Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Plug-in di Apache Hive
Apache Hive è un motore di esecuzione popolare all'interno dell'ecosistema Hadoop. Amazon EMR fornisce un plug-in Apache Ranger per fornire controlli di accesso dettagliati per Hive. Il plug-in è compatibile con il server open source Apache Ranger Admin versione 2.0 e successive.
Argomenti
Funzionalità supportate
Il plug-in Apache Ranger per Hive on EMR supporta tutte le funzionalità del plug-in open source, che include controlli di accesso a livello di database, tabelle e colonne, filtraggio delle righe e mascheramento dei dati. Per una tabella dei comandi Hive e delle autorizzazioni Ranger associate, consulta Comandi Hive per la mappatura delle autorizzazioni Ranger
Installazione della configurazione del servizio
Il plugin Apache Hive è compatibile con la definizione del servizio Hive esistente all'interno di Apache Hive Hadoop. SQL
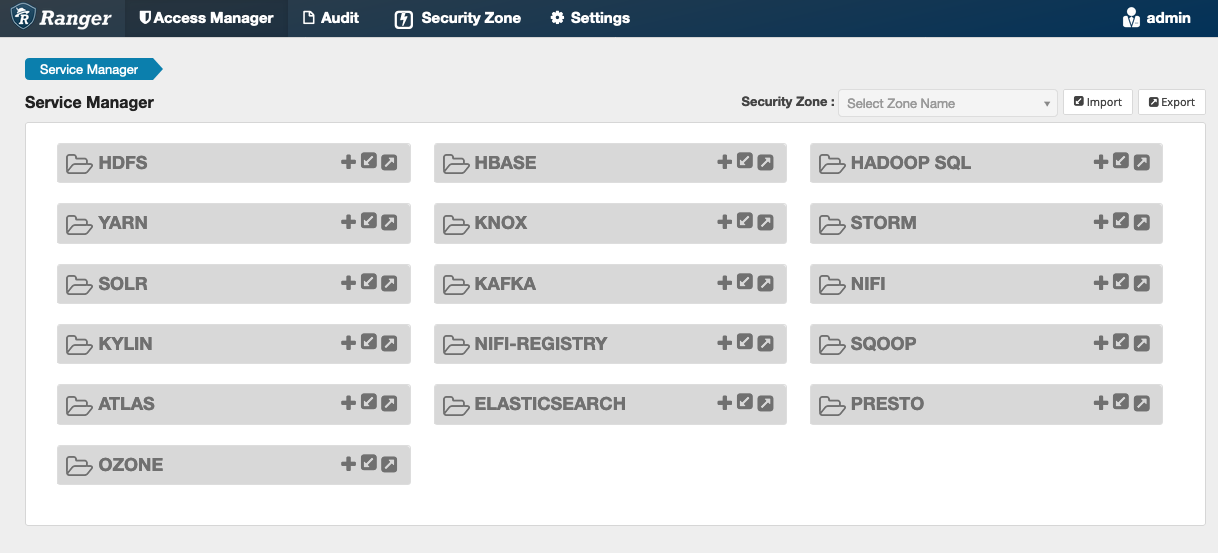
Se non disponi di un'istanza del servizio in HadoopSQL, come mostrato sopra, puoi crearne una. Fai clic sul segno + accanto a Hadoop. SQL
-
Nome del servizio (se visualizzato): immetti il nome del servizio. Il valore suggerito è
amazonemrhive. Prendi nota del nome di questo servizio: è necessario per creare una configurazione di EMR sicurezza. -
Nome visualizzato: immetti il nome da visualizzare per il servizio. Il valore suggerito è
amazonemrhive.
