Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurazione di Flink in Amazon EMR
Configurazione di Flink con Hive Metastore e Catalogo Glue
Le versioni 6.9.0 e successive di Amazon EMR supportano sia Hive Metastore che AWS Glue Catalog con il connettore Apache Flink per Hive. Questa sezione descrive i passaggi necessari per configurare Catalogo AWS Glue e Hive Metastore con Flink.
Utilizzo di Hive Metastore
-
Crea un cluster EMR con il rilascio 6.9.0 o successivi e almeno due applicazioni: Hive e FLINK.
-
Utilizza script runner per eseguire il seguente script come funzione passo passo:
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar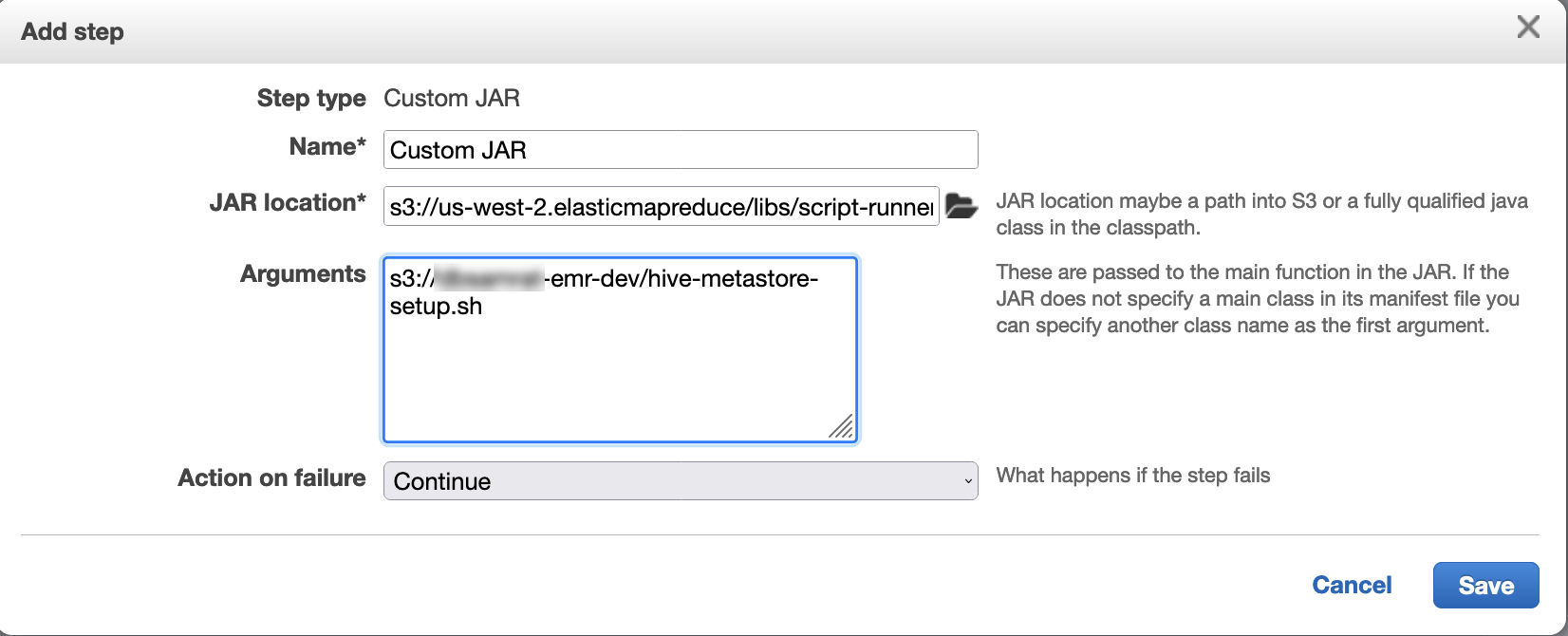
Usa il AWS Catalogo dati Glue
-
Crea un cluster EMR con il rilascio 6.9.0 o successivi e almeno due applicazioni: Hive e FLINK.
-
Seleziona Utilizza per i metadati delle tabelle Hive nelle impostazioni del Catalogo dati AWS Glue per abilitare il Catalogo dati nel cluster.
-
Utilizza script runner per eseguire il seguente script come funzione di fase: Esegui comandi e script su un cluster Amazon EMR:
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
Configurazione di Flink con un file di configurazione
Puoi utilizzare l'API di configurazione di Amazon EMR per configurare Flink con un file di configurazione. I file configurabili all'interno dell'API sono:
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
Il file di configurazione principale per Flink è flink-conf.yaml.
Per configurare il numero di slot di attività utilizzati per Flink dal AWS CLI
-
Creare un file,
configurations.json, con i seguenti contenuti:[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
Quindi, creare un cluster con la seguente configurazione:
aws emr create-cluster --release-labelemr-7.13.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
Nota
Puoi anche modificare alcune configurazioni con l'API Flink. Per ulteriori informazioni, consulta Concepts (Concetti)
Con Amazon EMR versione 5.21.0 e successive, puoi sovrascrivere le configurazioni del cluster e specificare classificazioni di configurazione aggiuntive per ogni gruppo di istanze in un cluster in esecuzione. A tale scopo, puoi utilizzare la console Amazon EMR, AWS Command Line Interface (AWS CLI) o l' AWS SDK. Per ulteriori informazioni, consulta Specifica di una configurazione per un gruppo di istanze in un cluster in esecuzione.
