, consulta Architettura di Amazon EKS.
Perché Kubernetes?
Kubernetes è stato progettato per migliorare la disponibilità e la scalabilità durante l’esecuzione di applicazioni containerizzate mission-critical e di qualità produttiva. Anziché limitarsi a eseguire Kubernetes su una singola macchina (sebbene ciò sia possibile), Kubernetes raggiunge questi obiettivi consentendoti di eseguire applicazioni su set di computer che possono espandersi o contrarsi per soddisfare la domanda. Kubernetes include funzionalità che rendono più semplice:
-
Distribuire applicazioni su più macchine (utilizzando container distribuiti nei pod)
-
Monitorare lo stato dei container e riavviare quelli che hanno subito un errore
-
Aumentare e ridurre i container in base al carico
-
Aggiornare i container con le nuove versioni
-
Allocare le risorse tra i container
-
Bilanciare il traffico tra le macchine
L’automazione di questi tipi di attività complesse da parte di Kubernetes consente agli sviluppatori di applicazioni di concentrarsi sulla creazione e sul miglioramento dei carichi di lavoro delle applicazioni, anziché preoccuparsi dell’infrastruttura. In genere, lo sviluppatore crea file di configurazione, formattati come file YAML, che descrivono lo stato desiderato dell’applicazione. Ciò potrebbe includere i contenitori da eseguire, i limiti delle risorse, il numero di repliche Pod, l' CPU/memory allocazione, le regole di affinità e altro ancora.
Attributi di Kubernetes
Per raggiungere gli obiettivi, Kubernetes ha i seguenti attributi:
-
Containerizzato: Kubernetes è uno strumento di orchestrazione dei container. Per utilizzare Kubernetes, devi prima avere le tue applicazioni containerizzate. A seconda del tipo di applicazione, potrebbe trattarsi di un insieme di microservizi, di processi in batch o in altre forme. Quindi, le tue applicazioni possono trarre vantaggio da un flusso di lavoro di Kubernetes che comprende un enorme ecosistema di strumenti, in cui i container possono essere archiviati come immagini in un registro di container
, distribuiti in un cluster Kubernetes ed eseguiti su un nodo disponibile. Puoi creare e testare singoli container sul tuo computer locale con Docker o un altro runtime di container prima di distribuirli nel cluster Kubernetes. -
Scalabile: se la domanda per le tue applicazioni supera la capacità delle istanze in esecuzione delle stesse, Kubernetes è in grado di aumentare verticalmente. Se necessario, Kubernetes è in grado di stabilire se le applicazioni richiedono più CPU o memoria e rispondere o espandendo automaticamente la capacità disponibile o utilizzando una maggiore capacità esistente. La scalabilità può essere eseguita a livello di pod, se è disponibile una quantità di calcolo sufficiente per eseguire solo più istanze dell’applicazione (scalabilità automatica del pod in orizzontale
), o a livello di nodo, se è necessario attivare più nodi per gestire l’aumento della capacità (Cluster Autoscaler o Karpenter ). Poiché la capacità non è più necessaria, questi servizi possono eliminare i pod non necessari e chiudere i nodi non necessari. -
Disponibile: se un’applicazione o un nodo non sono integri o non sono disponibili, Kubernetes può spostare i carichi di lavoro in esecuzione su un altro nodo disponibile. Puoi forzare il problema semplicemente eliminando un’istanza in esecuzione di un carico di lavoro o di un nodo che esegue i tuoi carichi di lavoro. In conclusione, i carichi di lavoro possono essere trasferiti in altre posizioni se non possono più essere eseguiti dove si trovano.
-
Dichiarativo: Kubernetes utilizza la riconciliazione attiva per verificare costantemente che lo stato dichiarato per il cluster corrisponda allo stato effettivo. Applicando oggetti Kubernetes
a un cluster, in genere tramite file di YAML-formatted configurazione, puoi, ad esempio, chiedere di avviare i carichi di lavoro che desideri eseguire sul cluster. Successivamente, puoi modificare le configurazioni per eseguire operazioni quali utilizzare una versione successiva di un container o allocare più memoria. Kubernetes farà ciò che deve fare per stabilire lo stato desiderato. Ciò può includere l’attivazione o la disattivazione dei nodi, l’arresto e il riavvio dei carichi di lavoro o l’estrazione di container aggiornati. -
Componibile: poiché un’applicazione è in genere composta da più componenti, è necessario essere in grado di gestire insieme un insieme di questi componenti (spesso rappresentati da più container). Sebbene Docker Compose offra un modo per farlo direttamente con Docker, il comando Kompose
di Kubernetes può aiutarti a farlo con Kubernetes. Consultare Translate a Docker Compose File to Kubernetes Resources per un esempio di come eseguire questa operazione. -
Estensibile: a differenza del software proprietario, il progetto open source Kubernetes è progettato per consentirti di estendere Kubernetes in qualsiasi modo desideri per soddisfare le tue esigenze. Le API e i file di configurazione sono aperti a modifiche dirette. Third-parties sono incoraggiati a scrivere i propri controller
, per estendere sia l'infrastruttura che le funzionalità di Kubernetes per gli utenti finali. I webhook consentono di configurare le regole del cluster per applicare le policy e adattarsi alle condizioni mutevoli. Per altre idee su come estendere i cluster Kubernetes, consultare Extending Kubernetes . -
Portatile: molte organizzazioni hanno standardizzato le proprie operazioni su Kubernetes perché consente loro di gestire tutte le esigenze applicative nello stesso modo. Gli sviluppatori possono utilizzare le stesse pipeline per creare e archiviare applicazioni containerizzate. Queste applicazioni possono quindi essere distribuite su cluster Kubernetes in esecuzione in locale, nel cloud, sui terminali dei punti vendita nei ristoranti o su dispositivi IoT distribuiti nei siti remoti di un'azienda. La sua natura open source consente alle persone di sviluppare queste distribuzioni Kubernetes speciali, insieme agli strumenti necessari per gestirle.
