Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprendere come creare e utilizzare i cluster Amazon EMR
Questo argomento fornisce una panoramica dei cluster Amazon EMR e include come inviare il lavoro a un cluster, come vengono elaborati i dati e le varie condizioni del cluster durante l'elaborazione.
In questo argomento
Acquisire familiarità con cluster e nodi
Il componente centrale di Amazon EMR è il cluster. Un cluster è una raccolta di istanze Amazon Elastic Compute Cloud (Amazon EC2). Ogni istanza nel cluster è denominata nodo. Ogni nodo ha un ruolo all'interno del cluster, indicato come tipo di nodo. Amazon EMR installa anche diversi componenti software su ogni tipo di nodo, dando a ogni nodo un ruolo in un'applicazione distribuita come Apache Hadoop.
I tipi di nodo in Amazon EMR sono i seguenti:
-
Nodo primario: un nodo che gestisce il cluster eseguendo componenti software per coordinare la distribuzione di dati e attività tra altri nodi per l'elaborazione. Il nodo primario tiene traccia dello stato delle attività e monitora lo stato del cluster. Ogni cluster dispone di un nodo primario ed è possibile creare un singolo nodo cluster con solo il nodo primario.
-
Nodo principale: un nodo con componenti software che eseguono attività e archiviano dati nell'Hadoop Distributed File System (HDFS) del cluster. Multi-node i cluster hanno almeno un nodo principale.
-
Nodo attività: un nodo con componenti software che esegue solo le attività e non archivia i dati in HDFS. I nodi attività sono facoltativi.
Quando crei un cluster, scegli una delle due configurazioni per organizzare i nodi: gruppi di istanze o flotte di istanze. Con i gruppi di istanze, ogni gruppo contiene istanze Amazon EC2 dello stesso tipo e puoi avere più gruppi per tipo di nodo (tranne quello primario). Per quanto riguarda le flotte di istanze, ogni tipo di nodo dispone di un'unica flotta che può contenere una combinazione di tipi di istanze, con capacità target per On-Demand le istanze Spot e 2. Questa scelta è permanente e non può essere modificata dopo la creazione del cluster. Per ulteriori informazioni, consulta Crea un cluster Amazon EMR con flotte di istanze o gruppi di istanze uniformi.
Invio di lavori a un cluster
Quando si esegue un cluster su Amazon EMR, si hanno diverse opzioni circa il modo di specificare il lavoro che deve essere svolto.
-
Fornisci l'intera definizione lavoro da svolgere in funzioni che specifichi come fasi al momento della creazione di un cluster. Questo viene generalmente fatto per i cluster che elaborano una determinata quantità di dati e poi terminano quando l'elaborazione è completa.
-
Crea un cluster a lunga durata e utilizza la console Amazon EMR, l'API Amazon EMR o AWS CLI la procedura di invio, che può contenere uno o più lavori. Per ulteriori informazioni, consulta Invia il lavoro a un cluster Amazon EMR.
-
Crea un cluster, connettiti al nodo primario e ad altri nodi in base alle esigenze attraverso SSH e utilizza le interfacce che le applicazioni installate forniscono per eseguire le attività e inviare le query, con script o in modo interattivo. Per ulteriori informazioni, consulta la Guida ai rilasci di Amazon EMR.
Elaborazione di dati
Quando avvii il cluster, devi scegliere i framework e le applicazioni da installare per le tue esigenze di elaborazione dati. Per elaborare i dati nel cluster Amazon EMR, è possibile inviare processi o query direttamente alle applicazioni installate, oppure è possibile eseguire fasi nel cluster.
Invio diretto di processi alle applicazioni
È possibile inviare processi e interagire direttamente con il software installato nel cluster Amazon EMR. A tale scopo, in genere, ci si connette al nodo primario attraverso una connessione sicura e si accede alle interfacce e agli strumenti disponibili per il software che è in esecuzione direttamente sul cluster. Per ulteriori informazioni, consulta Connettiti a un cluster Amazon EMR.
Esecuzione di fasi per elaborare i dati
È possibile inviare una o più fasi ordinate a un cluster Amazon EMR. Ogni fase è un'unità di lavoro che contiene le istruzioni per manipolare i dati per l'elaborazione da parte di software installato sul cluster.
Di seguito è riportato un processo di esempio che si articola in quattro fasi:
-
Invio di un set di dati di input per l'elaborazione.
-
Elaborazione dell'output della prima fase con un programma Pig.
-
Elaborazione di un secondo set di dati di input con un programma Hive.
-
Scrittura di un set di dati di output.
Generalmente, quando si elaborano dati in Amazon EMR, l'input è costituito da dati memorizzati come file nel file system sottostante scelto, ad esempio Amazon S3 o HDFS. Questi dati passano da una fase all'altra della sequenza di elaborazione. La fase finale scrive i dati di output in un percorso specificato, ad esempio un bucket Amazon S3.
Le fasi vengono eseguite nella sequenza seguente:
-
Una richiesta viene inviata per iniziare le fasi di elaborazione.
-
Lo stato di tutte le fasi è impostato su PENDING (IN SOSPESO).
-
Quando la prima fase nella sequenza inizia, il relativo stato diventa RUNNING (IN ESECUZIONE). Le altre fasi rimangono nello stato PENDING (IN SOSPESO).
-
Dopo il completamento della prima fase, il suo stato diventa COMPLETED (COMPLETATO).
-
La fase successiva nella sequenza inizia e il relativo stato diventa RUNNING (IN ESECUZIONE). Quando viene completata, il relativo stato diventa COMPLETED (COMPLETATO).
