Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di immagini di algoritmi
Un algoritmo di SageMaker intelligenza artificiale di Amazon richiede che l'acquirente utilizzi i propri dati da addestrare prima di formulare previsioni. In qualità di Marketplace AWS venditore, puoi utilizzare l' SageMaker intelligenza artificiale per creare algoritmi e modelli di machine learning (ML) utilizzabili dai tuoi acquirenti. AWS Nelle sezioni seguenti viene illustrato come creare immagini di algoritmi per. Marketplace AWS Ciò include la creazione dell'immagine di addestramento Docker per addestrare l'algoritmo e dell'immagine di inferenza che contiene la logica di inferenza. Per la pubblicazione di un prodotto algoritmico sono necessarie sia le immagini di addestramento che quelle di inferenza.
Argomenti
Panoramica
Un algoritmo include i seguenti componenti:
-
Un'immagine di formazione archiviata in Amazon ECR
-
Un'immagine di inferenza memorizzata in Amazon Elastic Container Registry (Amazon ECR)
Nota
Per i prodotti algoritmici, il contenitore di addestramento genera artefatti del modello che vengono caricati nel contenitore di inferenza durante la distribuzione del modello.
Il diagramma seguente mostra il flusso di lavoro per la pubblicazione e l'utilizzo di prodotti algoritmici.
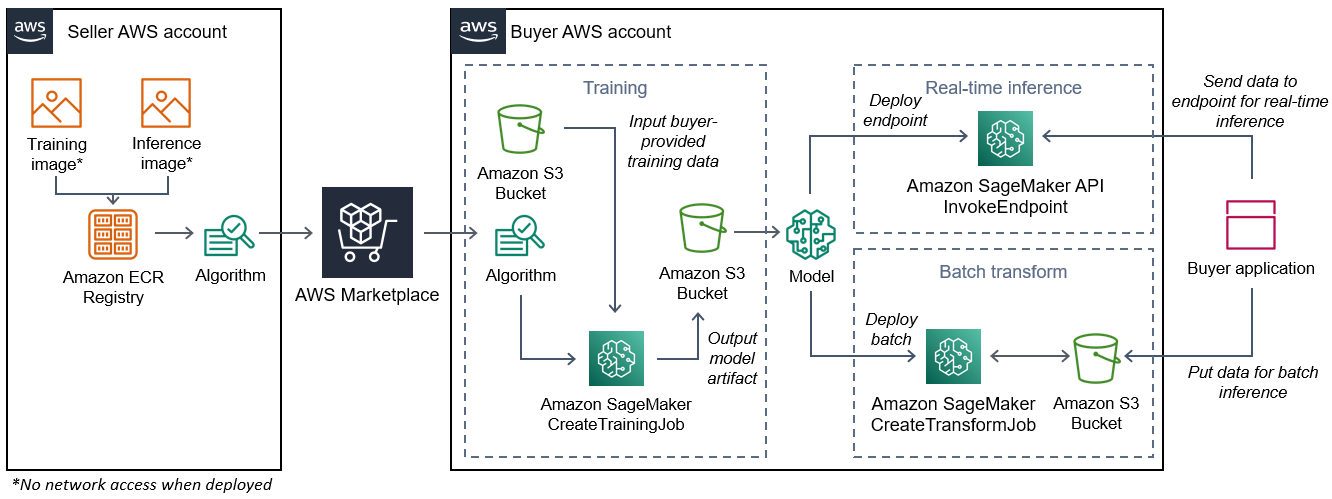
Il flusso di lavoro per la creazione di un algoritmo di SageMaker intelligenza artificiale per Marketplace AWS include i seguenti passaggi:
-
Il venditore crea un'immagine di formazione e un'immagine di inferenza (nessun accesso alla rete quando viene implementata) e la carica nel registro Amazon ECR.
-
Il venditore crea quindi una risorsa algoritmica in Amazon SageMaker AI e pubblica il suo prodotto ML su Marketplace AWS.
-
L'acquirente si abbona al prodotto ML.
-
L'acquirente crea un lavoro di formazione con un set di dati compatibile e valori iperparametrici appropriati. SageMaker L'intelligenza artificiale esegue l'immagine di allenamento e carica i dati di allenamento e gli iperparametri nel contenitore di formazione. Al termine del processo di formazione, gli elementi del modello presenti
/opt/ml/model/vengono compressi e copiati nel bucket Amazon S3 dell'acquirente. -
L'acquirente crea un pacchetto modello con gli elementi del modello tratti dal training archiviato in Amazon S3 e distribuisce il modello.