Gestione di Kubernetes
Il codice sorgente di Kubernetes è disponibile gratuitamente, quindi è possibile installare e gestire Kubernetes da soli con le proprie apparecchiature. Tuttavia, la gestione automatica di Kubernetes richiede una profonda esperienza operativa e richiede tempo e impegno per la manutenzione. Per questi motivi, la maggior parte delle persone che implementano carichi di lavoro di produzione sceglie un provider cloud (come Amazon EKS) o un provider on-premises (come Amazon EKS Anywhere) con la propria distribuzione Kubernetes testata e il supporto di esperti Kubernetes. Ciò consente di alleggerire gran parte del carico di lavoro indifferenziato necessario per la manutenzione dei cluster, tra cui:
-
Hardware: se non disponi di hardware disponibile per eseguire Kubernetes in base alle tue esigenze, un provider di servizi cloud come AWS Amazon EKS può farti risparmiare sui costi iniziali. Con Amazon EKS, ciò significa che puoi utilizzare le migliori risorse cloud offerte da AWS, tra cui istanze di calcolo (Amazon Elastic Compute Cloud), il tuo ambiente privato (Amazon VPC), la gestione centralizzata di identità e permessi (IAM) e lo storage (Amazon EBS). AWS gestisce i computer, le reti, i data center e tutti gli altri componenti fisici necessari per eseguire Kubernetes. Allo stesso modo, non è necessario pianificare il data center per gestire la capacità massima nei giorni con una maggiore richiesta. Per Amazon EKS Anywhere o altri cluster Kubernetes locali, sei responsabile della gestione dell'infrastruttura utilizzata nelle tue implementazioni Kubernetes, ma puoi comunque contare su AWS un aiuto per mantenere Kubernetes aggiornato.
-
Gestione del piano di controllo: Amazon EKS gestisce la sicurezza e la disponibilità del piano di controllo Kubernetes AWS ospitato, responsabile della pianificazione dei container, della gestione della disponibilità delle applicazioni e di altre attività chiave, in modo che tu possa concentrarti sui carichi di lavoro delle applicazioni. In caso di guasto del cluster, AWS dovresti disporre dei mezzi per ripristinarlo in uno stato di esecuzione. Per Amazon EKS Anywhere, il piano di controllo verrebbe gestito dall’utente stesso.
-
Upgrade testati: quando aggiorni i tuoi cluster, puoi fare affidamento su Amazon EKS o Amazon EKS Anywhere per fornire versioni testate delle distribuzioni Kubernetes.
-
Add-ons— Esistono centinaia di progetti creati per estendere e utilizzare Kubernetes che puoi aggiungere all'infrastruttura del cluster o utilizzare per facilitare l'esecuzione dei tuoi carichi di lavoro. Invece di creare e gestire autonomamente questi componenti aggiuntivi, puoi utilizzarli AWS con Componenti aggiuntivi Amazon EKS i tuoi cluster. Amazon EKS Anywhere fornisce pacchetti curati
che includono build di molti progetti open source popolari. Quindi non è necessario creare il software o gestire patch di sicurezza, correzioni di bug o aggiornamenti critici per proprio conto. Allo stesso modo, se le impostazioni predefinite soddisfano le tue esigenze, è normale che sia necessaria una configurazione minima di tali componenti aggiuntivi. Consultare Estendere i cluster per i dettagli sull’estensione del cluster con componenti aggiuntivi.
Kubernetes in azione
Il diagramma seguente mostra le attività chiave che potresti svolgere in qualità di amministratore o sviluppatore di applicazioni Kubernetes per creare e utilizzare un cluster Kubernetes. Nel processo, illustra come i componenti di Kubernetes interagiscono tra loro, utilizzando il AWS cloud come esempio del provider cloud sottostante.
