Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Prestazioni di Amazon FSx for Lustre
Questo capitolo fornisce argomenti sulle prestazioni di Amazon FSx for Lustre, inclusi alcuni importanti suggerimenti e raccomandazioni per massimizzare le prestazioni del file system.
Argomenti
Panoramica di
Amazon FSx for Lustre, Lustre basato sul popolare file system ad alte prestazioni, offre prestazioni di scalabilità orizzontale che aumentano linearmente con le dimensioni di un sistema di file. Lustrei file system si scalano orizzontalmente su più file server e dischi. Questa scalabilità offre a ciascun client l'accesso diretto ai dati archiviati su ciascun disco per eliminare molti dei colli di bottiglia presenti nei file system tradizionali. Amazon FSx for Lustre si basa Lustre sull'architettura scalabile per supportare alti livelli di prestazioni su un gran numero di client.
Come funzionano i file system FSx for Lustre
Ogni file system FSx for Lustre è costituito dai file server con cui i client comunicano e da un set di dischi collegati a ciascun file server che archivia i dati. Ogni file server utilizza una cache veloce in memoria per migliorare le prestazioni dei dati a cui si accede con maggiore frequenza. A seconda della classe di archiviazione, è possibile dotare il file server di una cache di lettura SSD opzionale. Quando un client accede ai dati archiviati nella cache in memoria o SSD, il file server non ha bisogno di leggerli dal disco, il che riduce la latenza e aumenta la quantità totale di throughput che è possibile gestire. Il diagramma seguente illustra i percorsi di un'operazione di scrittura, un'operazione di lettura eseguita dal disco e un'operazione di lettura eseguita dalla cache in memoria o SSD.
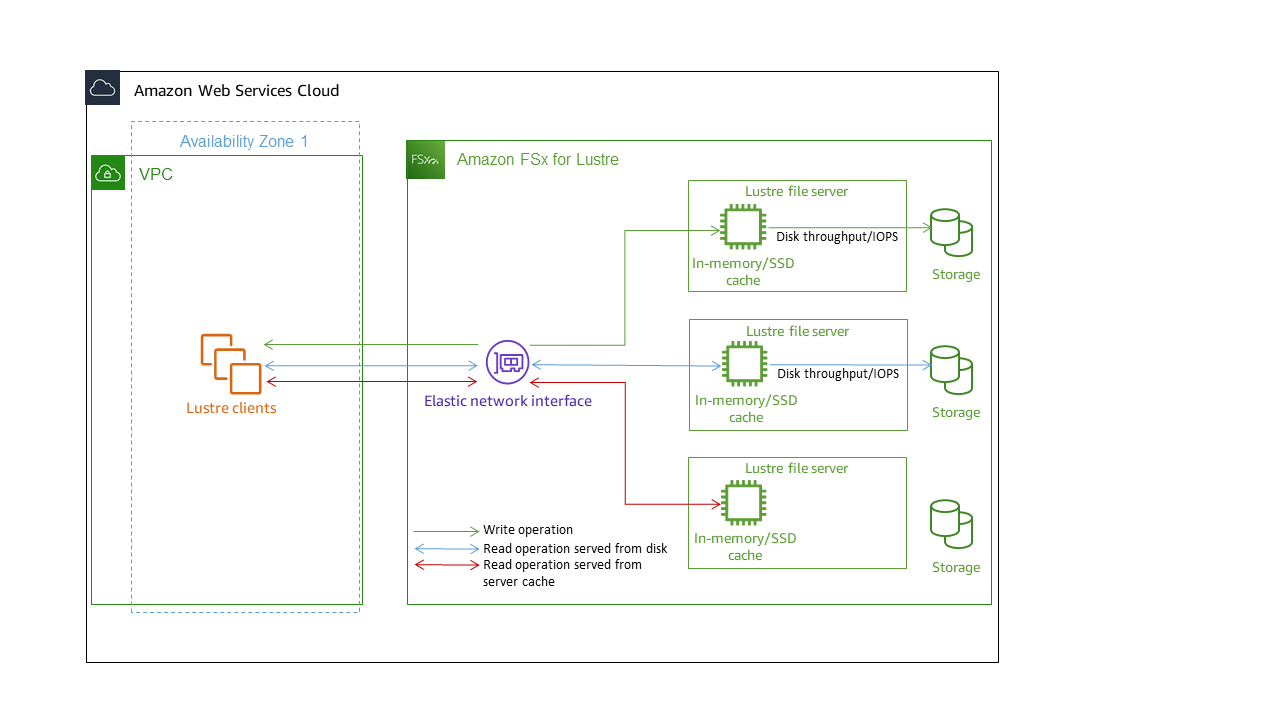
Quando si leggono i dati archiviati nella cache in memoria o SSD del file server, le prestazioni del file system sono determinate dalla velocità di trasmissione della rete. Quando si scrivono dati sul file system o quando si leggono dati che non sono archiviati nella cache in memoria, le prestazioni del file system sono determinate dalla riduzione del throughput di rete e del disco.
