Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Abilitazione della rappresentazione utente per monitorare l'attività dell'utente e dei processi Spark
Nota
EMRI notebook sono disponibili come spazi di lavoro EMR Studio nella console. Il pulsante Crea area di lavoro nella console consente di creare nuovi taccuini. Per accedere o creare aree di lavoro, gli utenti di EMR Notebooks necessitano di autorizzazioni di ruolo aggiuntive. IAM Per ulteriori informazioni, consulta Amazon EMR Notebooks are Amazon EMR Studio Workspace nella console e nella console Amazon. EMR
EMRNotebooks ti consente di configurare l'impersonificazione degli utenti su un cluster Spark. Questa funzionalità consente di monitorare le attività dei processi avviati dall'interno dell'editor di notebook. Inoltre, EMR Notebooks dispone di un widget Jupyter Notebook integrato per visualizzare i dettagli del lavoro Spark insieme all'output delle query nell'editor di notebook. Il widget è disponibile per impostazione predefinita e non richiede alcuna configurazione speciale. Tuttavia, per visualizzare i server della cronologia, il client deve essere configurato per visualizzare le interfacce EMR Web di Amazon ospitate sul nodo primario.
Impostazione della rappresentazione utente Spark
Per impostazione predefinita, i processi Spark inviati dagli utenti mediante l'editor di notebook risultano provenienti da un'identità utente livy indistinta. È possibile configurare la rappresentazione utente per il cluster in modo che tali processi siano associati piuttosto all'identità utente che ha eseguito il codice. HDFSle directory utente sul nodo primario vengono create per ogni identità utente che esegue il codice nel notebook. Ad esempio, se l'utente NbUser1 esegue il codice dall'editor di notebook, puoi collegarti al nodo primario e vedere che hadoop fs -ls /user mostra la directory /user/user_NbUser1.
Puoi abilitare questa funzionalità impostando le proprietà nelle classificazioni di configurazione core-site e livy-conf. Questa funzionalità non è disponibile per impostazione predefinita quando Amazon EMR crea un cluster insieme a un notebook. Per ulteriori informazioni sull'utilizzo delle classificazioni di configurazione per personalizzare le applicazioni, consulta Configuring applications nella Amazon EMR Release Guide.
Utilizza le seguenti classificazioni e valori di configurazione per abilitare l'impersonificazione degli utenti per i notebook: EMR
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
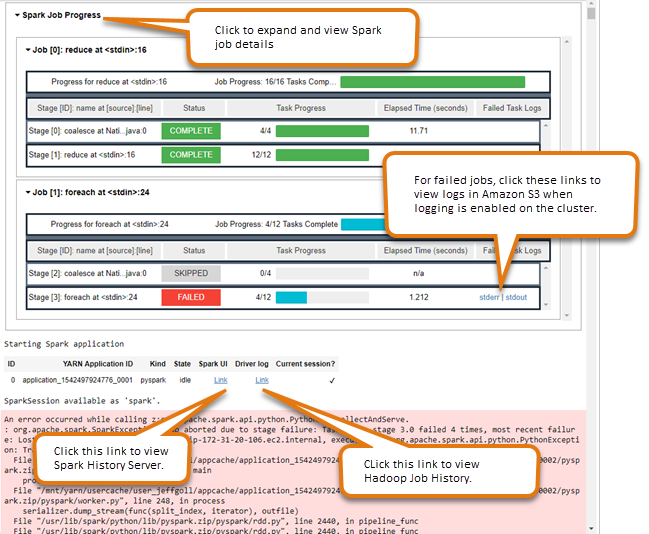
Utilizzo del widget di monitoraggio dei processi Spark
Quando esegui il codice nell'editor di notebook che esegue i job Spark sul EMR cluster, l'output include un widget Jupyter Notebook per il monitoraggio dei job Spark. Il widget fornisce i dettagli del processo e collegamenti utili alla pagina dei server della cronologia di Spark e alla pagina della cronologia di Hadoop, insieme a collegamenti ai log dei processi in Amazon S3 per tutti i processi non riuscito.
Per visualizzare le pagine del server di cronologia sul nodo primario del cluster, è necessario configurare un SSH client e un proxy appropriati. Per ulteriori informazioni, consulta Visualizza le interfacce Web ospitate su cluster Amazon EMR. Per visualizzare i log nel cluster Amazon S3 la registrazione deve essere abilitata, il che corrisponde all'impostazione predefinita per i nuovi cluster. Per ulteriori informazioni, consulta Visualizzazione dei file di log archiviati in Amazon S3.
Di seguito è riportato un esempio del monitoraggio dei processi Spark.