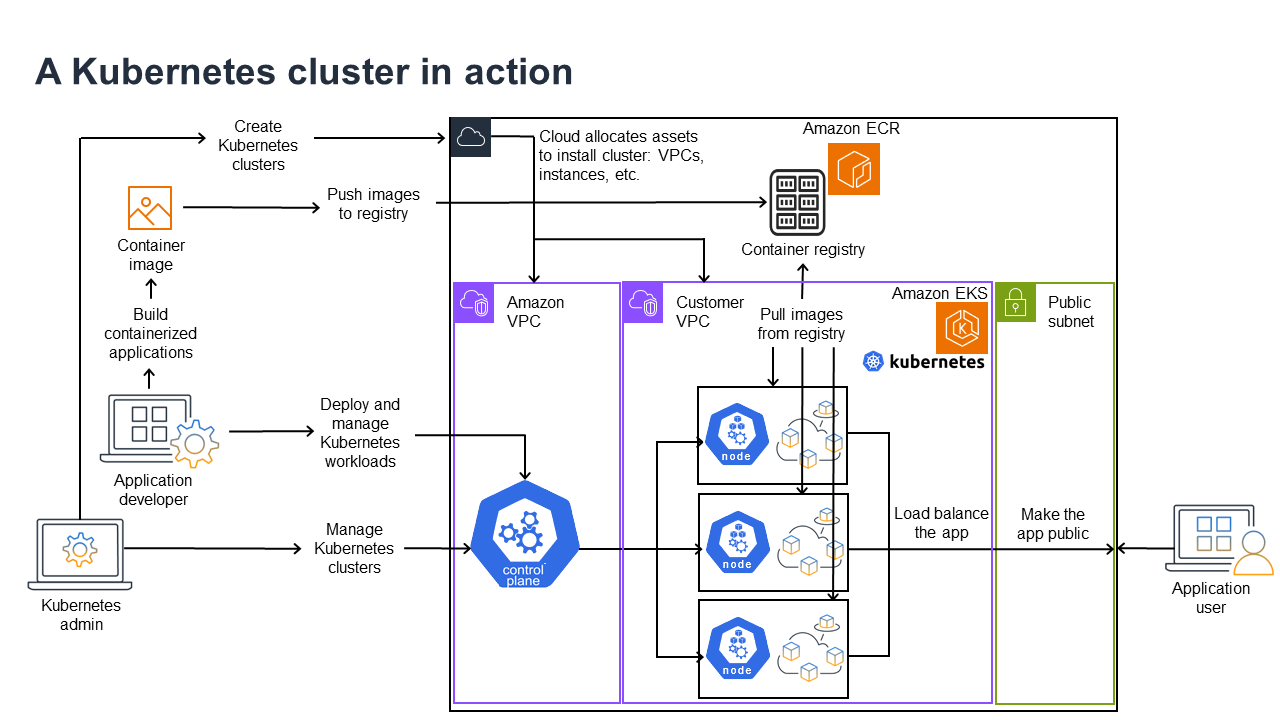
Un amministratore Kubernetes crea il cluster Kubernetes utilizzando uno strumento specifico per il tipo di provider su cui verrà creato il cluster. Questo esempio utilizza il AWS cloud come provider, che offre il servizio Kubernetes gestito chiamato Amazon EKS. Il servizio gestito alloca automaticamente le risorse necessarie per creare il cluster, inclusa la creazione di due nuovi cloud privati virtuali (Amazon VPC) per il cluster, la configurazione della rete e la mappatura delle autorizzazioni Kubernetes direttamente nei nuovi VPC per la gestione delle risorse cloud. Il servizio gestito verifica inoltre che i servizi del piano di controllo abbiano luoghi in cui eseguire e alloca zero o più istanze Amazon EC2 come nodi Kubernetes per l'esecuzione di carichi di lavoro. AWS gestisce un Amazon VPC stesso per il piano di controllo, mentre l'altro Amazon VPC contiene i nodi cliente che eseguono i carichi di lavoro.
Molte delle attività future dell’amministratore di Kubernetes vengono eseguite utilizzando strumenti Kubernetes come kubectl. Questo strumento invia le richieste di servizi direttamente al piano di controllo del cluster. I modi in cui le query e le modifiche vengono apportate al cluster sono quindi molto simili a quelli in cui verrebbero eseguite in qualsiasi cluster Kubernetes.
Uno sviluppatore di applicazioni che desidera distribuire carichi di lavoro in questo cluster può eseguire diverse attività. Lo sviluppatore deve creare l'applicazione in una o più immagini di container, quindi inviarle a un registro di contenitori accessibile al cluster Kubernetes. AWS a tale scopo offre Amazon Elastic Container Registry (Amazon ECR) Elastic Container Registry (Amazon ECR).
Per eseguire l'applicazione, lo sviluppatore può creare file di YAML-formatted configurazione che indicano al cluster come eseguire l'applicazione, inclusi i contenitori da estrarre dal registro e come avvolgerli in Pods. Il piano di controllo (scheduler) pianifica i container su uno o più nodi e il runtime del container su ciascun nodo recupera ed esegue effettivamente i container necessari. Lo sviluppatore può anche configurare un Application Load Balancer per bilanciare il traffico verso i container disponibili in esecuzione su ciascun nodo ed esporre l’applicazione al mondo esterno in modo che sia disponibile su una rete pubblica. Fatto ciò, qualcuno che desidera utilizzare l’applicazione può connettersi al suo endpoint per accedervi.
