Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Informazioni sul modello di regressione
Interpretazione delle previsioni
L'output di un modello ML di regressione è un valore numerico per la previsione del target da parte del modello. Ad esempio, se si stanno prevedendo i prezzi delle case, la previsione del modello potrebbe essere un valore come 254.013.
Nota
La gamma di previsioni può differire dalla gamma del target nei dati di addestramento. Ad esempio, supponiamo che si stiano prevedendo i prezzi delle case e che il target nei dati di addestramento abbia valori in un intervallo da 0 a 450.000. Il target previsto non deve essere necessariamente nello stesso intervallo e potrebbe assumere qualsiasi valore positivo (superiore a 450.000) o negativo (meno di zero). È importante pianificare cosa fare in presenza di valori di previsione esterni a un determinato intervallo accettabile per l'applicazione.
Misurazione dell'accuratezza del modello ML
Per le attività di regressione, Amazon ML utilizza il parametro standard di settore dell'errore quadratico medio (RMSE). Misura la distanza tra il target numerico previsto e la risposta numerica effettiva (dati acquisiti sul campo). Minore è il valore del RMSE, migliore è l'accuratezza predittiva del modello. Un modello con previsioni perfettamente corrette avrebbe un RMSE di 0. L'esempio seguente mostra dati di valutazione che contengono N record:

Riferimento RMSE
Amazon ML fornisce un parametro di riferimento per i modelli di regressione. È l'RMSE per un modello di regressione ipotetico che sarebbe sempre in grado di prevedere la media del target come risposta. Ad esempio, se si dovesse prevedere l'età dell'acquirente di una casa e l'età media per le osservazioni nei dati di addestramento è 35, il modello di base sarebbe sempre in grado di prevedere la risposta come 35. È possibile confrontare il modello ML con questo riferimento, per convalidare se il modello ML sia meglio di un modello ML che prevede questa risposta costante.
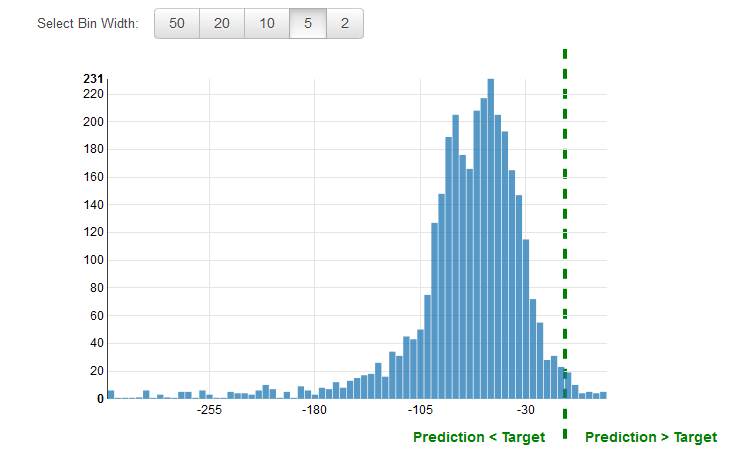
Utilizzo della Performance Visualization
È prassi comune esaminare i residui per cercare problemi di regressione. Un residuo di un'osservazione nei dati di valutazione è la differenza tra il target reale e il target previsto. I residui rappresentano quella parte del target che il modello non è in grado di prevedere. Un residuo positivo indica che il modello sta sottovalutando il target (il target effettivo è più grande del target previsto). Un residuo negativo indica una sopravvalutazione (il target effettivo è più piccolo del target previsto). L'istogramma dei residui relativi ai dati di valutazione, ove distribuito con una forma a campana e centrato sullo zero, indica che il modello compie errori in modo aleatorio e non sovra-prevede o sotto-prevede sistematicamente una determinata gamma di valori target. Se i residui non assumono una forma a campana centrata sullo zero, è presente una struttura nell'errore di previsione del modello. L'aggiunta di ulteriori variabili al modello potrebbero aiutarlo ad acquisire il pattern che non viene acquisito dal modello attuale. La figura seguente mostra i residui che non sono centrati intorno allo zero.