Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Plug-in per Apache Spark
Amazon EMR si è integrato EMR RecordServer per fornire un controllo granulare degli accessi per Spark. SQL EMR RecordServer è un processo privilegiato in esecuzione su tutti i nodi di un cluster abilitato per Apache Ranger. Quando un driver o un esecutore Spark esegue un'SQListruzione Spark, tutte le richieste di metadati e dati passano attraverso. RecordServer Per saperne di più EMR RecordServer, consulta la pagina. EMRComponenti Amazon
Argomenti
Funzionalità supportate
| SQLDichiarazione/azione da ranger | STATUS | Versione supportata EMR |
|---|---|---|
|
SELECT |
Supportato |
A partire da 5.32 |
|
SHOW DATABASES |
Supportato |
A partire da 5.32 |
|
SHOW COLUMNS |
Supportato |
A partire da 5.32 |
|
SHOW TABLES |
Supportato |
A partire da 5.32 |
|
SHOW TABLE PROPERTIES |
Supportato |
A partire da 5.32 |
|
DESCRIBE TABLE |
Supportato |
A partire da 5.32 |
|
INSERT OVERWRITE |
Supportato |
A partire da 5.34 e 6.4 |
| INSERT INTO | Supportato | A partire da 5.34 e 6.4 |
|
ALTER TABLE |
Supportato |
A partire da 6.4 |
|
CREATE TABLE |
Supportato |
A partire da 5.35 e 6.7 |
|
CREATE DATABASE |
Supportato |
A partire da 5.35 e 6.7 |
|
DROP TABLE |
Supportato |
A partire da 5.35 e 6.7 |
|
DROP DATABASE |
Supportato |
A partire da 5.35 e 6.7 |
|
DROP VIEW |
Supportato |
A partire da 5.35 e 6.7 |
|
CREATE VIEW |
Non supportato |
Le seguenti funzionalità sono supportate quando si utilizza Spark: SQL
-
Controllo granulare degli accessi sulle tabelle all'interno del metastore Hive; le policy possono essere create a livello di database, tabella e colonna.
-
Le policy di Apache Ranger possono includere policy di concessione e di negazione a utenti e gruppi.
-
Gli eventi di controllo vengono inviati ai CloudWatch registri.
Ridistribuisci la definizione del servizio da utilizzare o le INSERT istruzioni ALTER DDL
Nota
A partire da Amazon EMR 6.4, puoi usare Spark SQL con le istruzioni: INSERTINTO, INSERTOVERWRITE, o. ALTER TABLE A partire da Amazon EMR 6.7, puoi usare Spark SQL per creare o eliminare database e tabelle. Se si dispone di un'installazione esistente sul server Apache Ranger con le definizioni del servizio Apache Spark implementate, utilizzare il codice seguente per ridistribuire le definizioni del servizio.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
Installazione della definizione del servizio
L'installazione della definizione EMR del servizio Apache Spark richiede la configurazione del server Ranger Admin. Per informazioni, consulta Configurazione del server Admin Ranger.
Segui queste fasi per installare la definizione del servizio Apache Spark:
Fase 1: SSH accedere al server di amministrazione Apache Ranger
Per esempio:
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
Fase 2: Download della definizione del servizio e del plug-in del server Admin Apache Ranger
In una directory temporanea, scarica la definizione del servizio. Questa definizione del servizio è supportata dalle versioni Ranger 2.x.
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
Passaggio 3: installa il plug-in Apache Spark per Amazon EMR
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
Fase 4: Registrare la definizione del servizio Apache Spark per Amazon EMR
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
Se questo comando viene eseguito correttamente, nell'interfaccia utente di Ranger Admin viene visualizzato un nuovo servizio chiamato "AMAZON- EMR - SPARK «, come mostrato nell'immagine seguente (è mostrata la versione 2.0 di Ranger).