Le sezioni seguenti illustrano i dettagli di ciascuna di queste funzionalità, dal punto di vista dei cluster e dei carichi di lavoro Kubernetes.
Cluster
Se il tuo compito è avviare e gestire i cluster Kubernetes, devi sapere come vengono creati, migliorati, gestiti ed eliminati. Devi anche sapere quali sono i componenti che formano un cluster e cosa fare per mantenerli.
Gli strumenti per la gestione dei cluster si occupano della sovrapposizione tra i servizi Kubernetes e il provider hardware sottostante. Per questo motivo, l'automazione di queste attività tende ad essere eseguita dal provider Kubernetes (come Amazon EKS o Amazon EKS Anywhere) utilizzando strumenti specifici per il provider. Ad esempio, per avviare un cluster Amazon EKS si può utilizzare eksctl create cluster, mentre per Amazon EKS Anywhere è possibile utilizzare eksctl anywhere create cluster. Nota che, sebbene questi comandi creino un cluster Kubernetes, sono specifici del provider e non fanno parte del progetto Kubernetes stesso.
Strumenti per la creazione e la gestione dei cluster
Il progetto Kubernetes offre strumenti per creare manualmente un cluster Kubernetes. Quindi, se vuoi installare Kubernetes su una singola macchina o eseguire il piano di controllo su una macchina e aggiungere nodi manualmente, puoi utilizzare strumenti CLI come kind
Nel AWS cloud, puoi creare cluster Amazon EKS utilizzando strumenti CLI, come eksctl, o strumenti più dichiarativi, come
-
Piano di controllo gestito:AWS assicura che il cluster Amazon EKS sia disponibile e scalabile perché gestisce il piano di controllo per te e lo rende disponibile in tutte le zone di AWS disponibilità.
-
Gestione dei nodi: invece di aggiungere i nodi manualmente, puoi fare in modo che Amazon EKS crei i nodi in automatico a seconda delle necessità, utilizzando Gruppi di nodi gestiti (vedere Semplifica il ciclo di vita dei nodi con gruppi di nodi gestiti) o Karpenter
. I gruppi di nodi gestiti presentano integrazioni con Cluster Autoscaling di Kubernetes. Utilizzando gli strumenti di gestione dei nodi, è possibile trarre vantaggio dai risparmi sui costi, come le istanze spot e il consolidamento e la disponibilità dei nodi, utilizzando le funzionalità di pianificazione per impostare la modalità di distribuzione dei carichi di lavoro e la selezione dei nodi. -
Rete di cluster: utilizzando CloudFormation modelli,
eksctlconfigura la rete tra i componenti del piano di controllo e del piano dati (nodo) nel cluster Kubernetes. Inoltre, configura gli endpoint attraverso i quali possono avvenire le comunicazioni interne ed esterne. Per ulteriori dettagli, consulta la sezione De-mystifying Cluster Networking for Amazon EKS Worker Nodes. Le comunicazioni tra i Pod in Amazon EKS vengono effettuate utilizzando Amazon EKS Pod Identities (vediScopri come EKS Pod Identity concede ai pod l'accesso a AWS services), che fornisce un mezzo per consentire ai Pods di attingere ai metodi AWS cloud per la gestione di credenziali e autorizzazioni. -
Add-Ons— Amazon EKS ti evita di dover creare e aggiungere componenti software comunemente usati per supportare i cluster Kubernetes. Ad esempio, quando crei un cluster Amazon EKS da AWS Management Console, questo aggiunge automaticamente i componenti aggiuntivi Amazon EKS kube-proxy ()Gestisci kube-proxy nei cluster Amazon EKS, il plug-in Amazon VPC CNI per Kubernetes () e CoredNS ()Assegna IP ai pod con CNI di Amazon VPC. Gestione di CoreDNS per DNS nei cluster Amazon EKS Consultare Componenti aggiuntivi Amazon EKS per ulteriori elementi aggiuntivi, incluso un elenco di quali sono disponibili.
Per eseguire i cluster su computer e reti on-premises, Amazon offre Amazon EKS Anywhere
Amazon EKS Anywhere si basa sullo stesso software Amazon EKS Distroetcd più avanti in questo documento).
Componenti del cluster
I componenti del cluster Kubernetes sono suddivisi in due aree principali: piano di controllo e nodi worker. I componenti del piano di controllo
Piano di controllo
Il piano di controllo è costituito da un insieme di servizi che gestiscono il cluster. Questi servizi possono essere eseguiti tutti su un singolo computer o possono essere distribuiti su più computer. Internamente, queste sono denominate Istanze del piano di controllo (CPI). Il modo in cui vengono eseguite le CPI dipende dalla dimensione del cluster e dai requisiti di elevata disponibilità. Con l'aumento della domanda nel cluster, un servizio del piano di controllo può scalare per fornire più istanze di quel servizio, con il bilanciamento del carico delle richieste tra le istanze.
