Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorneremo più. Per ulteriori informazioni, consulta la paginaCos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Classificazione binaria
L'output effettivo di molti algoritmi di classificazione binaria è un punteggio di previsione. Il punteggio indica la certezza del sistema che una data osservazione appartenga alla classe positiva. Per decidere se l'osservazione debba essere classificata come positiva o negativa, in quanto consumatore di questo punteggio, si interpreterà il punteggio scegliendo una soglia di classificazione (interruzione) e si confronterà il punteggio con tale soglia. Qualsiasi osservazione con punteggi superiori alla soglia viene quindi prevista come classe positiva mentre i punteggi inferiori alla soglia vengono previsti come classe negativa.
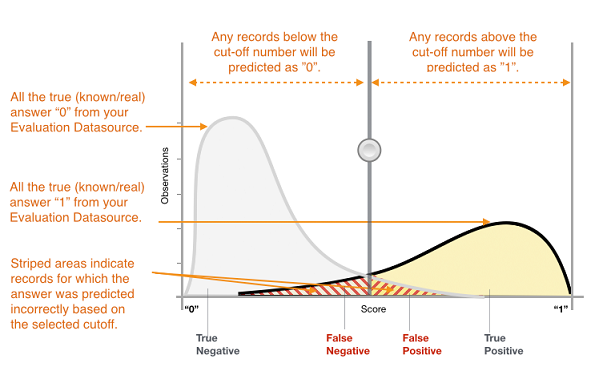
Figura 1: distribuzione dei punteggi per un modello di classificazione binaria
Le previsioni ora rientrano in quattro gruppi basati sulla risposta effettiva nota e sulla risposta prevista: previsioni positive esatte (true positive), previsioni negative esatte (true negative), previsioni positive errate (false positive) e previsioni negative errate (false negative).
Il parametro di accuratezza della classificazione binaria quantifica i due tipi di previsioni corrette e i due tipi di errori. I parametri più comuni sono accuratezza (ACC), precisione, recall, percentuale di falsi positivi, misura F1. Ogni parametro misura un aspetto diverso del modello predittivo. L'accuratezza (ACC) misura la percentuale di previsioni corrette. La precisione misura la percentuale di positivi effettivi tra gli esempi previsti come positivi. Il recall misura quanti positivi effettivi sono stati previsti come positivi. La misura F1 è la media armonica tra precisione e recall.
L'AUC è un tipo diverso di parametro. Misura la capacità del modello ML di prevedere un punteggio più elevato per gli esempi positivi rispetto agli esempi negativi. Poiché l'AUC è indipendente dalla soglia selezionata, è possibile farsi un'idea delle prestazioni in termini di previsioni del modello attraverso il parametro AUC, senza selezionare una soglia.
A seconda del problema aziendale, si potrebbe essere più interessati a un modello che esegua correttamente uno specifico sottoinsieme di questi parametri. Ad esempio, due applicazioni aziendali potrebbe avere requisiti molto diversi per i loro modelli ML:
Un'applicazione potrebbe essere molto sicura che le previsioni positive siano effettivamente positive (elevata precisione) e potersi permettere di classificare erroneamente alcuni esempi positivi come negativi (recall moderato).
Un'altra applicazione potrebbe dover prevedere correttamente tutti gli esempi positivi possibile (recall elevato) e accetterà l'errata classificazione di alcuni esempi negativi come positivi (precisione moderata).
In Amazon ML, le osservazioni ottengono un punteggio previsto nell'intervallo [0,1]. La soglia del punteggio per prendere la decisione di classificare gli esempi come 0 o 1 è impostata per impostazione predefinita su 0,5. Amazon ML consente di esaminare le implicazioni legate alla scelta di soglie di punteggio differenti e consente di scegliere una soglia adeguata in grado di soddisfare le esigenze aziendali.