-
SageMaker L'intelligenza artificiale esegue l'immagine di inferenza, estrae gli artefatti del modello compressi e carica i file nel percorso della directory del contenitore di inferenza,
/opt/ml/model/dove vengono utilizzati dal codice che serve l'inferenza. -
Indipendentemente dal fatto che il modello venga implementato come endpoint o come processo di trasformazione in batch, l' SageMaker IA trasmette i dati per l'inferenza per conto dell'acquirente al contenitore tramite l'endpoint HTTP del contenitore e restituisce i risultati della previsione.
Creazione di un'immagine di addestramento per algoritmi
Questa sezione fornisce una procedura dettagliata per impacchettare il codice di allenamento in un'immagine di allenamento. È necessaria un'immagine di addestramento per creare un prodotto algoritmico.
Un'immagine di allenamento è un'immagine Docker contenente l'algoritmo di allenamento. Il contenitore aderisce a una struttura di file specifica per consentire all' SageMaker IA di copiare i dati da e verso il contenitore.
Per la pubblicazione di un prodotto algoritmico sono necessarie sia le immagini di addestramento che quelle di inferenza. Dopo aver creato l'immagine di allenamento, è necessario creare un'immagine di inferenza. Le due immagini possono essere combinate in un'unica immagine o rimanere come immagini separate. Sta a te decidere se combinare le immagini o separarle. In genere, l'inferenza è più semplice dell'addestramento e potresti aver bisogno di immagini separate per migliorare le prestazioni di inferenza.
Nota
Quello che segue è solo un esempio di codice di imballaggio per un'immagine di addestramento. Per ulteriori informazioni, consulta Utilizzare algoritmi e modelli personalizzati con e gli Marketplace AWS esempi di Marketplace AWS
SageMaker intelligenza artificiale
Fasi
Fase 1: Creazione dell'immagine del contenitore
Affinché l'immagine di addestramento sia compatibile con Amazon SageMaker AI, deve aderire a una struttura di file specifica per consentire all' SageMaker IA di copiare i dati di addestramento e gli input di configurazione su percorsi specifici del contenitore. Al termine della formazione, gli artefatti del modello generati vengono archiviati in un percorso di directory specifico nel contenitore da cui l'IA esegue le copie. SageMaker
Quanto segue utilizza la CLI Docker installata in un ambiente di sviluppo su una distribuzione Ubuntu di Linux.
Prepara il tuo programma per leggere gli input di configurazione
Se il programma di formazione richiede input di configurazione forniti dall'acquirente, questi dati vengono copiati di seguito all'interno del container quando vengono eseguiti. Se necessario, il programma deve leggere questi percorsi di file specifici.
-
/opt/ml/input/configè la directory che contiene le informazioni che controllano l'esecuzione del programma.-
hyperparameters.jsonè un dizionario in formato JSON di nomi e valori di iperparametri. I valori sono stringhe, quindi potrebbe essere necessario convertirli. -
resourceConfig.jsonè un file in formato JSON che descrive il layout di rete utilizzato per l'addestramento distribuito. Se l'immagine di allenamento non supporta la formazione distribuita, è possibile ignorare questo file.
-
Nota
Per ulteriori informazioni sugli input di configurazione, consulta How Amazon SageMaker AI Provides Training Information.
Prepara il programma per leggere gli input di dati
I dati di addestramento possono essere passati al contenitore in una delle due modalità seguenti. Il programma di allenamento eseguito nel contenitore digerisce i dati di allenamento in una di queste due modalità.
Modalità file
-
/opt/ml/input/data/<channel_name>/contiene i dati di input per quel canale. I canali vengono creati in base alla chiamata all'CreateTrainingJoboperazione, ma è generalmente importante che i canali corrispondano a quanto previsto dall'algoritmo. I file per ogni canale vengono copiati da AmazonS3 in questa directory, preservando la struttura ad albero indicata dalla struttura chiave di Amazon S3.
modalità Pipe
-
/opt/ml/input/data/<channel_name>_<epoch_number>è la pipa per una determinata epoca. Le epoche iniziano da zero e aumentano di una volta ogni volta che le leggi. Non c'è limite al numero di epoche che puoi percorrere, ma devi chiudere ogni pipa prima di leggere l'epoca successiva.