Per ulteriori informazioni sulla velocità effettiva di rete, sulla velocità effettiva su disco e sulle caratteristiche IOPS delle classi di storage SSD e HDD, consulta e. Caratteristiche prestazionali delle classi di storage SSD e HDD Caratteristiche Intelligent-Tiering prestazionali della classe di storage
Prestazioni dei metadati del file system
Le operazioni di I/O al secondo (IOPS) dei metadati del file system determinano il numero di file e directory che è possibile creare, elencare, leggere ed eliminare al secondo.
I file system Persistent 2 consentono di effettuare il provisioning dei metadati (IOPS) indipendentemente dalla capacità di storage e offrono una maggiore visibilità sul numero e sul tipo di metadati che le istanze client IOPS generano sul file system. Con i file system SSD, il provisioning degli IOPS dei metadati viene eseguito automaticamente in base alla capacità di storage fornita. La modalità automatica non è supportata sui file system. Intelligent-Tiering
Con i file system FSx for Lustre Persistent 2, il numero di IOPS di metadati forniti e il tipo di operazione sui metadati determinano la velocità di operazioni sui metadati che il file system è in grado di supportare. Il livello di IOPS di metadati da fornire determina il numero di IOPS assegnati per i dischi di metadati del file system.
| Tipo di operazione | Operazioni che è possibile eseguire al secondo per ogni IOPS di metadati fornito |
|---|---|
|
Creazione, apertura e chiusura di file |
2 |
|
Eliminazione di file |
1 |
|
Creazione e ridenominazione della cartella |
0.1 |
|
Eliminazione della directory |
0.2 |
Per i file system SSD, puoi scegliere di effettuare il provisioning degli IOPS dei metadati utilizzando la modalità automatica. In modalità automatica, Amazon FSx effettua automaticamente il provisioning degli IOPS dei metadati in base alla capacità di storage del file system in base alla tabella seguente:
| Capacità di storage del file system | Metadati IOPS inclusi in modalità automatica |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800—9600 GiB |
6000 |
|
12000—45600 GiB |
12000 |
|
≥48000 GiB |
12000 IOPS per 24000 GiB |
In User-provisioned modalità, è possibile scegliere facoltativamente di specificare il numero di IOPS di metadati da fornire. I valori validi sono:
Per i file system SSD, i valori validi sono
1500,,3000600012000, e multipli12000fino a un massimo di.192000Per i Intelligent-Tiering file system, i valori validi sono
6000e.12000
Per informazioni su come configurare Metadata IOPS, vedere. Gestione delle prestazioni dei metadati Tieni presente che paghi per gli IOPS dei metadati assegnati al di sopra del numero predefinito di IOPS di metadati per il tuo file system.
