Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizzazione delle query Gremlin con explain e profile
Spesso puoi ottimizzare le tue query Gremlin in Amazon Neptune per ottenere prestazioni migliori, utilizzando le informazioni disponibili nei report che ottieni dalla descrizione e dal profilo di Neptune. APIs A tale scopo, è utile capire come Neptune elabora gli attraversamenti di Gremlin.
Importante
Nella TinkerPop versione 3.4.11 è stata apportata una modifica che migliora la correttezza del modo in cui le query vengono elaborate, ma per il momento a volte può influire seriamente sulle prestazioni delle query.
Una query di questo tipo, ad esempio, può essere eseguita molto più lentamente:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
I vertici dopo il passaggio limite vengono ora recuperati in modo non ottimale a causa della modifica 3.4.11. TinkerPop Per evitare il problema, puoi modificare la query aggiungendo il passaggio barrier() in qualsiasi punto dopo order().by(). Per esempio:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop 3.4.11 è stato abilitato nella versione 1.0.5.0 del motore Neptune.
Informazioni sull'elaborazione degli attraversamenti di Gremlin in Neptune
Quando un attraversamento Gremlin viene inviato a Neptune, ci sono tre processi principali che trasformano l'attraversamento in un piano di esecuzione sottostante che il motore deve eseguire. Questi sono l'analisi, la conversione e l'ottimizzazione:
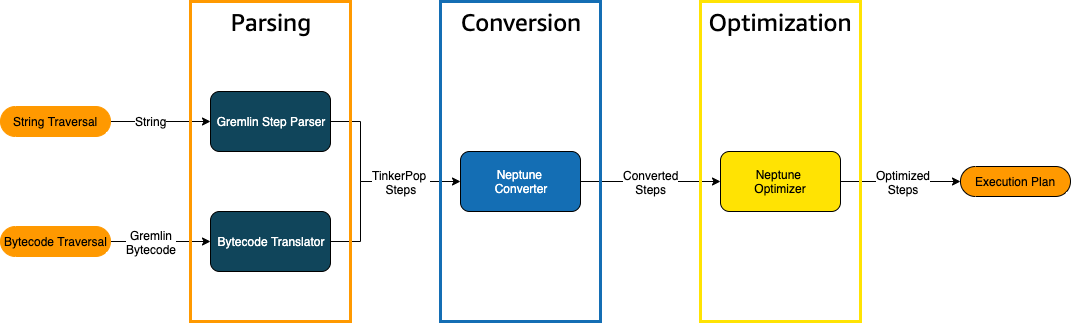
Processo di analisi di un attraversamento
Il primo passaggio nell'elaborazione di un attraversamento consiste nell'analizzarlo in un linguaggio comune. In Neptune, quel linguaggio comune è l'insieme TinkerPop di passaggi che fanno parte di. TinkerPopAPI
È possibile inviare un attraversamento Gremlin a Neptune come stringa o come bytecode. L'RESTendpoint e il submit() metodo del driver del client Java inviano gli attraversamenti come stringhe, come in questo esempio:
client.submit("g.V()")
Le applicazioni e i driver di linguaggio che utilizzano le varianti del linguaggio Gremlin () inviano gli attraversamenti in bytecode
Processo di conversione di un attraversamento
Il secondo passaggio nell'elaborazione di un attraversamento consiste nel convertire TinkerPop i suoi passaggi in un insieme di passaggi di Nettuno convertiti e non convertiti. La maggior parte dei passaggi del linguaggio di interrogazione Apache TinkerPop Gremlin viene convertita in passaggi specifici di Neptune ottimizzati per l'esecuzione sul motore Neptune sottostante. Quando si incontra un TinkerPop passaggio senza un equivalente di Neptune in un attraversamento, quel passaggio e tutti i passaggi successivi dell'attraversamento vengono elaborati dal motore di query. TinkerPop
Per ulteriori informazioni su quali passaggi possono essere convertiti e in quali circostanze, consulta Supporto dei passaggi Gremlin.
