Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Gestione della capacità di archiviazione
Amazon FSx for NetApp ONTAP offre una serie di funzionalità relative allo storage che puoi utilizzare per gestire la capacità di storage sul tuo file system.
Argomenti
Livelli di storage FSx for ONTAP
I livelli di storage sono i supporti di storage fisici per un file system Amazon FSx NetApp for ONTAP. FSx for ONTAP offre i seguenti livelli di storage:
Livello SSD: lo storage su unità a stato solido (SSD) ad alte prestazioni fornito dall'utente e progettato appositamente per la parte attiva del set di dati.
Livello di pool di capacità: storage completamente elastico con scalabilità automatica fino a petabyte e ottimizzato in termini di costi per i dati a cui si accede raramente.
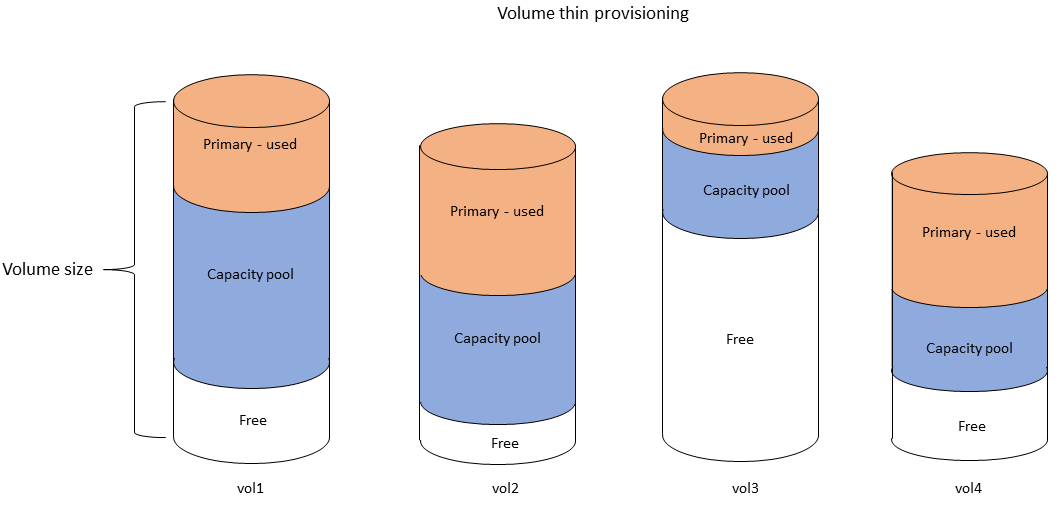
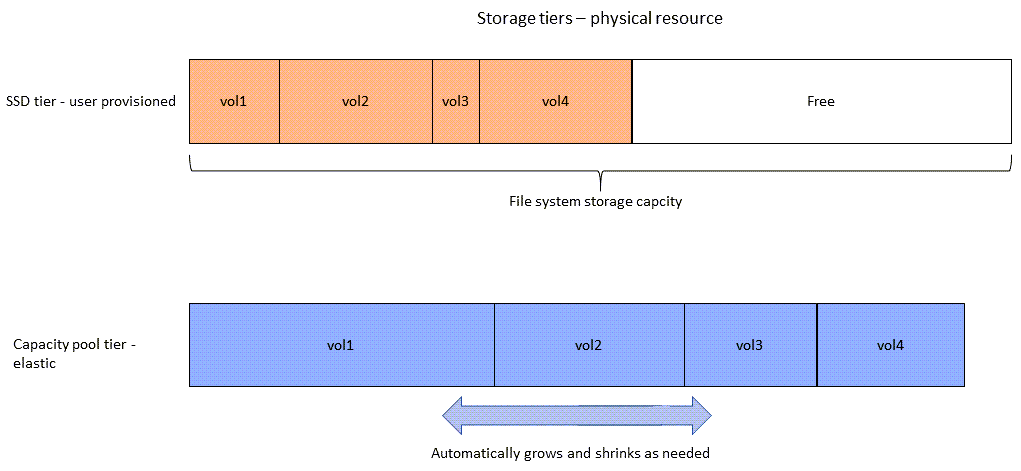
Un volume FSx for ONTAP è una risorsa virtuale che, come le cartelle, non consuma capacità di storage. I dati archiviati, e che utilizzano lo storage fisico, risiedono all'interno di volumi. Quando crei un volume, ne specifichi la dimensione, che puoi modificare dopo la creazione. I volumi FSx for ONTAP sono dotati di thin provisioning e lo storage del file system non è riservato in anticipo. Invece, lo storage su SSD e pool di capacità viene allocato dinamicamente, in base alle esigenze. Una politica di tiering, configurata a livello di volume, determina se e quando i dati archiviati nel livello SSD passano al livello del pool di capacità.
Il diagramma seguente illustra un esempio di dati disposti su più volumi FSx for ONTAP in un file system.
Il diagramma seguente illustra come la capacità di archiviazione fisica del file system viene consumata dai dati nei quattro volumi del diagramma precedente.