Throughput verso le singole istanze del client
Se stai creando un file system con una capacità di throughput superiore a 10 GBps, ti consigliamo di abilitare Elastic Fabric Adapter (EFA) per ottimizzare il throughput per istanza client. Per ottimizzare ulteriormente il throughput per istanze client, i EFA-enabled file system supportano anche GPUDirect Storage per le istanze client EFA-enabled NVIDIA e ENA Express per le istanze GPU-based client ENA. Express-enabled
Il throughput che è possibile trasferire a una singola istanza client dipende dalla scelta del tipo di file system e dall'interfaccia di rete dell'istanza client.
| Tipo di file system | Interfaccia di rete dell'istanza del client | Velocità effettiva massima per client, Gbps |
|---|---|---|
|
Non EFA-enabled |
Qualsiasi |
100 Gbps* |
|
EFA-enabled |
ENA |
100 Gbps* |
|
EFA-enabled |
ENA Express |
100 Gb/s |
|
EFA-enabled |
EFA |
700 Gbps |
|
EFA-enabled |
EFA con GDS |
1200 Gbps |
Nota
* Il traffico tra una singola istanza client e un singolo server di object storage FSx for Lustre è limitato a 5 Gbps. Fate riferimento a Indirizzi IP per file system per il numero di server di storage a oggetti su cui si basa il file system FSx for Lustre.
Layout di storage del file system
Tutti i dati dei file in esso contenuti Lustre vengono archiviati in volumi di archiviazione denominati Object Storage Targets (OST). Tutti i metadati dei file (inclusi nomi di file, timestamp, autorizzazioni e altro) vengono archiviati in volumi di archiviazione denominati metadata target (MDT). I file system Amazon FSx for Lustre sono composti da uno o più MDT e più OST. Amazon FSx for Lustre distribuisce i dati dei file tra gli OST che compongono il file system per bilanciare la capacità di storage con il throughput e il carico IOPS.
Per visualizzare l'utilizzo dello storage dell'MDT e degli OST che costituiscono il file system, esegui il comando seguente da un client su cui è montato il file system.
lfs df -hmount/path
L'output di questo comando è simile al seguente.
Esempio
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
Stripaggio dei dati nel file system
È possibile ottimizzare le prestazioni di throughput del file system con lo striping dei file. Amazon FSx for Lustre distribuisce automaticamente i file tra i sistemi OST per garantire che i dati vengano serviti da tutti i server di storage. Puoi applicare lo stesso concetto a livello di file configurando il modo in cui i file vengono distribuiti su più OST.
Lo striping significa che i file possono essere suddivisi in più blocchi che vengono poi archiviati su OST diversi. Quando un file viene distribuito su più OST, le richieste di lettura o scrittura al file vengono distribuite tra tali OST, aumentando il throughput aggregato o gli IOPS che le applicazioni possono gestire.
Di seguito sono riportati i layout predefiniti per i file system Amazon FSx for Lustre.
Per i file system creati prima del 18 dicembre 2020, il layout predefinito specifica un numero di strisce pari a 1. Ciò significa che, a meno che non venga specificato un layout diverso, ogni file creato in Amazon FSx for Lustre utilizzando strumenti Linux standard viene archiviato su un singolo disco.
Per i file system creati dopo il 18 dicembre 2020, il layout predefinito è un layout di file progressivo in cui i file di dimensioni inferiori a 1 GiB vengono archiviati in un'unica striscia e ai file più grandi viene assegnato un numero di strisce pari a 5.
Per i file system creati dopo il 25 agosto 2023, il layout predefinito è un layout di file progressivo a 4 componenti, come spiegato in. Layout di file progressivi
Per tutti i file system, indipendentemente dalla data di creazione, i file importati da Amazon S3 non utilizzano il layout predefinito, ma utilizzano invece il layout nel parametro del
ImportedFileChunkSizefile system. S3-imported i file più grandi di quelliImportedFileChunkSizeverranno archiviati su più OST con un numero di strisce pari a.(FileSize / ImportedFileChunksize) + 1Il valore predefinito diImportedFileChunkSizeè 1GiB.