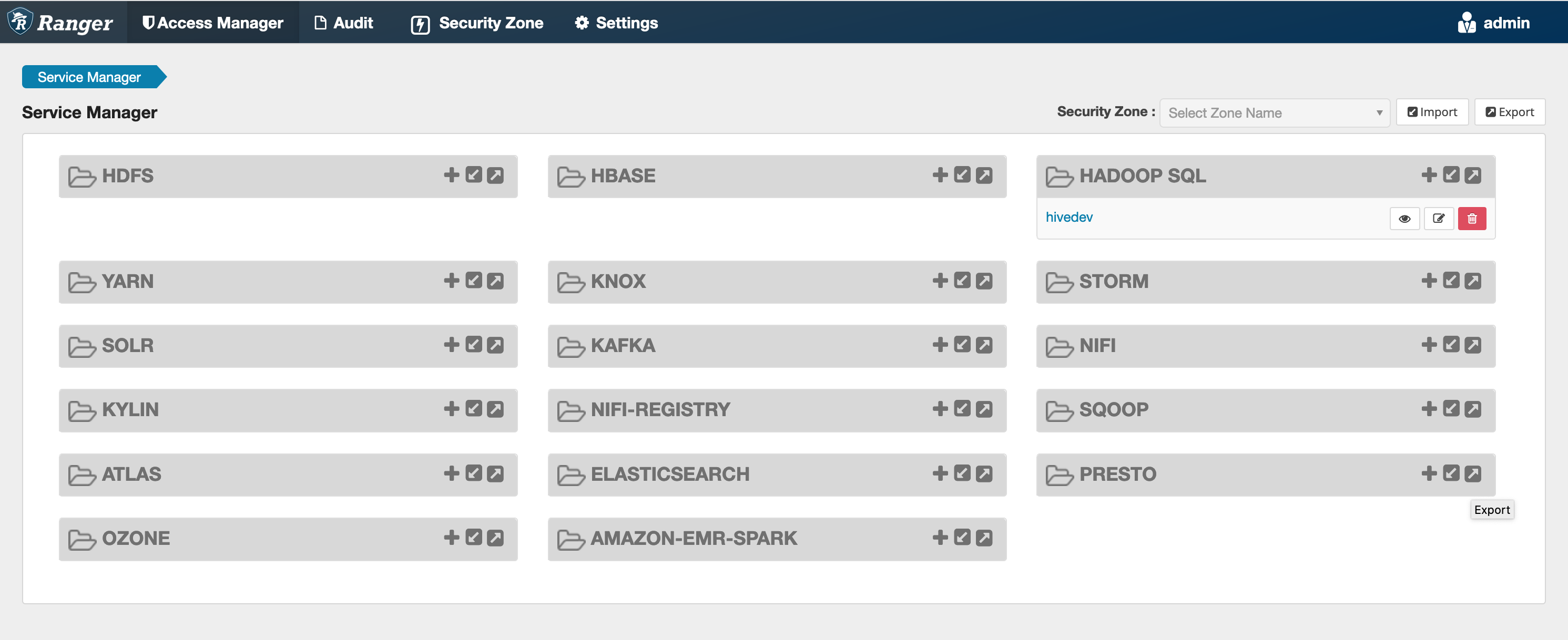
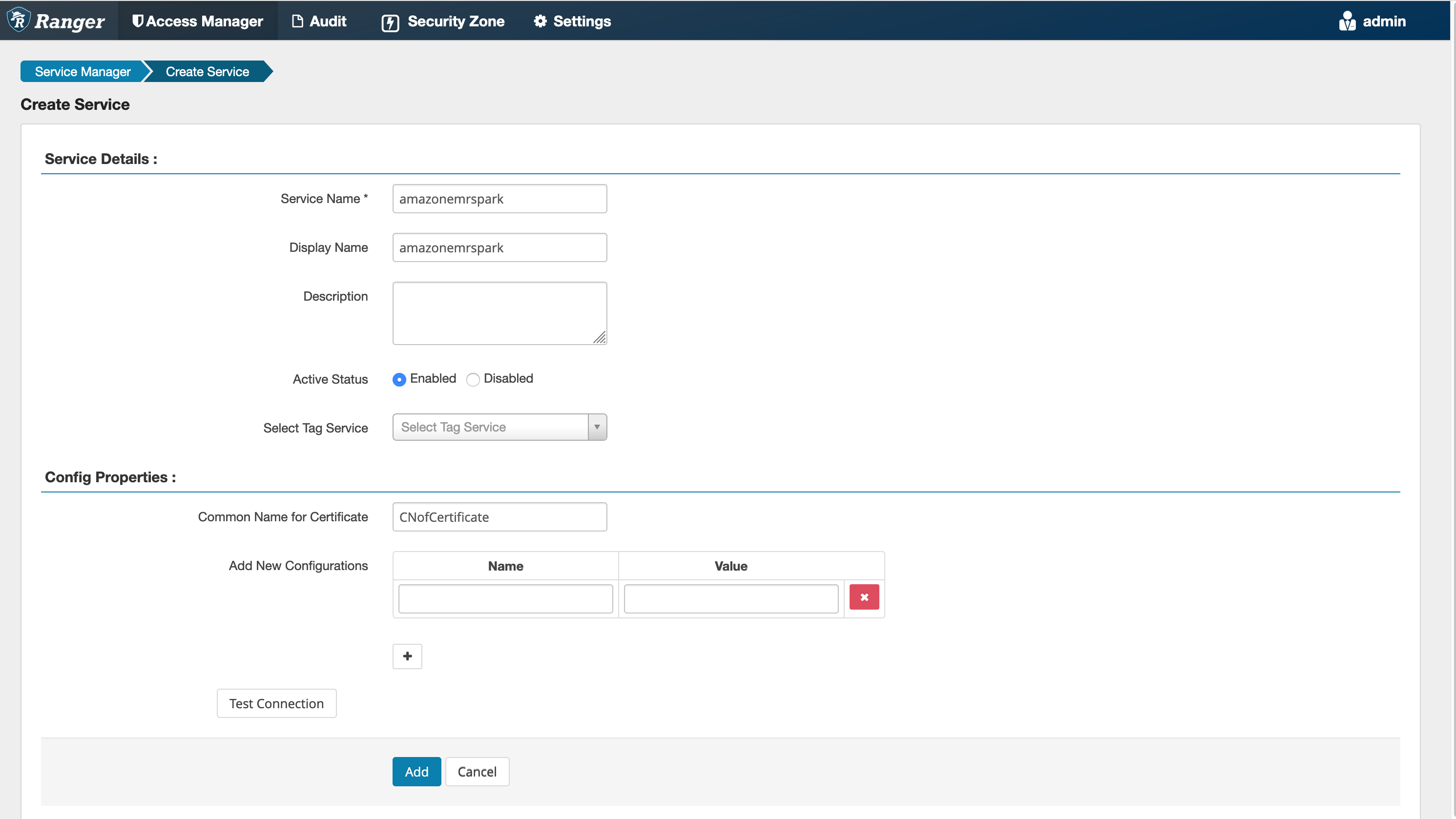
Fase 5: Creare un'istanza dell'applicazione AMAZON - EMR - SPARK
Nome del servizio (se visualizzato): il nome del servizio che verrà utilizzato. Il valore suggerito è amazonemrspark. Annotate questo nome di servizio poiché sarà necessario per la creazione di una configurazione EMR di sicurezza.
Nome visualizzato: il nome da visualizzare per questa istanza. Il valore suggerito è amazonemrspark.
Nome comune per certificato: il campo CN all'interno del certificato utilizzato per connettersi al server Admin da un plug-in client. Questo valore deve corrispondere al campo CN del TLS certificato creato per il plug-in.
Nota
Il TLS certificato per questo plugin avrebbe dovuto essere registrato nel trust store sul server Ranger Admin. Per ulteriori dettagli, consulta TLScertificati.