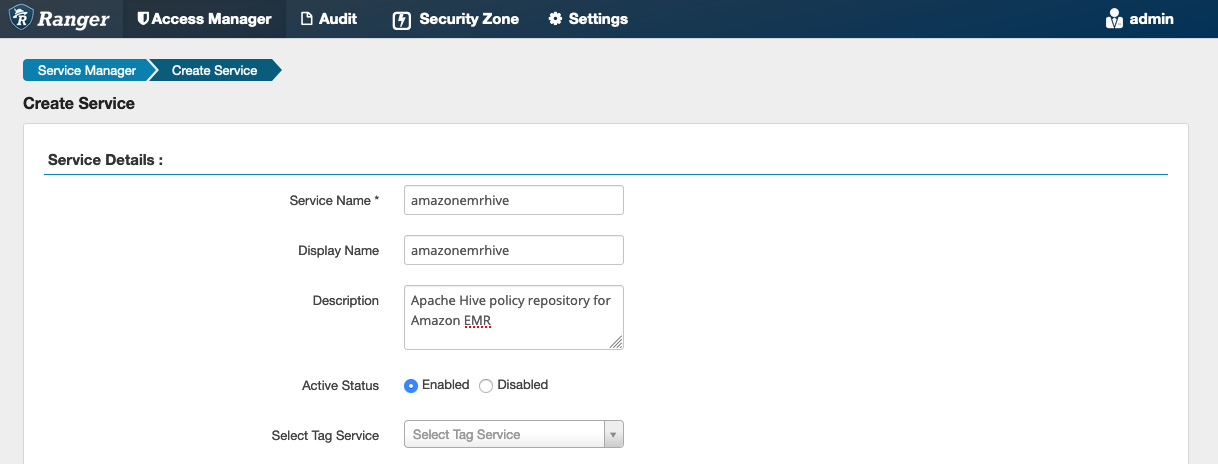
Le proprietà di configurazione di Apache Hive vengono utilizzate per stabilire una connessione al server di amministrazione Apache Ranger con un 2 per HiveServer implementare il completamento automatico durante la creazione delle politiche. Non è necessario che le proprietà seguenti siano accurate se non si dispone di un processo HiveServer 2 persistente e possono essere compilate con qualsiasi informazione.
-
Nome utente: inserisci un nome utente per la JDBC connessione a un'istanza di un'istanza HiveServer 2.
-
Password: inserisci la password per il nome utente sopra.
-
jdbc.driver. ClassName: Immettete il nome della JDBC classe per la connettività Apache Hive. Puoi utilizzare il valore predefinito.
-
jdbc.url: Inserisci la stringa di connessione da utilizzare per la JDBC connessione a 2. HiveServer
-
Nome comune per certificato: il campo CN all'interno del certificato utilizzato per connettersi al server Admin da un plug-in client. Questo valore deve corrispondere al campo CN del TLS certificato creato per il plug-in.
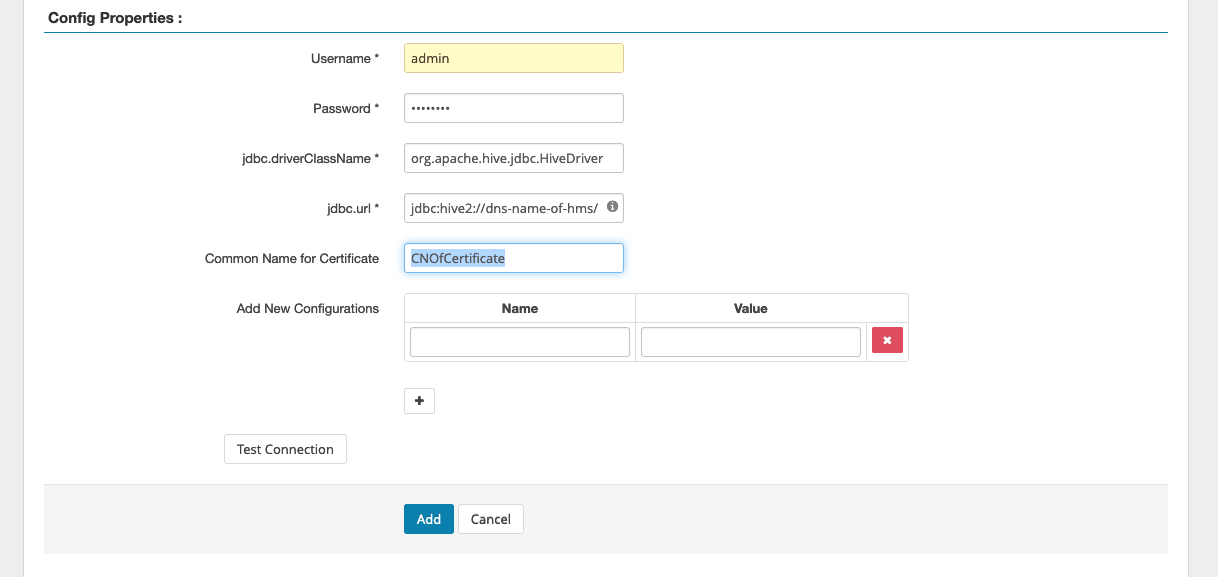
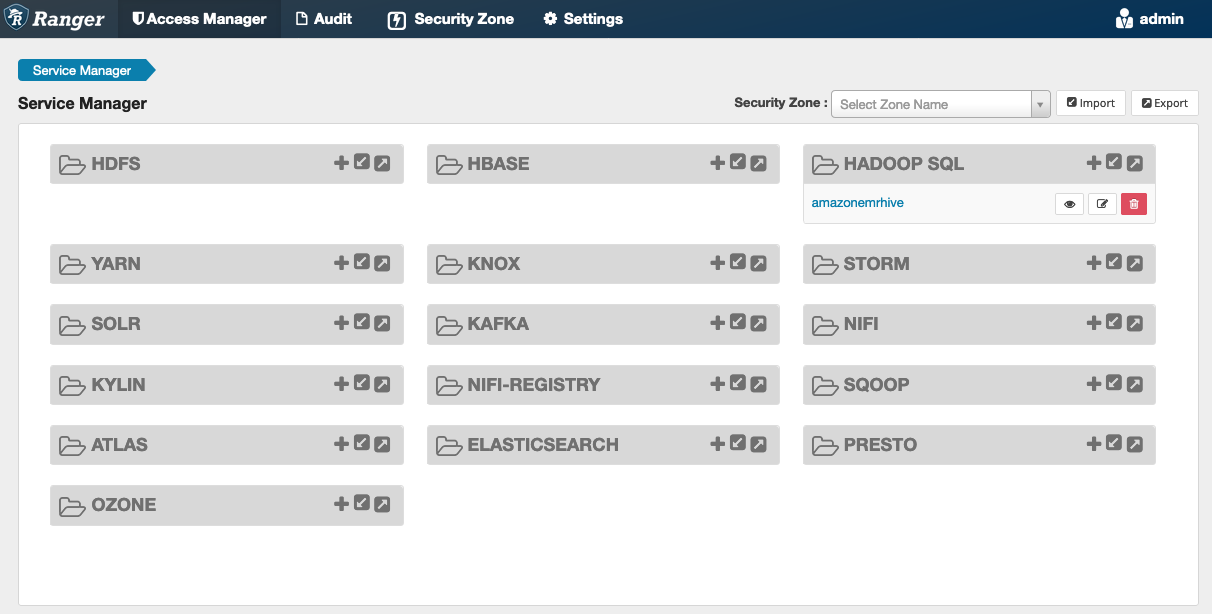
