Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Informazioni sui dati
Amazon ML calcola statistiche descrittive sui dati di input che puoi utilizzare per comprenderli.
Statistiche descrittive
Amazon ML calcola le seguenti statistiche descrittive per diversi tipi di attributi:
Numerici:
-
Istogrammi di distribuzione
-
Numero di valori non validi
-
Valori minimo, mediano, medio e massimo
Binari e categorici:
-
Conteggio (di valori distinti per categoria)
-
Istogramma della distribuzione dei valori
-
Valori più frequenti
-
Conteggi dei valori univoci
-
Percentuale del valore "true" (solo binari)
-
Parole più importanti
-
Parole più frequenti
Testo:
-
Nome dell'attributo
-
Correlazione con il target (se il target è impostato)
-
Totale parole
-
Parole univoche
-
Intervallo del numero di parole in una riga
-
Intervallo di lunghezze delle parole
-
Parole più importanti
Accesso a Data Insights sulla console Amazon ML
Sulla console Amazon ML, puoi scegliere il nome o l'ID di qualsiasi origine dati per visualizzarne la pagina Data Insights. Questa pagina fornisce i parametri e le visualizzazioni che consentono di conoscere i dati di input associati all'origine dati, incluse le informazioni riportate di seguito:
-
Riepilogo dei dati
-
Distribuzioni di destinazione
-
Valori mancanti
-
Valori non validi
-
Statistiche di riepilogo delle variabili in base al tipo di dati
-
Distribuzioni delle variabili in base al tipo di dati
Le seguenti sezioni descrivono i parametri e le visualizzazioni nel dettaglio.
Riepilogo dei dati
Il report di riepilogo dei dati di un'origine dati visualizza le informazioni di riepilogo, tra cui ID dell'origine dati, nome, dove è stata completata, stato attuale, attributo di destinazione, informazioni sui dati di input (posizione del bucket S3, formato dei dati, numero di record elaborati e numero di record danneggiata riscontrati durante l'elaborazione) e numero di variabili in base al tipo di dati.
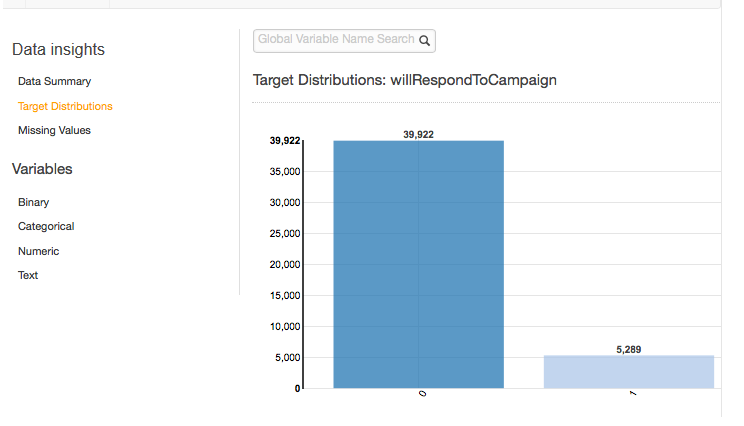
Distribuzioni di destinazione
Il report delle distribuzioni di destinazione mostra la distribuzione dell'attributo target dell'origine dati. Nell'esempio seguente, ci sono 39.922 osservazioni in cui l'attributo will RespondToCampaign target è uguale a 0. Questo è il numero di clienti che non hanno risposto alla campagna e-mail. Ci sono 5.289 osservazioni in cui will è uguale a 1. RespondToCampaign Questo è il numero di clienti che hanno risposto alla campagna e-mail.
Valori mancanti
Il report dei valori mancanti elenca gli attributi dei dati di input per i quali mancano i valori. Solo gli attributi con tipi di dati numerici possono avere valori mancanti. Poiché i valori mancanti possono influenzare la qualità dell'addestramento di un modello ML, è consigliabile fornire i valori mancanti, se possibile.