Prepara il tuo programma per scrivere risultati di formazione
L'output del corso di formazione viene scritto nelle seguenti directory di contenitori:
-
/opt/ml/model/è la directory in cui si scrive il modello o gli artefatti del modello generati dall'algoritmo di addestramento. Il modello può essere in qualsiasi formato desiderato. Può essere un singolo file o un intero albero di directory. SageMaker AI impacchetta tutti i file in questa directory in un file compresso (.tar.gz). Questo file è disponibile nella posizione Amazon S3 restituita dall'operazioneDescribeTrainingJobAPI. -
/opt/ml/output/è una directory in cui l'algoritmo può scrivere unfailurefile che descrive il motivo per cui il processo non è riuscito. Il contenuto di questo file viene restituito nelFailureReasoncampo delDescribeTrainingJobrisultato. Per i lavori che hanno esito positivo, non c'è motivo di scrivere questo file perché viene ignorato.
Crea lo script per l'esecuzione del contenitore
Crea uno script di train shell che SageMaker AI esegue quando esegue l'immagine del contenitore Docker. Una volta completato l'addestramento e gli artefatti del modello vengono scritti nelle rispettive directory, uscite dallo script.
./train
#!/bin/bash # Run your training program here # # # #
Creazione del Dockerfile
Crea un file Dockerfile nel tuo contesto di compilazione. Questo esempio usa Ubuntu 18.04 come immagine di base, ma puoi iniziare da qualsiasi immagine di base che funzioni per il tuo framework.
./Dockerfile
FROM ubuntu:18.04 # Add training dependencies and programs # # # # # # Add a script that SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /train /opt/program/train RUN chmod 755 /opt/program/train ENV PATH=/opt/program:${PATH}
DockerfileAggiunge lo train script creato in precedenza all'immagine. La directory dello script viene aggiunta a PATH in modo che possa essere eseguita durante l'esecuzione del contenitore.
Nell'esempio precedente, non esiste una logica di addestramento effettiva. Per creare l'immagine effettiva dell'allenamento, aggiungete le dipendenze di allenamento a e aggiungete la logica per leggere gli input di allenamento per addestrare e generare gli artefatti del modello. Dockerfile
L'immagine di allenamento deve contenere tutte le dipendenze richieste perché non avrà accesso a Internet.
Per ulteriori informazioni, consulta Utilizzare algoritmi e modelli personalizzati con e gli Marketplace AWS esempi di Marketplace AWS
SageMaker intelligenza artificiale
Fase 2: Creazione e test dell'immagine a livello locale
Nel contesto della compilazione, ora esistono i seguenti file:
-
./Dockerfile -
./train -
Le tue dipendenze e la tua logica di allenamento
Successivamente puoi creare, eseguire e testare questa immagine del contenitore.
Costruisci l'immagine
Esegui il comando Docker nel contesto di compilazione per creare e taggare l'immagine. Questo esempio utilizza il tagmy-training-image.
sudo docker build --tag my-training-image ./
Dopo aver eseguito questo comando Docker per creare l'immagine, dovresti vedere l'output mentre Docker crea l'immagine in base a ciascuna riga del tuo. Dockerfile Al termine, dovresti vedere qualcosa di simile al seguente.
Successfully built abcdef123456
Successfully tagged my-training-image:latestEsecuzione di in locale
Al termine, prova l'immagine localmente come mostrato nell'esempio seguente.
sudo docker run \ --rm \ --volume '<path_to_input>:/opt/ml/input:ro' \ --volume '<path_to_model>:/opt/ml/model' \ --volume '<path_to_output>:/opt/ml/output' \ --name my-training-container \ my-training-image \ train
Di seguito sono riportati i dettagli del comando:
-
--rm— Rimuove automaticamente il contenitore dopo l'arresto. -
--volume '<path_to_input>:/opt/ml/input:ro'— Rendi la directory di input di test disponibile per il contenitore in modalità di sola lettura. -
--volume '<path_to_model>:/opt/ml/model'— Bind monta il percorso in cui gli artefatti del modello vengono archiviati sulla macchina host al termine del test di addestramento. -
--volume '<path_to_output>:/opt/ml/output'— Bind mount il percorso in cui viene scritto il motivo dell'errore in unfailurefile sul computer host. -
--name my-training-container— Assegna un nome a questo contenitore funzionante. -
my-training-image— Esegui l'immagine creata. -
train— Esegui lo stesso script che SageMaker AI esegue durante l'esecuzione del contenitore.
Dopo aver eseguito questo comando, Docker crea un contenitore dall'immagine di training creata e lo esegue. Il contenitore esegue lo train script, che avvia il programma di allenamento.