Il pulsante Test Connection verifica se i valori sopra riportati possono essere utilizzati per connettersi correttamente all'istanza HiveServer 2. Una volta che il servizio è stato creato correttamente, il Service Manager dovrebbe avere il seguente aspetto:
Considerazioni
Server dei metadati Hive
Il server dei metadati Hive è accessibile solo dai motori attendibili, in particolare Hive e emr_record_server, come misura di protezione da accessi non autorizzati. Il server dei metadati Hive è accessibile anche da tutti i nodi del cluster. La porta 9083 richiesta consente a tutti i nodi di accedere al nodo principale.
Autenticazione
Per impostazione predefinita, Apache Hive è configurato per l'autenticazione tramite Kerberos come configurato nella configurazione Security. EMR HiveServer2 può essere configurato anche per autenticare gli utenti utilizzando. LDAP Per informazioni, consulta Implementazione dell'LDAPautenticazione per Hive su un cluster EMR Amazon multi-tenant
Limitazioni
Di seguito sono riportate le limitazioni attuali per il plug-in Apache Hive su Amazon EMR 5.x:
-
I ruoli Hive non sono attualmente supportati. Le istruzioni Grant (Concedi) e Revoke (Revoca) non sono supportate.
-
Hive CLI non è supportato. JDBC/Beeline è l'unico modo autorizzato per connettere Hive.
-
hive.server2.builtin.udf.blacklistla configurazione deve essere compilata con UDFs ciò che ritieni non sicuro.