Opzioni di parallelismo
Il proprietario dell'applicazione sa quali risorse assegnare alle attività all'interno di Flink. Per gli esempi riportati in questa documentazione, utilizza lo stesso numero di attività delle istanze di attività utilizzate per l'applicazione. Generalmente lo consigliamo per il livello iniziale di parallelismo, ma è anche possibile aumentare la granularità del parallelismo con gli slot delle attività, che generalmente non dovrebbero superare il numero di core virtuali
Configurazione di Flink su un cluster EMR con nodi primari multipli
JobManager of Flink rimane disponibile durante il processo di failover del nodo primario in un cluster Amazon EMR con più nodi primari. A partire da Amazon EMR 5.28.0, anche l' JobManager alta disponibilità viene abilitata automaticamente. Non è necessaria alcuna configurazione manuale.
Con le versioni 5.27.0 o precedenti di Amazon EMR, JobManager esiste un singolo punto di errore. In caso di JobManager errore, perde tutti gli stati del processo e non riprende i processi in esecuzione. È possibile abilitare l' JobManager alta disponibilità configurando il conteggio dei tentativi di applicazione, il checkpoint e l'attivazione ZooKeeper come storage di stato per Flink, come dimostra l'esempio seguente:
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
È necessario configurare il numero massimo di tentativi master dell'applicazione per YARN e i tentativi dell'applicazione per Flink. Per ulteriori informazioni, consulta Configurazione dell'elevata disponibilità del cluster YARN
Configurazione delle dimensioni del processo di memoria
Per le versioni di Amazon EMR che utilizzano Flink 1.11.x, è necessario configurare la dimensione totale del processo di memoria sia per () che per JobManager (jobmanager.memory.process.size) in. TaskManager taskmanager.memory.process.size flink-conf.yaml È possibile impostare questi valori configurando il cluster con l'API di configurazione o rimuovendo manualmente i commenti da questi campi tramite SSH. Flink fornisce i seguenti valori di default.
-
jobmanager.memory.process.size: 1600m -
taskmanager.memory.process.size: 1728m
Per escludere il metaspace e l'overhead JVM, utilizza la dimensione totale della memoria Flink (taskmanager.memory.flink.size) anziché taskmanager.memory.process.size. Il valore di default per taskmanager.memory.process.size è 1280m. Non è consigliabile impostare sia taskmanager.memory.process.size che taskmanager.memory.flink.size.
Tutte le versioni di Amazon EMR che utilizzano Flink 1.12.0 e versioni successive hanno i valori di default elencati nell'open-source impostati per Flink come valori predefiniti su Amazon EMR, quindi non è necessario configurarli personalmente.
Configurazione della dimensione del file di output del log
I container di applicazioni Flink creano e scrivono in tre tipi di file di log: file .out, file .log e file .err. Solo i file .err vengono compressi e rimossi dal file system, mentre i file di log .log e .out rimangono nel file system. Per garantire che questi file di output rimangano gestibili e che il cluster rimanga stabile, è possibile configurare la rotazione dei log in log4j.properties per impostare un numero massimo di file e limitarne le dimensioni.
Amazon EMR versione 5.30.0 e successive
A partire dalla versione 5.30.0 di Amazon EMR, Flink utilizza il framework di registrazione log4j2 con il nome della classificazione di configurazione flink-log4j. Nella seguente configurazione di esempio viene illustrato il formato log4j2.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR versione 5.29.0 e precedenti
Con Amazon EMR versioni 5.29.0 e precedenti, Flink utilizza il framework di registrazione log4j. La seguente configurazione di esempio illustra il formato log4j
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Configurazione di Flink per l'esecuzione con Java 11
I rilasci 6.12.0 e successivi di Amazon EMR forniscono il supporto di runtime Java 11 per Flink. Le sezioni seguenti descrivono come configurare il cluster per fornire il supporto di runtime Java 11 per Flink.
Argomenti
Configurazione di Flink per Java 11 quando si crea un cluster
Per creare un cluster EMR con Flink e il runtime Java 11, procedi come segue. Il file di configurazione in cui aggiungere il supporto per il runtime Java 11 è flink-conf.yaml.
Configurazione di Flink per Java 11 su un cluster in esecuzione
Utilizza i seguenti passaggi per aggiornare un cluster EMR in esecuzione con Flink e il runtime Java 11. Il file di configurazione in cui aggiungere il supporto per il runtime Java 11 è flink-conf.yaml.
Verifica del runtime Java per Flink su un cluster in esecuzione
Per determinare il runtime Java per un cluster in esecuzione, accedi al nodo primario con SSH come descritto in Connessione al nodo primario con SSH. Quindi, esegui il comando riportato di seguito:
ps -ef | grep flink
Il comando ps con l'opzione -ef elenca tutti i processi in esecuzione sul sistema. È possibile filtrare l'output con grep per trovare le menzioni della stringa flink. Esamina l'output per il valore Java Runtime Environment (JRE), jre-XX. Nell'output seguente, jre-11 indica che Java 11 viene rilevato in fase di runtime per Flink.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
In alternativa, accedi al nodo primario con SSH e avvia una sessione Flink YARN con il comando flink-yarn-session -d. L'output mostra la Java Virtual Machine (JVM) per Flink, java-11-amazon-corretto nel seguente esempio:
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