Una volta terminato il programma di allenamento e chiuso il contenitore, verificate che gli artefatti del modello di output siano corretti. Inoltre, controllate gli output dei log per confermare che non producano log indesiderati, assicurandovi al contempo che vengano fornite informazioni sufficienti sul processo di formazione.
Questo completa l'imballaggio del codice di addestramento per un prodotto algoritmico. Poiché un prodotto algoritmico include anche un'immagine di inferenza, passa alla sezione successiva,. Creazione di un'immagine di inferenza per algoritmi
Creazione di un'immagine di inferenza per algoritmi
Questa sezione fornisce una procedura dettagliata per impacchettare il codice di inferenza in un'immagine di inferenza per il prodotto dell'algoritmo.
L'immagine di inferenza è un'immagine Docker contenente la logica di inferenza. Il contenitore in fase di esecuzione espone gli endpoint HTTP per consentire all' SageMaker IA di trasferire dati da e verso il contenitore.
Per la pubblicazione di un prodotto algoritmico sono necessarie sia le immagini di addestramento che quelle di inferenza. Se non l'hai ancora fatto, consulta la sezione precedente suCreazione di un'immagine di addestramento per algoritmi. Le due immagini possono essere combinate in un'unica immagine o rimanere come immagini separate. Sta a te decidere se combinare le immagini o separarle. In genere, l'inferenza è più semplice dell'addestramento e potresti aver bisogno di immagini separate per migliorare le prestazioni di inferenza.
Nota
Quello che segue è solo un esempio di codice di imballaggio per un'immagine di inferenza. Per ulteriori informazioni, consulta Utilizzare algoritmi e modelli personalizzati con e gli Marketplace AWS esempi di Marketplace AWS
SageMaker intelligenza artificiale
L'esempio seguente utilizza un servizio web, Flask
Fasi
Passaggio 1: creazione dell'immagine di inferenza
Affinché l'immagine di inferenza sia compatibile con l' SageMaker intelligenza artificiale, l'immagine Docker deve esporre gli endpoint HTTP. Mentre il container è in esecuzione, l'SageMaker intelligenza artificiale trasmette gli input per l'inferenza forniti dall'acquirente all'endpoint HTTP del contenitore. Il risultato dell'inferenza viene restituito nel corpo della risposta HTTP.
Quanto segue utilizza la CLI Docker installata in un ambiente di sviluppo su una distribuzione Ubuntu di Linux.
Crea lo script del server web
Questo esempio utilizza un server Python chiamato Flask
Nota
Flask
Crea lo script del server web Flask che serve i due endpoint HTTP sulla porta TCP 8080 utilizzata da AI. SageMaker I seguenti sono i due endpoint previsti:
-
/ping— SageMaker L'IA invia richieste HTTP GET a questo endpoint per verificare se il contenitore è pronto. Quando il contenitore è pronto, risponde alle richieste HTTP GET su questo endpoint con un codice di risposta HTTP 200. -
/invocations— SageMaker L'IA invia richieste HTTP POST a questo endpoint a scopo di inferenza. I dati di input per l'inferenza vengono inviati nel corpo della richiesta. Il tipo di contenuto specificato dall'utente viene passato nell'intestazione HTTP. Il corpo della risposta è l'output dell'inferenza.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code here. # # # # # # Add your inference code here. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
Nell'esempio precedente, non esiste una logica di inferenza effettiva. Per l'immagine di inferenza effettiva, aggiungi la logica di inferenza nell'app Web in modo che elabori l'input e restituisca la previsione.
L'immagine di inferenza deve contenere tutte le dipendenze richieste perché non avrà accesso a Internet.
Crea lo script per l'esecuzione del contenitore
Crea uno script denominato serve che l' SageMaker IA esegua quando esegue l'immagine del contenitore Docker. In questo script, avvia il server web HTTP.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker AI flask run --host 0.0.0.0 --port 8080
Creazione del Dockerfile
Crea un Dockerfile nel tuo contesto di compilazione. Questo esempio utilizza Ubuntu 18.04, ma puoi iniziare da qualsiasi immagine di base che funzioni per il tuo framework.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
DockerfileAggiunge i due script creati in precedenza all'immagine. La directory dello serve script viene aggiunta al PATH in modo che possa essere eseguita durante l'esecuzione del contenitore.
Preparazione del programma per caricare dinamicamente gli artefatti del modello
Per quanto riguarda i prodotti basati su algoritmi, l'acquirente utilizza i propri set di dati con l'immagine di addestramento per generare artefatti modello unici. Al termine del processo di formazione, il contenitore di formazione invia gli artefatti del modello nella directory del contenitore.