Creazione delle politiche Spark SQL
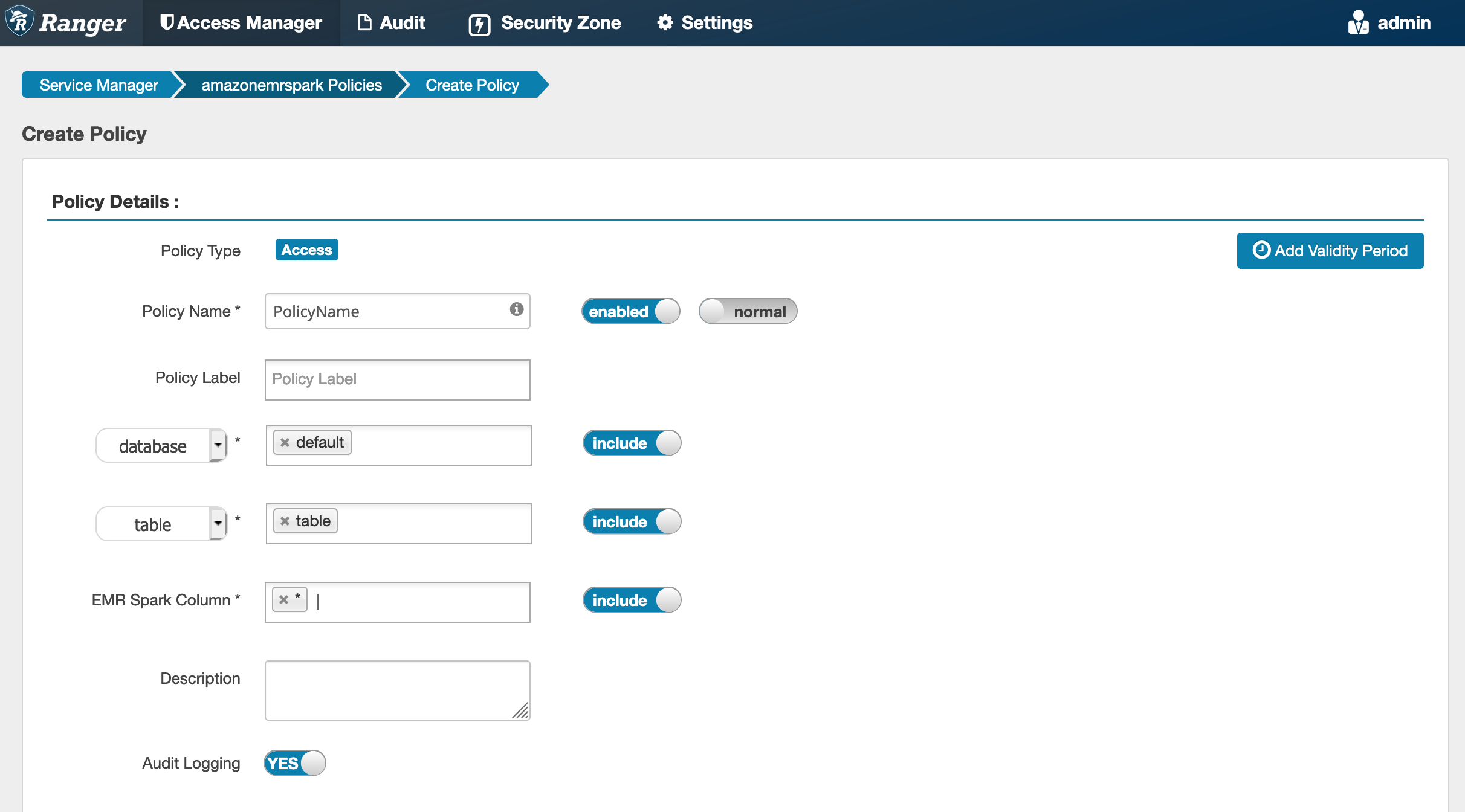
Quando si crea una nuova policy, i campi da compilare sono i seguenti:
Nome policy: il nome della policy.
Etichetta policy: un'etichetta che è possibile inserire in questa policy.
Database: il database a cui viene applicata questa policy. Il carattere jolly "*" rappresenta tutti i database.
Tabella: le tabelle a cui viene applicata questa policy. Il carattere jolly "*" rappresenta tutte le tabelle.
EMRColonna Spark: le colonne a cui si applica questa politica. Il carattere jolly "*" rappresenta tutte le colonne.
Description (Descrizione): la descrizione di questa policy.
Per specificare gli utenti e i gruppi, immetti gli utenti e i gruppi riportati di seguito per concedere le autorizzazioni. È inoltre possibile specificare delle esclusioni per consentire e negare le condizioni.