Processo di ottimizzazione di un attraversamento
Il passaggio finale dell'elaborazione di un attraversamento consiste nell'eseguire la serie di passaggi convertiti e non convertiti tramite l'ottimizzatore, per cercare di determinare il miglior piano di esecuzione. Il risultato di questa ottimizzazione è il piano di esecuzione elaborato dal motore Neptune.
Utilizzo di Neptune explain API Gremlin per ottimizzare le interrogazioni
La API spiegazione di Neptune non è la stessa del passo dei Gremlin. explain() Restituisce il piano di esecuzione finale che il motore Neptune elaborerà durante l'esecuzione della query. Poiché non esegue alcuna elaborazione, restituisce lo stesso piano indipendentemente dai parametri utilizzati e l'output non contiene statistiche sull'esecuzione effettiva.
Considerare il semplice attraversamento seguente che trova tutti i vertici dell'aeroporto di Anchorage:
g.V().has('code','ANC')
Esistono due modi per eseguire questa traversata attraverso il Nettuno. explain API Il primo modo è effettuare una REST chiamata all'endpoint explain, in questo modo:
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
Il secondo modo consiste nell'utilizzare il comando magic di cella %%gremlin di Neptune Workbench con il parametro explain. Questo passa l'attraversamento contenuto nel corpo cellulare a Nettuno explain API e quindi visualizza l'output risultante quando si esegue la cella:
%%gremlin explain g.V().has('code','ANC')
L'explainAPIoutput risultante descrive il piano di esecuzione di Neptune per l'attraversamento. Come si può vedere nell'immagine seguente, il piano include ognuno dei 3 passaggi della pipeline di elaborazione:
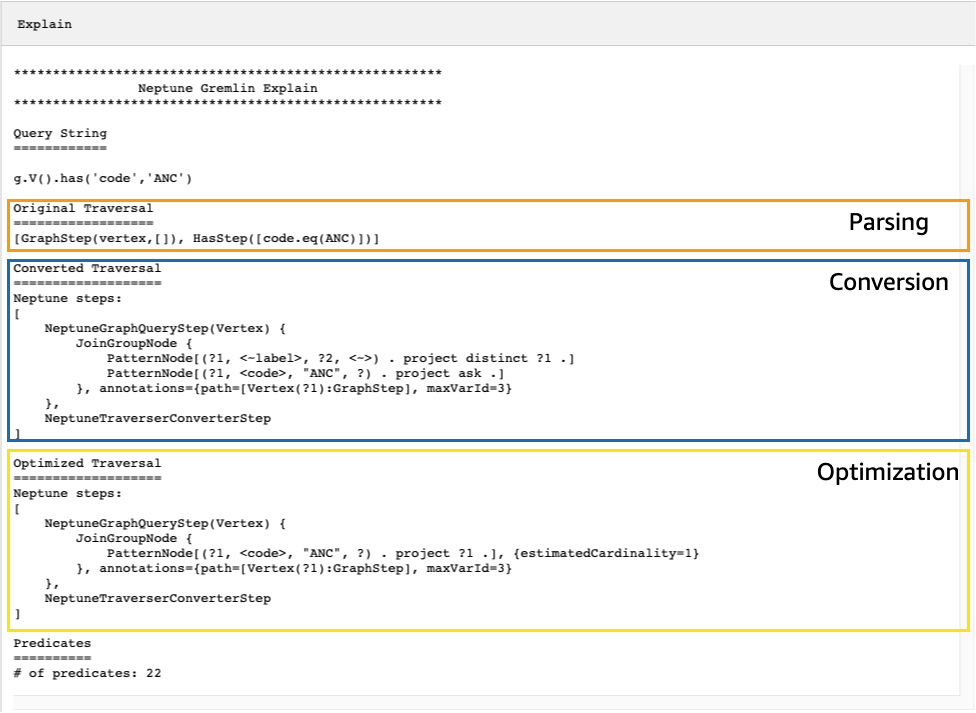
Ottimizzazione di un attraversamento osservando i passaggi non convertiti
Una delle prime cose da cercare nell'output di explain API Neptune riguarda i passaggi Gremlin che non vengono convertiti in passaggi nativi di Neptune. In un piano di query, quando viene rilevato un passaggio che non può essere convertito in un passaggio nativo Neptune, questo passaggio e tutti i passaggi successivi del piano vengono elaborati dal server Gremlin.