Le attività eseguite dai componenti del piano di controllo Kubernetes includono:
-
Comunicazione con i componenti del cluster (server API): il server API (kube-apiserver
) espone l’API Kubernetes in modo che le richieste al cluster possano essere effettuate sia dall’interno che dall’esterno del cluster. In altre parole, le richieste di aggiunta o modifica degli oggetti di un cluster (pod, servizi, nodi e così via) possono provenire da comandi esterni, come le richieste di esecuzione da parte di kubectldi eseguire un pod. Allo stesso modo, è possibile effettuare richieste dal server API ai componenti all’interno del cluster, ad esempio una richiesta al serviziokubeletper lo stato di un pod. -
Archivia dati sul cluster (archivio di valori delle chiavi
etcd): il servizioetcdsvolge il ruolo fondamentale di tenere traccia dello stato attuale del cluster. Se il servizioetcddiventasse inaccessibile, non sarebbe possibile aggiornare lo stato del cluster o eseguire query su di esso, anche se i carichi di lavoro continuerebbero a funzionare per un po’. Per questo motivo, i cluster critici in genere dispongono di più istanze di bilanciatore del carico del servizioetcdin esecuzione contemporaneamente ed effettuano backup periodici dell’archivio di valori delle chiavietcdin caso di perdita o danneggiamento dei dati. Tieni presente che, in Amazon EKS, tutto questo viene gestito automaticamente per impostazione predefinita. Amazon EKS Anywhere fornisce istruzioni per etcd backup and restore. Consulta etcd Data Model per scoprire come etcdgestisce i dati. -
Programma i pod ai nodi (Scheduler): le richieste di avvio o arresto di un pod in Kubernetes vengono indirizzate a Kubernetes Scheduler
(kube-scheduler ). Poiché un cluster può avere più nodi in grado di eseguire il pod, spetta allo Scheduler scegliere su quale nodo (o nodi, nel caso delle repliche) eseguire il pod. Se la capacità disponibile non è sufficiente per eseguire il pod richiesto su un nodo esistente, la richiesta avrà esito negativo, a meno che non siano state prese altre disposizioni. Tali disposizioni potrebbero includere l’abilitazione di servizi come Gruppi di nodi gestiti (Semplifica il ciclo di vita dei nodi con gruppi di nodi gestiti) o Karpenter in grado di avviare automaticamente nuovi nodi per gestire i carichi di lavoro. -
Mantieni i componenti nello stato desiderato (Gestore di controller): il Gestore controller di Kubernetes viene eseguito come processo daemon (kube-controller-manager
) per monitorare lo stato del cluster e apportare modifiche al cluster per ristabilire gli stati previsti. In particolare, esistono diversi controller che controllano diversi oggetti Kubernetes, tra cui statefulset-controller,endpoint-controller,cronjob-controller,node-controllere altri. -
Gestisci le risorse cloud (Gestore di controller cloud): le interazioni tra Kubernetes e il provider cloud che esegue le richieste per le risorse del data center sottostanti vengono gestite dal Gestore di controller cloud
(cloud-controller-manager ). I controller gestiti da Gestore di controller cloud possono includere un controller di percorso (per configurare i percorsi di rete cloud), un controller di servizio (per l’utilizzo dei servizi di bilanciatore del carico nel cloud) e un controller del ciclo di vita dei nodi (per mantenere i nodi sincronizzati con Kubernetes per tutto il loro ciclo di vita).
Nodi worker (piano dati)
Per un cluster Kubernetes a nodo singolo, i carichi di lavoro vengono eseguiti sulla stessa macchina del piano di controllo. Tuttavia, una configurazione più standard prevede uno o più sistemi informatici separati (nodi
Quando crei per la prima volta un cluster Kubernetes, alcuni strumenti per la creazione di cluster ti consentono di configurare un certo numero di nodi da aggiungere al cluster (identificando i sistemi informatici esistenti o chiedendo al provider di crearne di nuovi). Prima di aggiungere qualsiasi carico di lavoro a tali sistemi, vengono aggiunti servizi a ciascun nodo per implementare queste funzionalità:
-
Gestisci ogni nodo (
kubelet): il server API comunica con il servizio kubeletin esecuzione su ciascun nodo per assicurarsi che il nodo sia registrato correttamente e che i pod richiesti dallo Scheduler siano in esecuzione. Il kubelet può leggere i manifest dei pod e configurare volumi di archiviazione o altre funzionalità necessarie ai pod sul sistema locale. Può anche verificare lo stato dei container in esecuzione locale. -
Esegui i container su un nodo (runtime del container): il Runtime del container
su ciascun nodo gestisce i container richiesti per ogni pod assegnato al nodo. Ciò significa che può estrarre le immagini del contenitore dal registro appropriato, eseguire il contenitore, interromperlo e rispondere alle domande sul contenitore. Il runtime predefinito del container è containerd . A partire da Kubernetes 1.24, la speciale integrazione di Docker ( dockershim) che poteva essere utilizzata come runtime del container è stata eliminata da Kubernetes. Sebbene sia ancora possibile utilizzare Docker per testare ed eseguire container sul sistema locale, per utilizzare Docker con Kubernetes ora è necessario installare il motore Dockersu ogni nodo per utilizzarlo con Kubernetes. -
Gestisci la rete tra container (
kube-proxy): per supportare la comunicazione tra i pod, Kubernetes utilizza una funzionalità denominata Servizioper configurare le reti pod che tengono traccia degli indirizzi IP e delle porte associate a tali pod. Il servizio kube-proxy viene eseguito su ogni nodo per consentire la comunicazione tra i pod.