-
Questo schema si ripete per ogni fase fino al loro completamento e alla fine dell'elaborazione.
Il seguente diagramma rappresenta la sequenza delle fasi e il cambiamento di stato delle stesse durante la loro elaborazione.

Se una fase ha esito negativo durante l'elaborazione, lo stato diventa FAILED (NON RIUSCITO). È possibile stabilire il passaggio successivo per ogni fase. Per impostazione predefinita, le restanti fasi nella sequenza sono impostate sullo stato CANCELLED (ANNULLATO) e non eseguite in caso di insuccesso di una fase precedente. È inoltre possibile scegliere di ignorare l'errore e consentire alle fasi rimanenti di proseguire o di terminare il cluster immediatamente.
Il diagramma seguente rappresenta la sequenza delle fasi e il cambiamento di stato predefinito quando una fase ha esito negativo durante l'elaborazione.

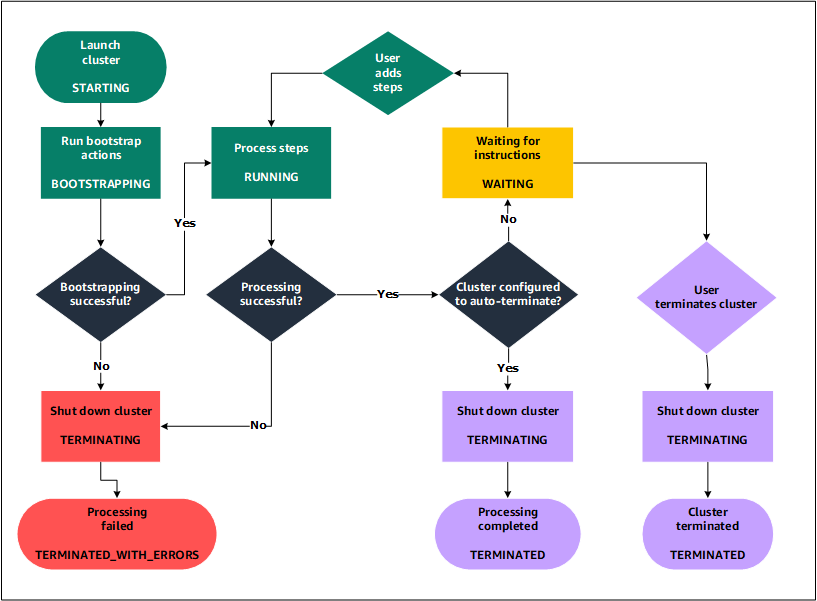
Comprensione del ciclo di vita del cluster
Un cluster Amazon EMR andato a buon fine segue questa procedura:
-
Innanzitutto, Amazon EMR esegue il provisioning di istanze EC2 nel cluster per ogni istanza in base alle specifiche. Per ulteriori informazioni, consulta Configurazione dell'hardware e della rete del cluster Amazon EMR. Per tutte le istanze, Amazon EMR usa l'AMI predefinita di Amazon EMR o un'AMI Amazon Linux personalizzata specificata dall'utente. Per ulteriori informazioni, consulta Utilizzo di un'AMI personalizzata per fornire maggiore flessibilità per la configurazione del cluster Amazon EMR. Durante questa fase, lo stato del cluster è
STARTING. -
Amazon EMR esegue le operazioni di bootstrap specificate per ogni istanza. È possibile utilizzare le operazioni di bootstrap per installare applicazioni personalizzate ed eseguire le personalizzazioni necessarie. Per ulteriori informazioni, consulta Crea azioni di bootstrap per installare software aggiuntivo con un cluster Amazon EMR. Durante questa fase, lo stato del cluster è
BOOTSTRAPPING. -
Amazon EMR installa le applicazioni native specificate al momento della creazione del cluster, ad esempio Hive, Spark, Hadoop e così via.
-
Una volta completate le operazioni di bootstrap e installate le applicazioni native, lo stato del cluster è
RUNNING. A questo punto, puoi connetterti alle istanze del cluster e il cluster eseguirà in sequenza tutte le fasi specificate durante la creazione del cluster. È possibile aggiungere ulteriori fasi, che vengono eseguite dopo il completamento di tutte le fasi precedenti. Per ulteriori informazioni, consulta Invia il lavoro a un cluster Amazon EMR. -
Dopo l'esecuzione corretta delle fasi, il cluster entra nello stato
WAITING. Se un cluster è configurato per terminare in automatico al completamento dell'ultima fase, passa allo statoTERMINATINGe poi allo statoTERMINATED. Se il cluster è configurato per attendere, è necessario terminarlo manualmente quando non è più necessario. Quando viene terminato manualmente, il cluster passa allo statoTERMINATINGe poi allo statoTERMINATED.
Un errore durante il ciclo di vita del cluster porta Amazon EMR a terminare il cluster e tutte le istanze correlate, a meno che non sia stata abilitata la protezione da cessazione. Se un cluster viene terminato a causa di un errore, i dati archiviati al suo interno vengono eliminati e lo stato del cluster viene impostato su TERMINATED_WITH_ERRORS. Se hai attivato la protezione dall'arresto, è possibile recuperare i dati dal cluster e quindi rimuovere la protezione e terminare il cluster. Per ulteriori informazioni, consulta Utilizzo della protezione dalle terminazioni per proteggere i cluster Amazon EMR da arresti accidentali.
Il diagramma seguente rappresenta il ciclo di vita di un cluster e come ogni fase del ciclo di vita viene associata a un particolare stato del cluster.