Nell'esempio riportato sopra, tutti i passaggi dell'attraversamento sono stati convertiti. Esaminiamo l'output di questo attraversamento: explain API
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
Come si può vedere nell'immagine qui sotto, Neptune non è riuscito a convertire il passaggio choose():
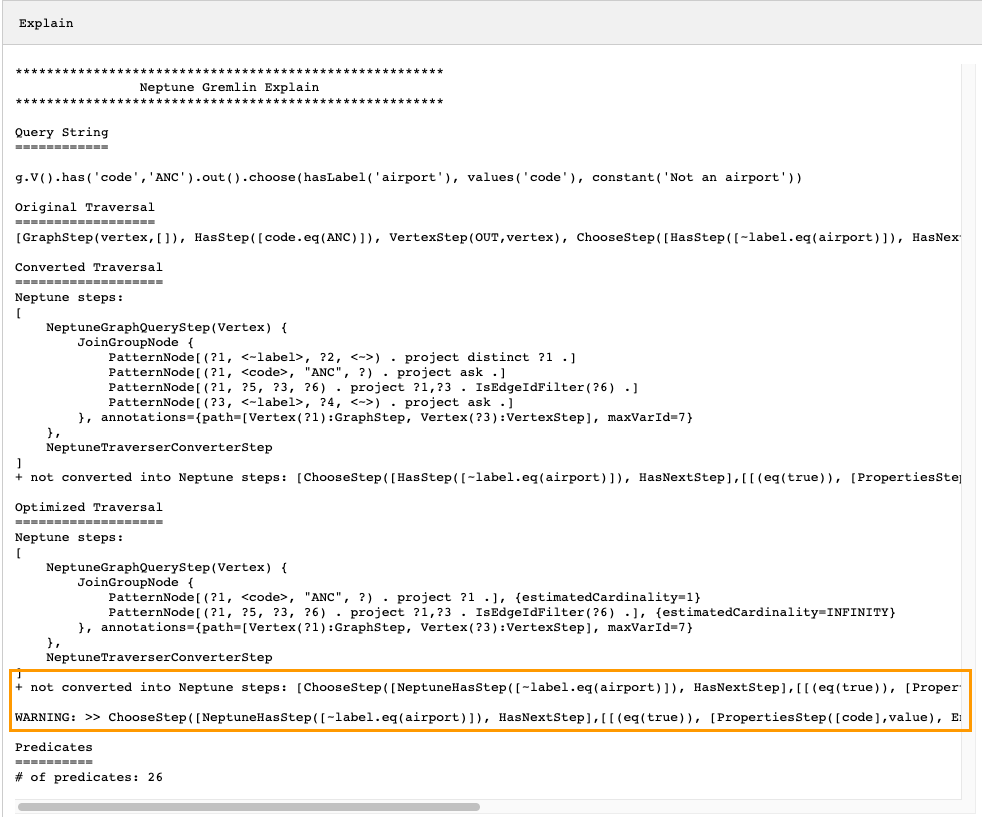
Ci sono diverse cose che si possono fare per ottimizzare le prestazioni dell'attraversamento. La prima sarebbe quella di riscriverlo in modo tale da eliminare il passaggio che non può essere convertito. Un'altra potrebbe essere quella di spostare il passaggio alla fine dell'attraversamento in modo che tutti gli altri passaggi possano essere convertiti in passaggi nativi.
Non è sempre necessario ottimizzare un piano di query con passaggi non convertiti. Se i passaggi che non possono essere convertiti si trovano alla fine dell'attraversamento e sono correlati al modo in cui viene formattato l'output anziché a come viene attraversato il grafo, possono avere un effetto minimo sulle prestazioni.
