Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprendere il formato dei dati per Amazon ML
I dati di input sono i dati che è possibile utilizzare per creare un'origine dati. È necessario salvare i dati di input nel formato .csv (valori separati da virgola). Ogni riga del file .csv è un singolo record di dati o un'osservazione. Ogni colonna del file .csv contiene un attributo dell'osservazione. Ad esempio, la figura riportata di seguito mostra i contenuti di un file .csv che dispone di quattro osservazioni, ciascuna nella propria riga. Ogni osservazione contiene otto attributi, separati da una virgola. Gli attributi rappresentano le seguenti informazioni su ogni individuo rappresentato da un'osservazione: customerId,jobId,education,housing,loan,campaign,duration,willRespondToCampaign.

Attributes
Amazon ML richiede i nomi per ogni attributo. È possibile specificare i nomi degli attributi:
-
Includendo i nomi degli attributi nella prima riga (nota anche come riga di intestazione) del file .csv utilizzato per i dati di input
-
Includendo i nomi degli attributi in uno schema separato che si trova nello stesso bucket S3 dei dati di input
Per ulteriori informazioni sull'utilizzo dei file dello schema, consultare la pagina relativa alla creazione di uno schema di dati.
L'esempio seguente di un file .csv include i nomi degli attributi nella riga di intestazione.
customerId,jobId,education,housing,loan,campaign,duration,willRespondToCampaign 1,3,basic.4y,no,no,1,261,0 2,1,high.school,no,no,22,149,0 3,1,high.school,yes,no,65,226,1 4,2,basic.6y,no,no,1,151,0
Requisiti relativi al formato dei file di input
Il file.csv che contiene i dati di input deve soddisfare i seguenti requisiti:
-
Deve essere in testo normale che utilizza un set di caratteri come ASCII, Unicode o EBCDIC.
-
Essere costituito da osservazioni, una sola osservazione per riga.
-
Per ogni osservazione, i valori degli attributi devono essere separati da virgole.
-
Se il valore di un attributo contiene una virgola (delimitatore), l'intero valore di attributo deve essere racchiuso tra virgolette doppie.
-
Ogni osservazione deve terminare con un carattere di fine riga, ossia un carattere speciale o una sequenza di caratteri che indica la fine di una riga.
-
I valori degli attributi non possono includere caratteri di fine riga, anche se il valore dell'attributo è racchiuso tra virgolette doppie.
-
Ogni osservazione deve avere lo stesso numero di attributi e la stessa sequenza di attributi.
-
Ogni osservazione non deve avere dimensioni superiori a 100 KB. Amazon ML rifiuta qualsiasi osservazione di dimensioni superiori a 100 KB durante l'elaborazione. Se Amazon ML rifiuta più di 10.000 osservazioni, rifiuta l'intero file .csv.
Utilizzo di più file come input di dati per Amazon ML
È possibile fornire il proprio input ad Amazon ML come un singolo file oppure come una raccolta di file. Le raccolte devono soddisfare queste condizioni:
-
Tutti i file devono avere lo stesso schema di dati.
-
Tutti i file devono risiedere nello stesso prefisso Amazon Simple Storage Service (Amazon S3) e il percorso indicato per la raccolta deve terminare con una barra (/).
Ad esempio, se i file di dati vengono denominati input1.csv, input2.csv e input3.csv e il nome del bucket S3 è s3://examplebucket, i percorsi dei file potrebbero avere questo aspetto:
s3://examplebucket/path/to/data/input1.csv
s3://examplebucket/path/to/data/input2.csv
s3://examplebucket/path/to/data/input3.csv
È possibile fornire la seguente posizione S3 come input per Amazon ML:
's3://examplebucket/path/to/data/'
Caratteri di fine riga nel formato CSV
Quando si crea il proprio file .csv, ogni osservazione terminerà con un carattere speciale di fine riga. Questo carattere non è visibile, ma è incluso automaticamente alla fine di ogni osservazione premendo il tasto Invio o Ritorno a capo. I caratteri speciali che rappresentano la fine della riga variano a seconda del sistema operativo in uso. I sistemi Unix, come ad esempio Linux o OS X, utilizzano un carattere di avanzamento riga indicato da "\n" (codice ASCII decimale 10 o esadecimale 0x0a). Microsoft Windows utilizza due caratteri chiamati ritorno a capo e avanzamento riga che vengono indicati da"\r\n" (codici ASCII decimali 13 e 10 o esadecimali 0x0d e 0x0a).
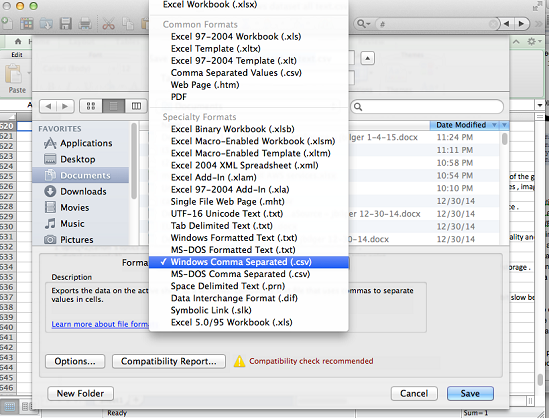
Se si desidera utilizzare OS X e Microsoft Excel per creare il proprio file .csv, eseguire la procedura seguente. Assicurarsi di scegliere il formato corretto.
Salvare un file .csv se si utilizza OS X ed Excel
-
Quando si salva il file .csv, scegliere Format (Formato) e Windows Comma Separated (.csv).
-
Scegli Salva.
Importante
Non salvare il file.csv utilizzando il fileValori separati da virgola (.csv)oSeparato da virgola MS-DOS (.csv)formati perché Amazon ML non è in grado di leggerli.