Durante l'addestramento del modello ML, se manca l'attributo target, Amazon ML rifiuta il record corrispondente. Se l'attributo target è presente nel record, ma manca un valore per un altro attributo numerico, Amazon ML trascura il valore mancante. In questo caso, Amazon ML crea un attributo sostitutivo e lo imposta su 1 per indicare che questo attributo è mancante. Ciò consente ad Amazon ML di apprendere modelli dalla presenza di valori mancanti.
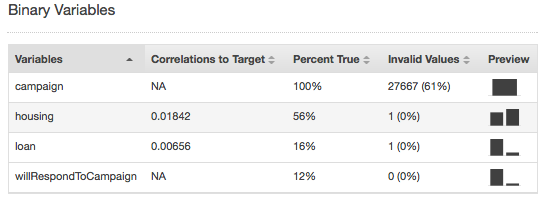
Valori non validi
I valori non validi possono verificarsi solo con tipi di dati numerici e binari. Si possono trovare i valori non validi visualizzando le statistiche di riepilogo delle variabili nei report dei tipi di dati. Negli esempi seguenti vi è un solo valore non valido nell'attributo di durata Numeric e due valori non validi nel tipo di dati Binary (uno nell'attributo housing e uno nell'attributo loan).

Variable-Target Correlazione
Dopo aver creato un'origine dati, Amazon ML può valutare l'origine dati e identificare la correlazione, o impatto, tra le variabili e l'obiettivo. Ad esempio, il prezzo di un prodotto potrebbe avere un notevole impatto sulle vendite, mentre le dimensioni del prodotto potrebbero avere scarsa valenza predittiva.
In generale, è consigliabile includere quante più variabili possibile nei dati di addestramento. Tuttavia, il disturbo introdotto dall'inclusione di molte variabili con scarsa capacità predittiva potrebbe influire negativamente sulla qualità e l'accuratezza del modello ML.
È possibile migliorare le prestazioni predittive del modello rimuovendo le variabili che hanno scarso impatto durante l'addestramento del modello. Puoi definire quali variabili sono rese disponibili per il processo di apprendimento automatico in una ricetta, che è un meccanismo di trasformazione di Amazon ML. Per ulteriori informazioni sulle composizioni, consultare Trasformazioni dei dati per il Machine Learning.
Statistiche di riepilogo degli attributi in base al tipo di dati
Nel report delle informazioni sui dati, è possibile visualizzare gli attributi nelle statistiche di riepilogo per i seguenti tipi di dati:
-
Binario
-
Categoriale
-
Numerico
-
Testo
Le statistiche di riepilogo in base al tipo di dati Binary (binari) mostrano tutti gli attributi binari. La colonna Correlations to target (Correlazioni con il target) mostra le informazioni condivise tra la colonna di destinazione e la colonna degli attributi. La colonna Percent true (Percentuale true) mostra la percentuale di osservazioni che hanno il valore 1. La colonna Invalid values (Valori non validi) mostra il numero di valori non validi, nonché la percentuale di valori non validi per ogni attributo. La colonna Preview (Anteprima) fornisce un collegamento a una distribuzione grafica di ogni attributo.
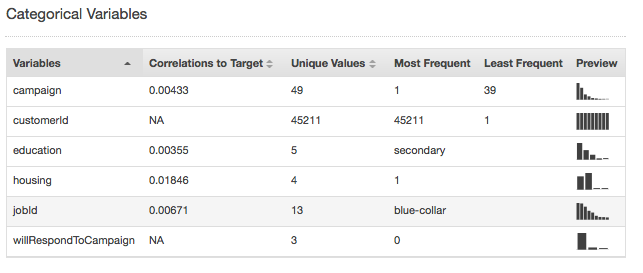
Le statistiche di riepilogo per il tipo di dati Categorical (categorici) mostrano tutti gli attributi di categoria con il numero di valori univoci, il valore più frequente e il valore meno frequente. La colonna Preview (Anteprima) fornisce un collegamento a una distribuzione grafica di ogni attributo.