Un'altra cosa da cercare quando si esamina l'output di explain API Neptune sono i passaggi che non utilizzano indici. Il seguente attraversamento trova tutti gli aeroporti con voli che atterrano ad Anchorage:
g.V().has('code','ANC').in().values('code')
L'output della descrizione di questo attraversamento è: API
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
Il messaggio WARNING nella parte inferiore dell'output è dovuto al fatto che il passaggio in() dell'attraversamento non può essere gestito utilizzando uno dei 3 indici gestiti da Neptune (vedi In che modo le dichiarazioni vengono indicizzate in Neptune e Dichiarazioni Gremlin in Neptune). Poiché il passaggio in() non contiene alcun filtro per gli archi, non può essere risolto utilizzando l'indice SPOG, POGS o GPSO. Neptune deve invece eseguire una scansione di unione per trovare i vertici richiesti, il che è molto meno efficiente.
Esistono due modi per ottimizzare l'attraversamento in questa situazione. Il primo consiste nell'aggiungere uno o più criteri di filtro al passaggio in() in modo da poter utilizzare una ricerca indicizzata per risolvere la query. Per l'esempio precedente, si avrà:
g.V().has('code','ANC').in('route').values('code')
L'output di explain API Neptune per l'attraversamento rivisto non contiene più il messaggio: WARNING
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
Un'altra opzione se si eseguono molti attraversamenti di questo tipo è quella di eseguirli in un cluster database Neptune con l'indice OSGP opzionale abilitato (vedi Abilitazione di un OSGP indice). L'abilitazione di un indice OSGP presenta degli svantaggi:
Deve essere abilitato in un cluster database prima che vengano caricati i dati.
La velocità di inserimento di vertici e archi può rallentare fino al 23%.
L'utilizzo dello spazio di archiviazione aumenterà di circa il 20%.
Le query di lettura che distribuiscono le richieste su tutti gli indici possono avere latenze maggiori.
Avere un indice OSGP è molto utile per un insieme limitato di modelli di query, ma a meno che non li si esegua frequentemente, in genere è preferibile cercare di garantire che gli attraversamenti scritti possano essere risolti utilizzando i tre indici primari.
Utilizzo di un numero elevato di predicati
Neptune considera ogni etichetta di arco e ogni nome distinto di proprietà di vertice o arco nel grafo come predicato ed è progettato per impostazione predefinita per funzionare con un numero relativamente basso di predicati distinti. Quando i dati del grafo contengono più di qualche migliaio di predicati, le prestazioni possono peggiorare.
L'output di Neptune explain avviserà se questo è il caso:
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
Se non è conveniente rielaborare il modello di dati per ridurre il numero di etichette e proprietà, e quindi il numero di predicati, il modo migliore per ottimizzare gli attraversamenti è eseguirli in un cluster database con l'indice OSGP abilitato, come descritto in precedenza.
Usare il Neptune profile API Gremlin per regolare le traversate
Il profile API Neptune è molto diverso dal passo Gremlin. profile() Come il explainAPI, il suo output include il piano di interrogazione utilizzato dal motore Neptune durante l'esecuzione dell'attraversamento. Inoltre, l'output di profile include le statistiche di esecuzione effettive per l'attraversamento, in base a come sono impostati i parametri.
