Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS Lake Formation: Come funziona
AWS Lake Formation fornisce un modello di autorizzazioni del sistema di gestione dei database relazionali (RDBMS) per concedere o revocare l'accesso alle risorse del catalogo dati come database, tabelle e colonne con dati sottostanti in Amazon S3. Le autorizzazioni Lake Formation, facili da gestire, sostituiscono le complesse policy dei bucket di Amazon S3 e le politiche corrispondenti. IAM
In Lake Formation, puoi implementare le autorizzazioni su due livelli:
Applicazione delle autorizzazioni a livello di metadati sulle risorse del Data Catalog come database e tabelle
Gestione delle autorizzazioni di accesso allo storage sui dati sottostanti archiviati in Amazon S3 per conto di motori integrati
Flusso di lavoro per la gestione delle autorizzazioni di Lake Formation
Lake Formation si integra con i motori analitici per interrogare gli archivi di dati e gli oggetti di metadati di Amazon S3 registrati con Lake Formation. Il diagramma seguente illustra come funziona la gestione delle autorizzazioni in Lake Formation.
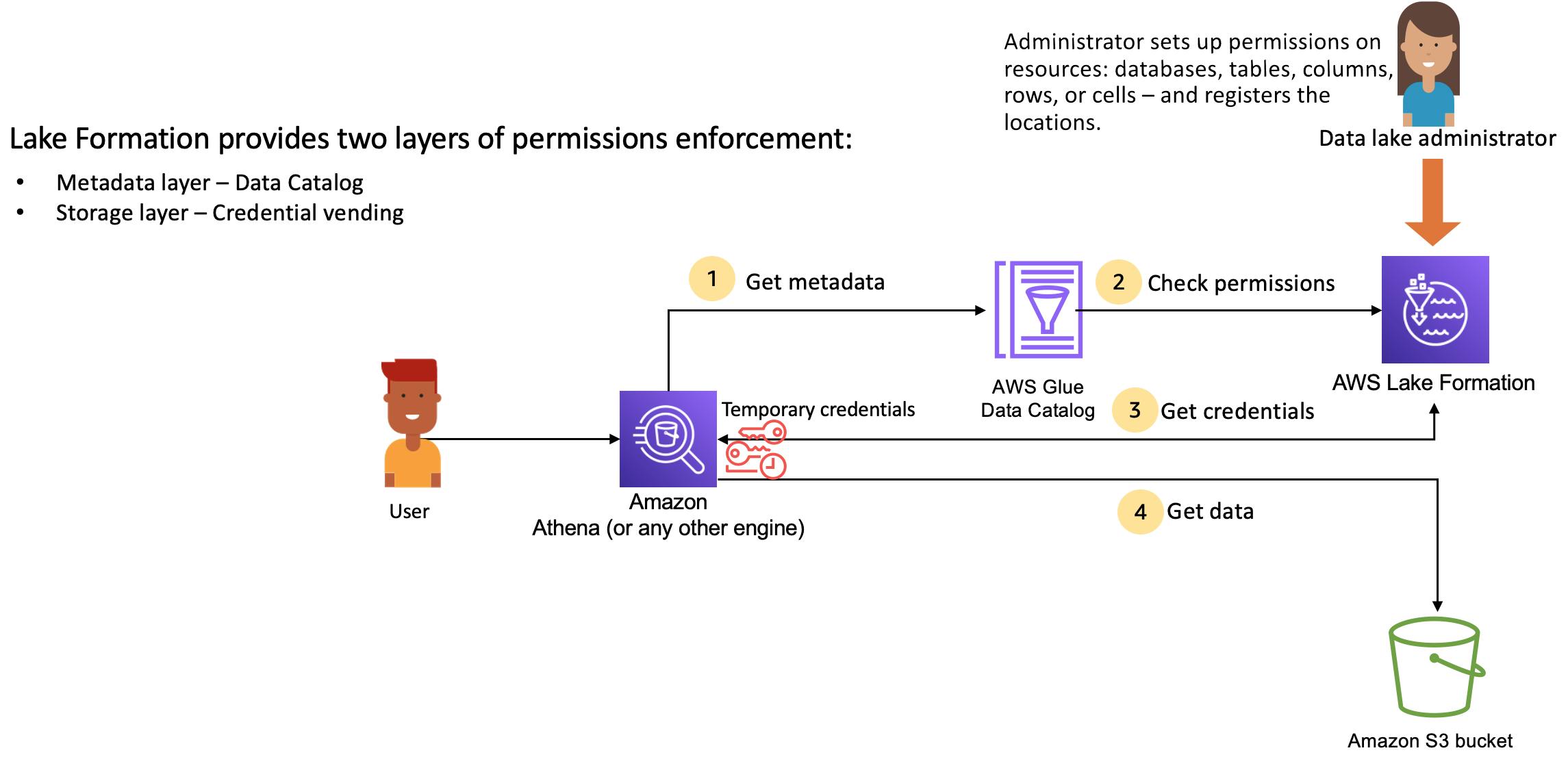
Fasi di alto livello per la gestione dei permessi di Lake Formation
Prima che Lake Formation possa fornire controlli di accesso per i dati nel tuo data lake, un amministratore del data lake o un utente con autorizzazioni amministrative imposta le politiche utente delle singole tabelle Data Catalog per consentire o negare l'accesso alle tabelle Data Catalog utilizzando le autorizzazioni di Lake Formation.
Quindi, l'amministratore del data lake o un utente delegato dall'amministratore concede le autorizzazioni di Lake Formation agli utenti sui database e sulle tabelle di Data Catalog e registra la posizione Amazon S3 della tabella con Lake Formation.
Ottieni metadati: un principale (utente) invia una query o ETL uno script a un motore di analisi integrato come Amazon Athena AWS Glue, Amazon o Amazon Redshift EMR Spectrum. Il motore analitico integrato identifica la tabella richiesta e invia una richiesta di metadati al Data Catalog.
-
Controlla le autorizzazioni: il Data Catalog controlla le autorizzazioni dell'utente con Lake Formation e, se l'utente è autorizzato ad accedere alla tabella, restituisce al motore i metadati che l'utente può vedere.
-
Ottieni credenziali: il Data Catalog consente al motore di sapere se la tabella è gestita da Lake Formation o meno. Se i dati sottostanti sono registrati con Lake Formation, il motore analitico richiede a Lake Formation di fornire l'accesso ai dati concedendo un accesso temporaneo.
-
Ottieni dati: se l'utente è autorizzato ad accedere alla tabella, Lake Formation fornisce l'accesso temporaneo al motore analitico integrato. Utilizzando l'accesso temporaneo, il motore analitico recupera i dati da Amazon S3 ed esegue i filtri necessari come il filtraggio di colonne, righe o celle. Quando il motore termina l'esecuzione del lavoro, restituisce i risultati all'utente. Questo processo è chiamato vendita di credenziali.
Se la tabella non è gestita da Lake Formation, la seconda chiamata dal motore di analisi viene effettuata direttamente ad Amazon S3. La policy relativa al bucket di Amazon S3 e la politica IAM utente vengono valutate per l'accesso ai dati.
Ogni volta che utilizzi IAM le policy, assicurati di seguire IAM le migliori pratiche. Per ulteriori informazioni, consulta le migliori pratiche di sicurezza IAM nella Guida IAM per l'utente.
Argomenti