Le statistiche di riepilogo per il tipo di dati Numeric (numerici) mostrano tutti gli attributi numerici con il numero di valori mancanti, valori non validi, intervallo di valori, media e valori mediani. La colonna Preview (Anteprima) fornisce un collegamento a una distribuzione grafica di ogni attributo.
Le statistiche di riepilogo per il tipo di dati Text (testo) mostrano tutti gli attributi di testo, il numero totale di parole in tale attributo, il numero di parole univoche in tale attributo, la gamma di parole in un attributo, la gamma di lunghezze delle parole e le parole più importanti. La colonna Preview (Anteprima) fornisce un collegamento a una distribuzione grafica di ogni attributo.
L'esempio seguente mostra le statistiche relative al tipo di dati Text (testo) per una variabile di testo denominata review (revisione), con quattro record.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
Le colonne di questo esempio mostrerebbero le seguenti informazioni.
-
La colonna Attributes (Attributi) mostra il nome della variabile. In questo esempio, la colonna direbbe "review".
-
La colonna Correlations to target (Correlazioni con il target) esiste solo se è specificato un target. La correlazione misura la quantità di informazioni che questo attributo fornisce riguardo al target. Più è elevata la correlazione, maggiori sono le informazioni che l'attributo fornisce sul target. La correlazione si misura in termini di informazione reciproca tra una rappresentazione semplificata dell'attributo di testo e l target.
-
La colonna Total words (Totale parole) mostra il numero di parole generate dalla tokenizzazione di ogni record, delimitando le parole con uno spazio vuoto. In questo esempio, la colonna direbbe "12".
-
La colonna Unique words (Parole univoche) mostra il numero di parole univoche per un attributo. In questo esempio, la colonna direbbe "10".
-
La colonna Words in attribute (range) (Parole nell'attributo (intervallo)) mostra il numero di parole in una singola riga nell'attributo. In questo esempio, la colonna direbbe "0-6".
-
La colonna Word length (range) (Lunghezza parole (intervallo)) mostra l'intervallo del numero di caratteri che si trovano nelle parole. In questo esempio, la colonna direbbe "2-11".
-
La colonna Most prominent words (Parole più importanti) mostra una graduatoria delle parole che appaiono nell'attributo. Se è presente un attributo di destinazione, le parole sono classificate in base alla loro correlazione con il target, il che significa che le parole che hanno la massima correlazione appaiono per prime nell'elenco. Se non è presente una destinazione nei dati, le parole sono classificati in base alla loro entropia.
Comprendere la distribuzione degli attributi Categorical e Binary
Facendo clic sul collegamento Preview (Anteprima) associato a un attributo categorico o binario, è possibile visualizzare la distribuzione dell'attributo e i dati di esempio del file di input per ogni valore categorico dell'attributo.
Ad esempio, la seguente screenshot mostra la distribuzione per l'attributo categorico jobId. La distribuzione visualizza i primi 10 valori categorici, con tutti gli altri valori raggruppati come "others" (altri). Classifica ciascuno dei primi 10 valori categorici con il numero di osservazioni nel file di input che contengono tale valore, nonché con un link per visualizzare le osservazioni di esempio dal file dei dati di input.
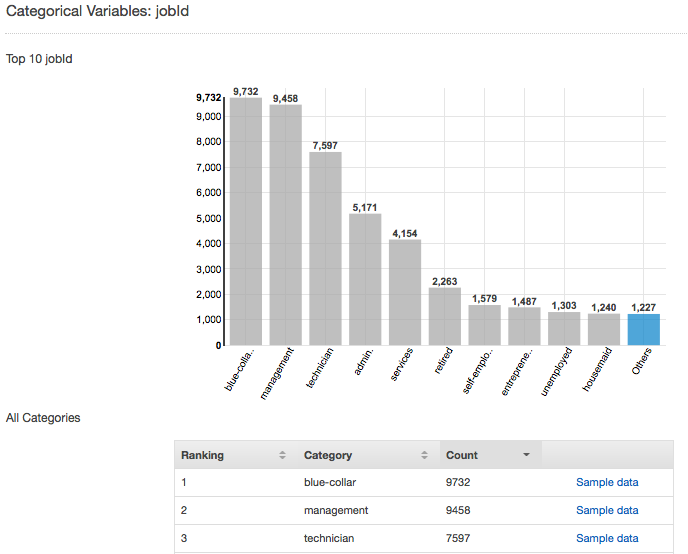
Comprendere la distribuzione degli attributi Numeric
Per visualizzare la distribuzione di un attributo numerico, fare clic sul collegamento Preview (Anteprima) dell'attributo. Quando si visualizza la distribuzione di un attributo numerico, è possibile scegliere bin con dimensioni 500, 200, 100, 50 o 20. Più grande è il bin, minore è il numero di barre del grafico che saranno visualizzate. Inoltre, la risoluzione della distribuzione sarà più grossolana con bin di grandi dimensioni. Al contrario, se si impostano le dimensioni del bucket a 20, aumenta la risoluzione della distribuzione visualizzata.