/opt/ml/model/ SageMaker L'intelligenza artificiale comprime il contenuto di quella directory in un file.tar.gz e lo archivia nell'archivio dell'acquirente in Amazon S3. Account AWS
Quando il modello viene distribuito, l' SageMaker intelligenza artificiale esegue l'immagine di inferenza, estrae gli artefatti del modello dal file.tar.gz archiviato nell'account dell'acquirente in Amazon S3 e li carica nel contenitore di inferenza nella directory. /opt/ml/model/ In fase di esecuzione, il codice del contenitore di inferenza utilizza i dati del modello.
Nota
Per proteggere qualsiasi proprietà intellettuale che potrebbe essere contenuta nei file degli artefatti del modello, potete scegliere di crittografare i file prima di emetterli. Per ulteriori informazioni, consulta Sicurezza e proprietà intellettuale con Amazon SageMaker AI.
Fase 2: Creazione e test dell'immagine a livello locale
Nel contesto della compilazione, ora esistono i seguenti file:
-
./Dockerfile -
./web_app_serve.py -
./serve
Successivamente puoi creare, eseguire e testare questa immagine del contenitore.
Costruisci l'immagine
Esegui il comando Docker per creare e taggare l'immagine. Questo esempio utilizza il tagmy-inference-image.
sudo docker build --tag my-inference-image ./
Dopo aver eseguito questo comando Docker per creare l'immagine, dovresti vedere l'output mentre Docker crea l'immagine in base a ciascuna riga del tuo. Dockerfile Al termine, dovresti vedere qualcosa di simile al seguente.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestEsecuzione di in locale
Una volta completata la compilazione, puoi testare l'immagine localmente.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --volume '<path_to_model>:/opt/ml/model:ro' \ --detach \ --name my-inference-container \ my-inference-image \ serve
Di seguito sono riportati i dettagli del comando:
-
--rm— Rimuove automaticamente il contenitore dopo l'arresto. -
--publish 8080:8080/tcp— Esporre la porta 8080 per simulare la porta a cui l' SageMaker IA invia le richieste HTTP. -
--volume '<path_to_model>:/opt/ml/model:ro'— Bind mount (il percorso in cui gli artefatti del modello di test sono archiviati sulla macchina host) come di sola lettura per renderli disponibili al codice di inferenza nel contenitore. -
--detach— Esegui il contenitore in background. -
--name my-inference-container— Assegna un nome a questo contenitore funzionante. -
my-inference-image— Esegui l'immagine creata. -
serve— Esegui lo stesso script che SageMaker AI esegue durante l'esecuzione del contenitore.
Dopo aver eseguito questo comando, Docker crea un contenitore dall'immagine di inferenza e lo esegue in background. Il contenitore esegue lo serve script, che avvia il server Web a scopo di test.
Esegui il test dell'endpoint HTTP per il ping
Quando l' SageMaker intelligenza artificiale esegue il container, esegue periodicamente il ping dell'endpoint. Quando l'endpoint restituisce una risposta HTTP con codice di stato 200, segnala all' SageMaker IA che il contenitore è pronto per l'inferenza.
Esegui il comando seguente per testare l'endpoint e includere l'intestazione della risposta.
curl --include http://127.0.0.1:8080/ping
L'output di esempio è mostrato nell'esempio seguente.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTVerifica l'endpoint HTTP di inferenza
Quando il contenitore indica di essere pronto restituendo un codice di stato 200, l' SageMaker IA passa i dati di inferenza all'endpoint /invocations HTTP tramite una richiesta. POST
Esegui il comando seguente per testare l'endpoint di inferenza.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
L'output di esempio è mostrato nell'esempio seguente.
{"prediction": "a", "text": "hello world"}Con questi due endpoint HTTP funzionanti, l'immagine di inferenza è ora compatibile con SageMaker l'IA.
Nota
Il modello del prodotto algoritmico può essere implementato in due modi: in tempo reale e in batch. Per entrambe le implementazioni, l' SageMaker intelligenza artificiale utilizza gli stessi endpoint HTTP durante l'esecuzione del contenitore Docker.
Per arrestare il contenitore, esegui il comando seguente.
sudo docker container stop my-inference-container
Dopo che le immagini di addestramento e di inferenza del prodotto algoritmico sono pronte e testate, continuateCaricamento delle immagini su Amazon Elastic Container Registry.