Estendere i cluster
Esistono alcuni servizi che puoi aggiungere a Kubernetes per supportare il cluster, ma non vengono eseguiti nel piano di controllo. Questi servizi spesso vengono eseguiti direttamente sui nodi del namespace kube-system o nel relativo namespace (come spesso accade con fornitori di servizi di terzi). Un esempio comune è il servizio CoreDNS, che fornisce servizi DNS al cluster. Fai riferimento a Discovering builtin services
Esistono diversi tipi di componenti aggiuntivi che puoi considerare di aggiungere ai tuoi cluster. Per mantenere integri i cluster, puoi aggiungere funzionalità di osservabilità (consultare Monitoraggio delle prestazioni del cluster e visualizzazione dei log) che consentono di eseguire operazioni come la registrazione, il controllo e le metriche. Con queste informazioni, puoi risolvere i problemi che si verificano, spesso tramite le stesse interfacce di osservabilità. Esempi di questi tipi di servizi includono Amazon GuardDuty, CloudWatch (vediMonitora i dati del cluster con Amazon CloudWatch), AWS Distro for OpenTelemetry, il plug-in Amazon VPC CNI per
Per un elenco più completo dei componenti aggiuntivi di Amazon EKS, consultare Componenti aggiuntivi Amazon EKS.
Carichi di lavoro
Kubernetes definisce un carico di lavoro
Container
L’elemento più basilare del carico di lavoro di un’applicazione che distribuisci e gestisci in Kubernetes è un pod
Poiché il pod è l’unità implementabile più piccola, in genere contiene un singolo container. Tuttavia, in un pod possono essere presenti più container nei casi in cui questi siano strettamente collegati. Ad esempio, un container di server Web potrebbe essere impacchettato in un pod con un tipo di container secondario
Le specifiche del Pod (PodSpec
Sebbene un pod sia l’unità più piccola implementabile, un container è l’unità più piccola da costruire e gestire.
Costruire container
Il pod è in realtà solo una struttura attorno a uno o più container, dove ognuno di essi contiene il file system, gli eseguibili, i file di configurazione, le librerie e altri componenti per eseguire effettivamente l’applicazione. Poiché i container sono diventati popolari grazie a una società chiamata Docker Inc., alcune persone si riferiscono ai container come container Docker. Tuttavia, da allora l’Open Container Initiative
Quando si crea un container, in genere si inizia con un Dockerfile (chiamato letteralmente così). All’interno di quel Dockerfile, si identifica:
-
Un’immagine di base: un’immagine container di base è un container che viene in genere creato da una versione minima del file system di un sistema operativo (come Red Hat Enterprise Linux
o Ubuntu ) o da un sistema minimale migliorato per fornire software al fine di eseguire tipi specifici di applicazioni (come app nodejs o python ). -
Software applicativo: puoi aggiungere il tuo software applicativo al container più o meno nello stesso modo in cui lo aggiungeresti a un sistema Linux. Ad esempio, nel tuo Dockerfile puoi eseguire
npmeyarnper installare un’applicazione Java oyumednfper installare pacchetti RPM. In altre parole, utilizzando un comando RUN in un Dockerfile, è possibile eseguire qualsiasi comando disponibile nel file system dell’immagine di base per installare software o configurare software all’interno dell’immagine del container risultante. -
Istruzioni: il Dockerfile reference
descrive le istruzioni che è possibile aggiungere a un Dockerfile durante la configurazione. Queste includono le istruzioni utilizzate per creare ciò che è contenuto nel container stesso (file ADDoCOPYdal sistema locale), identificare i comandi da eseguire quando il container viene eseguito (CMDoENTRYPOINT) e connettere il container al sistema su cui viene eseguito (identificandoUSEReseguire come, unVOLUMElocale da montare o le porte suEXPOSE).