È possibile visualizzare la configurazione del layout di un file o di una directory utilizzando il lfs getstripe comando.
lfs getstripepath/to/filename
Questo comando riporta il numero di strisce, la dimensione e l'offset delle strisce di un file. Il numero di strisce è il numero di OST su cui è suddiviso il file. La dimensione dello stripe indica la quantità di dati continui archiviati su un OST. Lo stripe offset è l'indice del primo OST su cui è distribuito il file.
Modifica della configurazione dello striping
I parametri di layout di un file vengono impostati quando il file viene creato per la prima volta. Utilizzate il lfs setstripe comando per creare un nuovo file vuoto con un layout specificato.
lfs setstripefilename--stripe-countnumber_of_OSTs
Il lfs setstripe comando influisce solo sul layout di un nuovo file. Utilizzatelo per specificare il layout di un file prima di crearlo. Puoi anche definire un layout per una directory. Una volta impostato su una directory, tale layout viene applicato a ogni nuovo file aggiunto a quella directory, ma non ai file esistenti. Ogni nuova sottodirectory creata eredita anche il nuovo layout, che viene quindi applicato a qualsiasi nuovo file o directory creato all'interno di quella sottodirectory.
Per modificare il layout di un file esistente, utilizzate il comando. lfs migrate Questo comando copia il file secondo necessità per distribuirne il contenuto in base al layout specificato nel comando. Ad esempio, i file che vengono aggiunti o le cui dimensioni sono aumentate non modificano il numero di strisce, quindi è necessario migrarli per modificare il layout del file. In alternativa, è possibile creare un nuovo file utilizzando il lfs setstripe comando per specificarne il layout, copiare il contenuto originale nel nuovo file e quindi rinominare il nuovo file per sostituire il file originale.
In alcuni casi la configurazione di layout predefinita non è ottimale per il carico di lavoro. Ad esempio, un file system con decine di OST e un gran numero di file da più gigabyte può ottenere prestazioni migliori suddividendo i file su più del valore di numero di stripe predefinito di cinque OST. La creazione di file di grandi dimensioni con un numero di stripe basso può causare problemi di I/O prestazioni e può anche causare il riempimento degli OST. In questo caso, puoi creare una directory con un numero maggiore di strisce per questi file.
La configurazione di un layout a strisce per file di grandi dimensioni (in particolare file di dimensioni superiori a un gigabyte) è importante per i seguenti motivi:
Migliora la velocità effettiva consentendo a più OST e ai server associati di contribuire con IOPS, larghezza di banda di rete e risorse CPU durante la lettura e la scrittura di file di grandi dimensioni.
Riduce la probabilità che un piccolo sottoinsieme di OST diventi hot spot che limitano le prestazioni complessive del carico di lavoro.
Impedisce che un singolo file di grandi dimensioni riempia un OST, causando probabilmente errori di riempimento del disco.
Non esiste un'unica configurazione di layout ottimale per tutti i casi d'uso. Per una guida dettagliata sui layout dei file, consulta Managing File Layout (Striping) and Free Space nella documentazione
Il layout a strisce è particolarmente importante per i file di grandi dimensioni, specialmente per i casi d'uso in cui i file hanno normalmente dimensioni di centinaia di megabyte o più. Per questo motivo, il layout predefinito per un nuovo file system assegna un numero di strisce pari a cinque per i file di dimensioni superiori a 1 GiB.
Il numero di strisce è il parametro di layout da regolare per i sistemi che supportano file di grandi dimensioni. Il numero di strisce specifica il numero di volumi OST che conterranno porzioni di un file a strisce. Ad esempio, con un numero di strisce pari a 2 e una dimensione di banda di 1 MiB, Lustre scrive blocchi di file da 1 MiB alternativi su ciascuna delle due OST.
Il numero effettivo di strisce è il minore tra il numero effettivo di volumi OST e il valore di conteggio delle strisce specificato. È possibile utilizzare lo speciale valore di conteggio delle strisce
-1per indicare che le strisce devono essere posizionate su tutti i volumi OST.L'impostazione di un numero elevato di strisce per file di piccole dimensioni non è ottimale perché per determinate operazioni è Lustre necessaria una connessione di rete a tutte le OST del layout, anche se il file è troppo piccolo per occupare spazio su tutti i volumi OST.