I valori minimo, medio e massimo vengono anche visualizzati, come mostrato nella screenshot seguente.
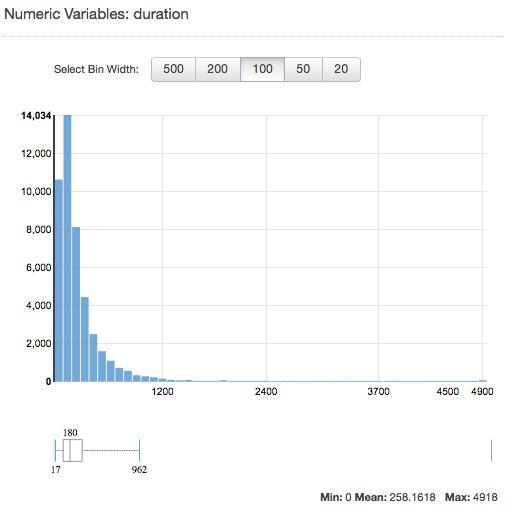
Comprendere la distribuzione degli attributi Text
Per visualizzare la distribuzione di un attributo di testo, fare clic sul collegamento Preview (Anteprima) dell'attributo. Quando si visualizza la distribuzione di un attributo di testo, si possono vedere le seguenti informazioni.
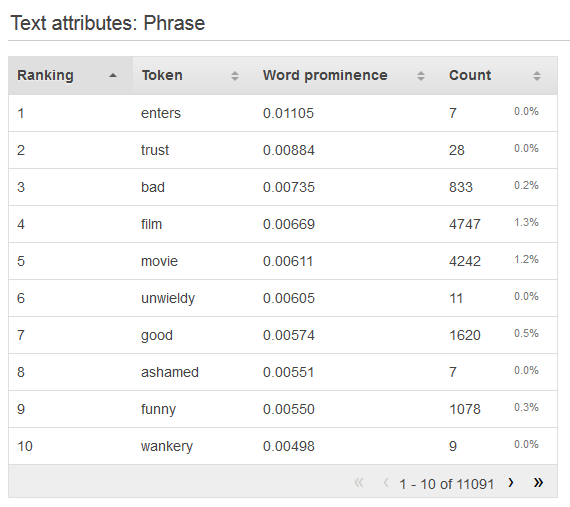
- Ranking (classificazione)
-
I token di testo sono classificati in base alla quantità di informazioni che forniscono, dai più informativi ai meno informativi.
- Token
-
Il token mostra la parola del testo di input oggetto della riga di statistiche.
- Word prominence (Importanza delle parole)
-
Se è presente un attributo di destinazione, le parole sono classificate in base alla loro correlazione con il target, pertanto le parole che hanno la massima correlazione appaiono per prime nell'elenco. Se nei dati non è presente un target, le parole sono classificate in base alla loro entropia, ossia alla quantità di informazioni che riescono a comunicare.
- Count number (Numero conteggio)
-
Il numero conteggio mostra il numero di record di input in cui è apparso il token.
- Count percentage (Percentuale conteggio)
-
La percentuale conteggio mostra la percentuale di righe di dati di input in cui è apparso il token.
