Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funziona la modalità di accesso ibrida
Il diagramma seguente mostra come funziona l'autorizzazione di Lake Formation in modalità di accesso ibrido quando si interrogano le risorse del Data Catalog.
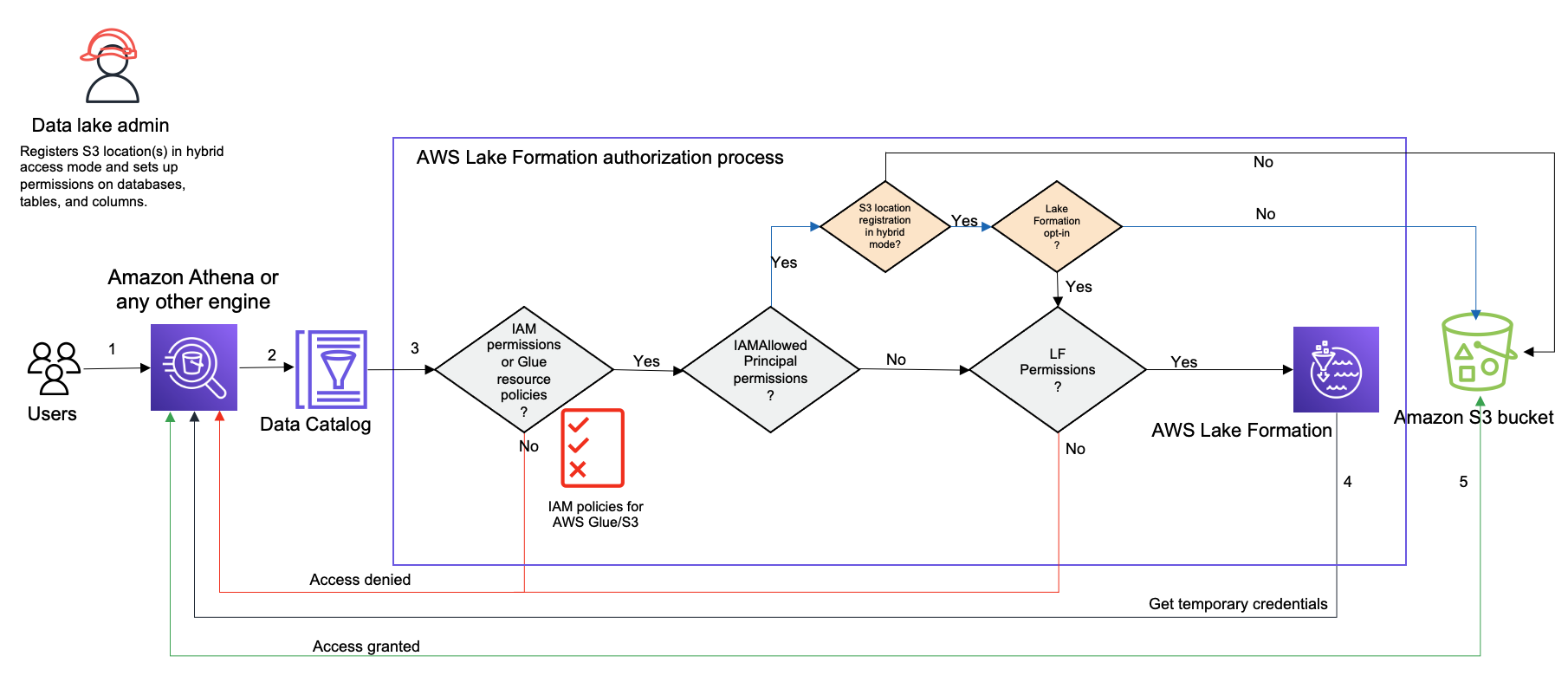
Prima di accedere ai dati nel data lake, un amministratore del data lake o un utente con autorizzazioni amministrative configura le politiche utente delle singole tabelle di Data Catalog per consentire o negare l'accesso alle tabelle del Data Catalog. Quindi, un principale che dispone delle autorizzazioni per eseguire l'RegisterResourceoperazione registra la posizione Amazon S3 della tabella con Lake Formation in modalità di accesso ibrido. L'amministratore concede le autorizzazioni di Lake Formation a utenti specifici sui database e sulle tabelle del Data Catalog e li autorizza a utilizzare le autorizzazioni Lake Formation per tali database e tabelle in modalità di accesso ibrido.
Invia una query: un principale invia una query o uno script ETL utilizzando un servizio integrato come Amazon Athena, Amazon EMR o AWS Glue Amazon Redshift Spectrum.
Richiede dati: il motore analitico integrato identifica la tabella richiesta e invia la richiesta di metadati al Data Catalog (,).
GetTableGetDatabase-
Verifica le autorizzazioni: il Data Catalog verifica le autorizzazioni di accesso del responsabile dell'interrogazione con Lake Formation.
-
Se alla tabella non sono allegate autorizzazioni di
IAMAllowedPrincipalsgruppo, vengono applicate le autorizzazioni di Lake Formation. -
Se il principale ha scelto di utilizzare le autorizzazioni di Lake Formation nella modalità di accesso ibrida e alla tabella sono allegate le autorizzazioni di
IAMAllowedPrincipalsgruppo, le autorizzazioni di Lake Formation vengono applicate. Il motore di query applica i filtri ricevuti da Lake Formation e restituisce i dati all'utente. -
Se la posizione della tabella non è registrata con Lake Formation e il principale non ha scelto di utilizzare le autorizzazioni di Lake Formation in modalità di accesso ibrido, il Data Catalog verifica se alla tabella sono associate autorizzazioni di
IAMAllowedPrincipalsgruppo. Se questa autorizzazione esiste nella tabella, tutti i principali dell'account ottengonoSuperiAllpermessi sulla tabella.
-
-
Ottieni credenziali: il Data Catalog controlla e fa sapere al motore se la posizione della tabella è registrata o meno con Lake Formation. Se i dati sottostanti sono registrati con Lake Formation, il motore analitico richiede a Lake Formation le credenziali temporanee per accedere ai dati nel bucket Amazon S3.
-
Ottieni dati: se il responsabile è autorizzato ad accedere ai dati della tabella, Lake Formation fornisce l'accesso temporaneo al motore analitico integrato. Utilizzando l'accesso temporaneo, il motore analitico recupera i dati da Amazon S3 ed esegue i filtri necessari come il filtraggio di colonne, righe o celle. Quando il motore termina l'esecuzione del lavoro, restituisce i risultati all'utente. Questo processo è denominato distribuzione di credenziali. Per ulteriori informazioni, vedereIntegrazione di servizi di terze parti con Lake Formation.
-
Se la posizione dei dati della tabella non è registrata con Lake Formation, la seconda chiamata dal motore di analisi viene effettuata direttamente ad Amazon S3. La policy del bucket Amazon S3 interessata e la politica utente IAM vengono valutate per l'accesso ai dati. Ogni volta che si utilizzano le policy IAM, assicurati di seguire le best practice IAM. Per ulteriori informazioni, consulta le best practice di sicurezza in IAM nella IAM User Guide.