Sebbene il comando e il servizio docker siano stati tradizionalmente utilizzati per creare container (docker build), altri strumenti disponibili per creare immagini di contenitori includono podman
Archiviazione dei container
Dopo aver creato l’immagine del container, puoi archiviarla in un registro di distribuzione
Per archiviare le immagini dei container in modo più pubblico, puoi inviarle a un registro di container pubblico. I registri pubblici dei container forniscono una posizione centrale per l’archiviazione e la distribuzione delle immagini dei container. Esempi di registri di container pubblici includono Amazon Elastic Container Registry
Quando esegui carichi di lavoro containerizzati su Amazon Elastic Kubernetes Service (Amazon EKS), consigliamo di estrarre copie delle immagini ufficiali Docker archiviate in Amazon Elastic Container Registry. Amazon ECR archivia queste immagini dal 2021. Puoi cercare le immagini dei container più comuni nella Galleria pubblica di Amazon ECR
Esecuzione dei container
Poiché i container sono creati in un formato standard, un container può essere eseguito su qualsiasi macchina in grado di eseguire un runtime di container (come Docker) e il cui contenuto corrisponda all’architettura della macchina locale (come x86_64 o arm). Per testare un container o semplicemente eseguirlo sul desktop locale, puoi utilizzare i comandi docker run o podman run per avviare un container su host locale. Per Kubernetes, tuttavia, ogni nodo worker dispone di un runtime di container implementato e spetta a Kubernetes richiedere che un nodo esegua un container.
Una volta che un container è stato assegnato per l’esecuzione su un nodo, quest’ultimo verifica se la versione richiesta dell’immagine del container esiste già sul nodo. In caso contrario, Kubernetes indica al runtime del container di estrarlo dal registro di container appropriato, quindi di eseguirlo localmente. Tieni presente che un’immagine del container si riferisce al pacchetto software che viene spostato tra il laptop, il registro dei container e i nodi Kubernetes. Un container si riferisce a un’istanza in esecuzione di quell’immagine.
Pod
Una volta che i container sono pronti, l’utilizzo dei pod include la sua configurazione, implementazione e accessibilità.
Configurazione dei pod
Quando definisci un pod, gli assegni una serie di attributi. Questi attributi devono includere almeno il nome del pod e l’immagine del container da eseguire. Tuttavia, ci sono anche molte altre cose che desideri configurare con le definizioni dei tuoi Pod (consulta la PodSpec
-
Archiviazione: quando un container in esecuzione viene interrotto ed eliminato, l’archiviazione di dati in quel container scompare, a meno che non si configuri uno spazio di archiviazione più permanente. Kubernetes supporta molti tipi di storage diversi e li riassume sotto il termine Volumi
. I tipi di storage includono CephFS , NFS, iSCSI e altri. È anche possibile utilizzare un dispositivo a blocchi locale dal computer locale. Con uno di questi tipi di archiviazione disponibili nel cluster, è possibile montare il volume di archiviazione su un punto di montaggio selezionato nel file system del container. Un volume persistente è quello che continua a esistere dopo l’eliminazione del pod, mentre un volume temporaneo viene eliminato quando il pod viene eliminato. Se l’amministratore del cluster ha creato diverse classi di archiviazione per il cluster, potrebbe essere possibile scegliere gli attributi dello storage da utilizzare, ad esempio se il volume viene eliminato o recuperato dopo l’uso, se si espanderà se è necessario più spazio e anche se soddisfa determinati requisiti di prestazioni. -
Segreti: rendendo disponibili Secrets
ai contenitori secondo le specifiche di Pod, puoi fornire le autorizzazioni necessarie a tali contenitori per accedere a file system, database o altre risorse protette. Chiavi, password e token sono tra gli elementi che possono essere archiviati come segreti. L’uso dei segreti consente di non dover memorizzare queste informazioni nelle immagini dei container, ma è sufficiente rendere i segreti disponibili ai container in esecuzione. Simili a Secrets sono ConfigMaps . ConfigMaptende a contenere informazioni meno critiche, come coppie chiave-valore per la configurazione di un servizio. -
Risorse del container: gli oggetti per un’ulteriore configurazione dei container possono assumere la forma di configurazione delle risorse. Per ogni container, puoi richiedere la quantità di memoria e CPU che può utilizzare, nonché porre limiti alla quantità totale di tali risorse che il container può utilizzare. Per degli esempi, consultare Resource Management for Pods and Containers
. -
Interruzioni: i pod possono essere interrotti involontariamente (un nodo non funziona) o volontariamente (è necessario un aggiornamento). Configurando un budget per le interruzioni dei pod
, puoi esercitare un certo controllo sulla disponibilità dell’applicazione in caso di interruzioni. Per degli esempi, consultare Specifica di un budget di interruzioni per la tua applicazione. -
Namespace: Kubernetes offre diversi modi per isolare i componenti e i carichi di lavoro di Kubernetes gli uni dagli altri. L’esecuzione di tutti i pod per una particolare applicazione nello stesso namespace
è un modo comune per proteggere e gestire insieme tali pod. Puoi creare i tuoi namespace da utilizzare o scegliere di non indicare un namespace (il che fa sì che Kubernetes utilizzi il namespace default). I componenti del piano di controllo di Kubernetes vengono in genere eseguiti nel namespace kube-system.