È possibile impostare un layout progressivo dei file (PFL) che consenta di modificare il layout di un file in base alle dimensioni. Una configurazione PFL può semplificare la gestione di un file system con una combinazione di file grandi e piccoli senza dover impostare esplicitamente una configurazione per ogni file. Per ulteriori informazioni, consulta Layout di file progressivi.
La dimensione predefinita di Stripe è 1 MiB. L'impostazione di un offset a strisce può essere utile in circostanze particolari, ma in generale è meglio non specificarlo e utilizzare l'impostazione predefinita.
Layout di file progressivi
È possibile specificare una configurazione PFL (Progressive File Layout) per una directory per specificare diverse configurazioni di stripe per file di piccole e grandi dimensioni prima di popolarla. Ad esempio, è possibile impostare un PFL nella directory di primo livello prima che i dati vengano scritti su un nuovo file system.
Per specificare una configurazione PFL, utilizzate il lfs setstripe comando con -E opzioni per specificare i componenti di layout per file di dimensioni diverse, come il comando seguente:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
Questo comando imposta quattro componenti di layout:
Il primo componente (
-E 100M -c 1) indica un valore di conteggio delle strisce pari a 1 per file di dimensioni fino a 100 MiB.Il secondo componente (
-E 10G -c 8) indica un numero di strisce pari a 8 per file di dimensioni fino a 10 GiB.Il terzo componente (
-E 100G -c 16) indica un numero di strisce pari a 16 per file di dimensioni fino a 100 GiB.Il quarto componente (
-E -1 -c 32) indica un numero di strisce pari a 32 per file di dimensioni superiori a 100 GiB.
Importante
L'aggiunta di dati a un file creato con un layout PFL popolerà tutti i relativi componenti di layout. Ad esempio, con il comando a 4 componenti mostrato sopra, se create un file da 1 MiB e poi aggiungete dati alla fine del file, il layout del file si espanderà fino ad avere un numero di strisce pari a -1, vale a dire tutti gli OST del sistema. Ciò non significa che i dati verranno scritti su ogni OST, ma un'operazione come la lettura della lunghezza del file invierà una richiesta in parallelo a ogni OST, aggiungendo un carico di rete significativo al file system.
Pertanto, fate attenzione a limitare il numero di strisce per qualsiasi file di piccola o media lunghezza a cui successivamente possono essere aggiunti dati. Poiché i file di log di solito crescono con l'aggiunta di nuovi record, Amazon FSx for Lustre assegna un numero di stripe predefinito pari a 1 a qualsiasi file creato in modalità di aggiunta, indipendentemente dalla configurazione di stripe predefinita specificata dalla relativa directory principale.
La configurazione PFL predefinita sui file system Amazon FSx for Lustre creati dopo il 25 agosto 2023 viene impostata con questo comando:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
I clienti con carichi di lavoro che hanno un accesso altamente simultaneo a file di medie e grandi dimensioni trarranno probabilmente vantaggio da un layout con più strisce per dimensioni più piccole e dallo striping su tutti gli OST per i file più grandi, come mostrato nel layout di esempio a quattro componenti.
Monitoraggio delle prestazioni e dell'utilizzo
Ogni minuto, Amazon FSx for Lustre invia ad Amazon i parametri di utilizzo per ogni disco (MDT e OST). CloudWatch
Per visualizzare i dettagli aggregati sull'utilizzo del file system, puoi consultare la statistica Sum di ogni metrica. Ad esempio, la somma delle DataReadBytes statistiche riporta la velocità di lettura totale registrata da tutti gli OST di un file system. Analogamente, la somma delle FreeDataStorageCapacity statistiche riporta la capacità di archiviazione totale disponibile per i dati dei file nel file system.
Per ulteriori informazioni sul monitoraggio delle prestazioni del file system, vedereMonitoraggio dei file system Amazon FSx for Lustre.