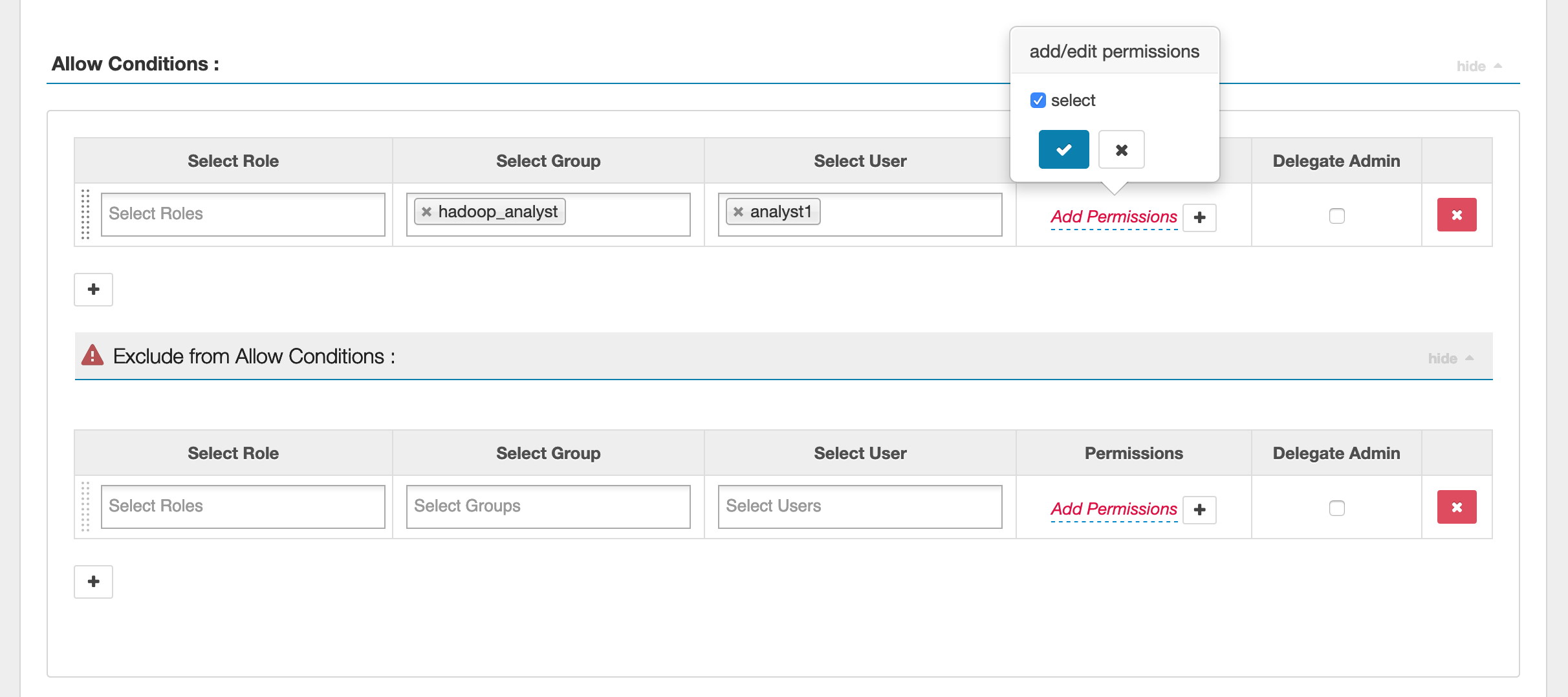
Dopo aver specificato le condizioni di autorizzazione e negazione, fai clic su Save (Salva).
Considerazioni
Ogni nodo all'interno del EMR cluster deve essere in grado di connettersi al nodo principale sulla porta 9083.
Limitazioni
Di seguito sono riportate le attuali limitazioni per il plug-in Apache Spark:
-
Record Server si connetterà sempre all'HMSesecuzione su un EMR cluster Amazon. Configura HMS per connetterti alla modalità remota, se necessario. Non inserire i valori di configurazione all'interno del file di configurazione Hive-site.xml di Apache Spark.
-
Le tabelle create utilizzando le sorgenti dati Spark su CSV o Avro non sono leggibili utilizzando. EMR RecordServer Utilizza Hive per creare e scrivere dati, per poi leggerli utilizzando Record.
-
Le tabelle Delta Lake e Hudi non sono supportate.
-
Gli utenti devono avere accesso al database predefinito. Questo è un requisito per Apache Spark.
-
Il server Admin Ranger non supporta il completamento automatico.
-
Il SQL plug-in Spark per Amazon non EMR supporta i filtri di riga o il mascheramento dei dati.
-
Quando si utilizza ALTER TABLE con SparkSQL, la posizione di una partizione deve essere la directory secondaria di una posizione di tabella. L'inserimento di dati in una partizione in cui la posizione della partizione è diversa da quella della tabella non è supportata.