È possibile ridurre i costi di storage scegliendo la politica di suddivisione in più livelli che meglio soddisfa i requisiti per ogni volume del file system. Per ulteriori informazioni, consulta Suddivisione dei dati su più livelli.
Scelta della giusta quantità di storage SSD per file system
Quando si sceglie la quantità di capacità di archiviazione SSD per il file system FSx for ONTAP, è necessario tenere presente i seguenti elementi che influiscono sulla quantità di storage SSD disponibile per l'archiviazione dei dati:
Capacità di archiviazione riservata al sovraccarico del NetApp software ONTAP.
Metadati dei file
Dati scritti di recente
File che intendi archiviare su un dispositivo di archiviazione SSD, che si tratti di dati che non hanno raggiunto il periodo di raffreddamento o di dati che hai letto di recente e che sono stati recuperati su SSD.
Come viene utilizzata l'archiviazione SSD
L'archiviazione SSD del file system viene utilizzata per una combinazione di software NetApp ONTAP (overhead), metadati dei file e dati.
NetApp Sovraccarico del software ONTAP
Come altri file system NetApp ONTAP, fino al 16% della capacità di archiviazione SSD di un file system è riservata al sovraccarico di ONTAP, il che significa che non è disponibile per l'archiviazione dei file. L'overhead ONTAP viene allocato come segue:
L'11% è riservato al software ONTAP NetApp . Per i file system con oltre 30 tebibyte (TiB) di capacità di archiviazione SSD, il 6% è riservato.
Il 5% è riservato alle istantanee aggregate, necessarie per sincronizzare i dati tra entrambi i file server di un file system.
Metadati dei file
I metadati dei file in genere occupano il 3-7% della capacità di archiviazione utilizzata dai file. Questa percentuale dipende dalla dimensione media dei file (una dimensione media di file inferiore richiede più metadati) e dalla quantità di risparmio in termini di efficienza di archiviazione ottenuto sui file. Tieni presente che i metadati dei file non traggono vantaggio dai risparmi in termini di efficienza dello storage. Puoi utilizzare le seguenti linee guida per stimare la quantità di storage SSD utilizzata per i metadati sul tuo file system.
| Dimensione media del file | Dimensione dei metadati come percentuale dei dati del file |
|---|---|
|
4 KB |
7% |
|
8 KB |
3,5% |
|
32 KB o superiore |
1-3% |
Quando si ridimensiona la quantità di capacità di archiviazione SSD necessaria per i metadati dei file che si intende archiviare sul livello del pool di capacità, si consiglia di utilizzare un rapporto conservativo di 1 GiB di storage SSD per ogni 10 GiB di dati che si prevede di archiviare sul livello del pool di capacità.
Dati di file archiviati sul livello SSD
Oltre al set di dati attivo e a tutti i metadati dei file, tutti i dati scritti sul file system vengono inizialmente scritti sul livello SSD prima di essere suddivisi in livelli di storage con pool di capacità. Ciò è vero indipendentemente dalla politica di suddivisione in più livelli del volume, con l'eccezione che i dati vengono scritti direttamente nello storage del pool di capacità quando vengono utilizzati SnapMirror su un volume configurato con una politica di suddivisione in più livelli dei dati.
Le letture casuali dal livello del pool di capacità vengono memorizzate nella cache del livello SSD, a condizione che il livello SSD sia utilizzato al di sotto del 90%. Per ulteriori informazioni, consulta Suddivisione dei dati su più livelli.
Utilizzo della capacità SSD consigliato
Si consiglia di non superare l'80% di utilizzo del livello di storage SSD su base continuativa. Per i file system di seconda generazione, consigliamo inoltre di non superare l'80% di utilizzo degli aggregati del file system su base continuativa. Questi consigli sono coerenti con quelli consigliati per NetApp ONTAP. Poiché il livello SSD del file system viene utilizzato anche per lo staging delle scritture e per le letture casuali dal livello del pool di capacità, eventuali cambiamenti improvvisi nei modelli di accesso possono causare un rapido aumento dell'utilizzo del livello SSD.
Al 90% di utilizzo dell'unità SSD, i dati letti dal livello del pool di capacità non vengono più memorizzati nella cache sul livello SSD, in modo che la capacità SSD residua venga preservata per eventuali nuovi dati scritti sul file system. Ciò fa sì che le letture ripetute degli stessi dati dal livello del pool di capacità vengano lette dallo storage del pool di capacità anziché essere memorizzate nella cache e lette dal livello SSD, il che può influire sulla capacità di throughput del file system.
Tutte le funzionalità di suddivisione in più livelli si interrompono quando il livello SSD raggiunge o supera il 98% di utilizzo. Per ulteriori informazioni, consulta Soglie di suddivisione in più livelli.