La configurazione appena descritta viene in genere raccolta in un file YAML da applicare al cluster Kubernetes. Per i cluster Kubernetes personali, è possibile archiviare semplicemente questi file YAML sul proprio sistema locale. Tuttavia, con cluster e carichi di lavoro più critici, GitOps
Gli oggetti utilizzati per raccogliere e implementare le informazioni sui pod sono definiti da uno dei seguenti metodi di implementazione.
Implementazione di pod
Il metodo da scegliere per implementare i pod dipende dal tipo di applicazione che intendi eseguire con gli stessi. Ecco alcune delle scelte:
-
Applicazioni stateless: un’applicazione stateless non salva i dati della sessione di un client, quindi un’altra sessione non deve fare riferimento a ciò che è accaduto a una sessione precedente. In questo modo è più semplice sostituire i pod con altri nuovi se non funzionano bene o spostarli senza salvarne lo stato. Se stai eseguendo un'applicazione stateless (come un server Web), puoi utilizzare un Deployment per distribuire Pods e. ReplicaSets
A ReplicaSet definisce quante istanze di un Pod vuoi che vengano eseguite contemporaneamente. Sebbene sia possibile eseguire ReplicaSet direttamente un Pod, è normale eseguire le repliche direttamente all'interno di un Deployment, per definire quante repliche di un Pod devono essere eseguite contemporaneamente. -
Applicazioni stateful: un’applicazione stateful è un’applicazione in cui l’identità del pod e l’ordine in cui vengono avviati i pod sono importanti. Queste applicazioni necessitano di uno storage persistente che sia stabile e che debba essere distribuito e scalato in modo coerente. Per distribuire un'applicazione con stato in Kubernetes, puoi usare. StatefulSets
Un esempio di applicazione che in genere viene eseguita come un database. StatefulSet All'interno di a StatefulSet, è possibile definire le repliche, il Pod e i relativi contenitori, i volumi di archiviazione da montare e le posizioni nel contenitore in cui vengono archiviati i dati. Vedi Run a Replicated Stateful Application per un esempio di database distribuito come. ReplicaSet -
Per-node applicazioni: a volte desideri eseguire un'applicazione su ogni nodo del cluster Kubernetes. Ad esempio, il tuo data center potrebbe richiedere che ogni computer esegua un’applicazione di monitoraggio o un particolare servizio di accesso remoto. Per Kubernetes, puoi utilizzare DaemonSet
a per assicurarti che l'applicazione selezionata venga eseguita su ogni nodo del cluster. -
Applicazioni eseguite fino al completamento: ci sono alcune applicazioni che desideri eseguire per completare un’attività particolare. Ciò potrebbe includerne una che esegue report mensili sullo stato o elimina i vecchi dati. Un oggetto Job
può essere utilizzato per configurare un’applicazione per l’avvio e l’esecuzione, quindi uscire al termine dell’attività. Un CronJob oggetto consente di configurare un'applicazione in modo che venga eseguita a un'ora, un minuto, un giorno del mese, del mese o del giorno della settimana specifici, utilizzando una struttura definita dal formato crontab di Linux.
Rendere le applicazioni accessibili dalla rete
Poiché le applicazioni vengono spesso distribuite come un insieme di microservizi che si spostano in luoghi diversi, Kubernetes aveva bisogno di un modo per consentire a tali microservizi di trovarsi l'un l'altro. Inoltre, per consentire ad altri di accedere a un’applicazione esterna al cluster Kubernetes, quest’ultimo aveva bisogno di un modo per esporre tale applicazione su indirizzi e porte esterni. Queste funzionalità relative alla rete vengono eseguite rispettivamente con oggetti Servizi e In ingresso:
-
Servizi: poiché un pod può spostarsi su nodi e indirizzi diversi, un altro pod che deve comunicare con il primo pod potrebbe avere difficoltà a localizzarlo. Per risolvere questo problema, Kubernetes ti consente di rappresentare un’applicazione come servizio
. Con un servizio, puoi identificare un pod o un set di pod con un nome particolare, quindi indicare quale porta espone il servizio di quell’applicazione dal pod e quali porte potrebbe utilizzare un’altra applicazione per contattare quel servizio. Un altro pod all’interno di un cluster può semplicemente richiedere un servizio per nome e Kubernetes indirizzerà la richiesta alla porta appropriata per un’istanza del pod che esegue quel servizio. -
In ingresso: In ingresso
è ciò che può rendere disponibili le applicazioni rappresentate dai servizi Kubernetes ai client esterni al cluster. Le funzionalità di base di In ingresso includono un sistema di bilanciatore del carico (gestito da In ingresso), il controller In ingresso e regole per il routing delle richieste dal controller al servizio. Con Kubernetes, puoi scegliere tra diversi controller in ingresso .
Fasi successive
Comprendere i concetti di base di Kubernetes e il modo in cui si relazionano ad Amazon EKS ti aiuterà a navigare sia la Documentazione su Amazon Elastic Kubernetes Service che la Documentazione di Kubernetes