Efficienza dello storage
NetApp ONTAPoffre funzionalità di efficienza dello storage a livello di blocco a livello di volume che includono compressione, compattazione e deduplicazione. Queste funzionalità consentono di risparmiare fino al 65% in termini di capacità di storage per le condivisioni generiche di file, senza compromettere le prestazioni. È possibile abilitare l'efficienza dello storage in base al volume. Queste funzionalità riducono la quantità di capacità di archiviazione consumata dai dati, consentendoti di consumare meno spazio di archiviazione su SSD, pool di capacità e storage di backup. È possibile abilitare la compressione e la deduplicazione su ogni volume per i dati nell'archiviazione SSD. I risparmi di storage derivanti dalla compressione e dalla deduplicazione nello storage SSD vengono preservati quando i dati vengono suddivisi in livelli di storage in base al pool di capacità. L'efficienza dello storage è sempre abilitata per i dati di backup, indipendentemente dalla configurazione dell'efficienza di archiviazione del file system.
La tabella seguente mostra alcuni esempi di risparmi tipici in termini di storage.
| Solo compressione | Solo deduplicazione | Compressione e deduplicazione | |
|---|---|---|---|
| General-purpose condivisioni di file | 50% | 30% | 65% |
| Server e desktop virtuali | 55% | 70% | 70% |
| Database | 65-70% | 0% | 65-70% |
| Dati ingegneristici | 55% | 30% | 75% |
| Dati geosismici | 40% | 3% | 40% |
Per la maggior parte dei carichi di lavoro, l'abilitazione della compressione e della deduplicazione non influirà negativamente sulle prestazioni del file system. Per la maggior parte dei carichi di lavoro, la compressione aumenta le prestazioni complessive. Per fornire letture e scritture veloci dalla cache RAM, i file server FSx for ONTAP sono dotati di livelli di larghezza di banda di rete più elevati sulle schede di interfaccia di rete (NIC) front-end rispetto a quelli disponibili tra i file server e i dischi di archiviazione. Poiché la compressione dei dati riduce la quantità di dati inviati tra i file server e i dischi di storage, per la maggior parte dei carichi di lavoro, si noterà un aumento della capacità di trasmissione complessiva del file system quando si utilizza la compressione dei dati. L'aumento della capacità di trasmissione correlata alla compressione dei dati verrà limitato una volta saturata la scheda NIC front-end del file system.
Amazon FSx for NetApp ONTAP supporta anche altre ONTAP funzionalità che consentono di risparmiare spazio, tra cui istantanee, thin provisioning e volumi. FlexClone
Le funzionalità di efficienza dello storage non sono abilitate per impostazione predefinita. È possibile abilitarle come segue:
Sul volume root di una SVM quando si crea un file system.
Quando crei un nuovo volume.
Quando modifichi un volume esistente.
Per visualizzare la quantità di risparmio di storage su un file system con l'efficienza dello storage abilitata, vedereMonitoraggio del risparmio in termini di efficienza.
Calcolo dei risparmi in termini di efficienza dello storage
È possibile utilizzare le metriche del CloudWatch file StorageUsed system LogicalDataStored and FSx for ONTAP per calcolare i risparmi di storage derivanti da compressione, deduplicazione, compattazione, istantanee e. FlexClones Queste metriche hanno un'unica dimensione,. FileSystemId Per ulteriori informazioni, consulta Metriche del file system.
Per calcolare i risparmi in termini di efficienza dello storage in byte, prendi la media di
StorageUsedun determinato periodo e la sottrai dalla media dello stesso periodo.LogicalDataStoredPer calcolare i risparmi in termini di efficienza dello storage come percentuale della dimensione totale dei dati logici, prendiamo il valore di in un determinato periodo e lo
AverageStorageUsedsottraiamo dal risultato ottenuto nello stesso periodo.AverageLogicalDataStoredQuindi dividi la differenza per il o nello stesso periodoAverage.LogicalDataStored
Esempio di dimensionamento di un SSD
Si supponga di voler archiviare 100 TiB di dati per un'applicazione in cui l'80% dei dati viene utilizzato raramente. In questo scenario, l'80% (80 TiB) dei dati viene automaticamente trasferito al livello del pool di capacità e il restante 20% (20 TiB) rimane nello storage SSD. In base al tipico risparmio di efficienza dello storage del 65% per carichi di lavoro di condivisione di file generici, ciò equivale a 7 TiB di dati. Per mantenere un tasso di utilizzo dell'SSD dell'80%, sono necessari 8,75 TiB di capacità di storage SSD per i 20 TiB di dati a cui si accede attivamente. La quantità di storage SSD fornita deve inoltre tenere conto del sovraccarico di archiviazione del software ONTAP del 16%, come illustrato nel calcolo seguente.
ssdNeeded = ssdProvisioned * (1 - 0.16) 8.75 TiB / 0.84 = ssdProvisioned 10.42 TiB = ssdProvisioned
Quindi, in questo esempio, è necessario effettuare il provisioning di almeno 10,42 TiB di storage SSD. Utilizzerai anche 28 TiB di storage con pool di capacità per i restanti 80 TiB di dati a cui si accede raramente.