Considerare anche in questo caso il semplice attraversamento che trova tutti i vertici dell'aeroporto di Anchorage:
g.V().has('code','ANC')
Come con il explainAPI, puoi invocarlo usando una chiamata: profile API REST
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
È anche possibile utilizzare il comando magic di cella %%gremlin di Neptune Workbench con il parametro profile. Questo passa l'attraversamento contenuto nel corpo cellulare a Nettuno profile API e quindi visualizza l'output risultante quando si esegue la cella:
%%gremlin profile g.V().has('code','ANC')
L'profileAPIoutput risultante contiene sia il piano di esecuzione di Neptune per l'attraversamento sia le statistiche sull'esecuzione del piano, come puoi vedere in questa immagine:
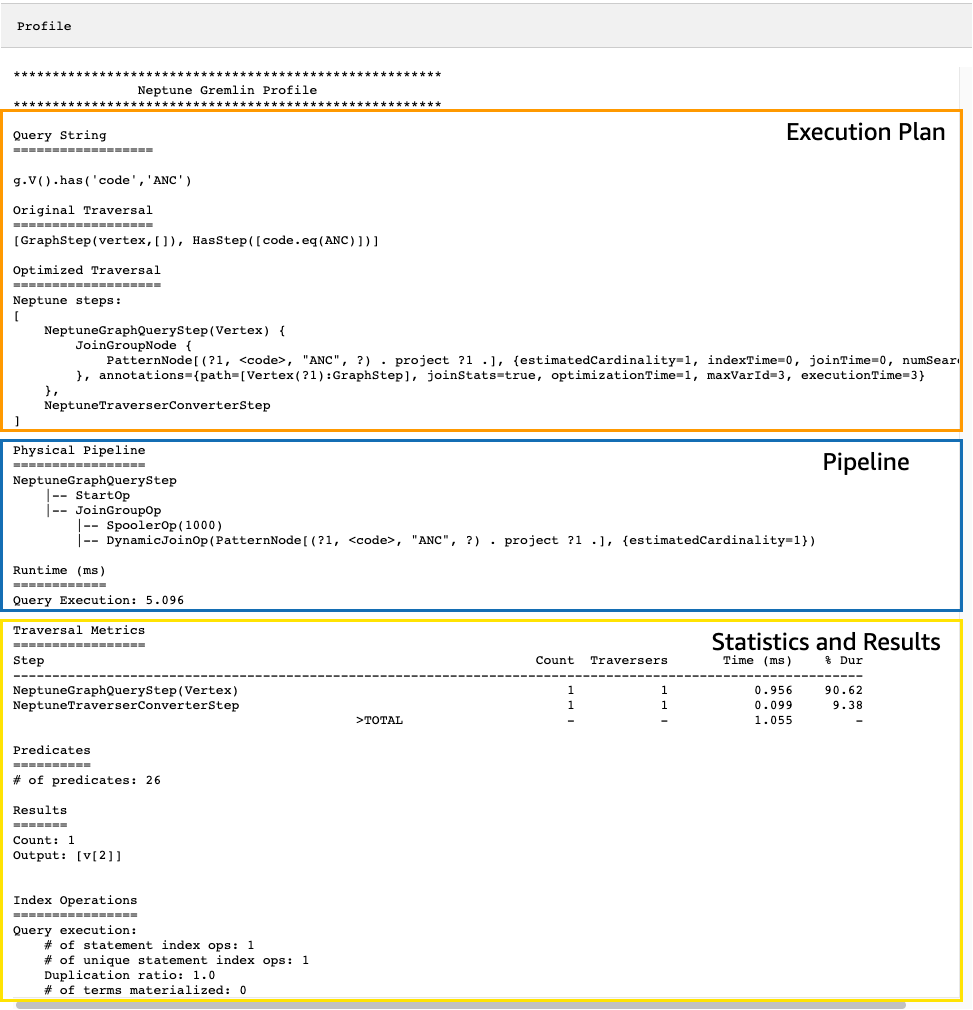
Nell'output di profile, la sezione del piano di esecuzione contiene solo il piano di esecuzione finale per l'attraversamento, non i passaggi intermedi. La sezione della pipeline contiene le operazioni della pipeline fisica che sono state eseguite e il tempo effettivo (in millisecondi) impiegato dall'esecuzione dell'attraversamento. La metrica di runtime è estremamente utile per confrontare i tempi impiegati da due diverse versioni di un attraversamento durante l'ottimizzazione.
Nota
Il runtime iniziale di un attraversamento è generalmente più lungo rispetto ai runtime successivi, poiché il primo fa sì che i dati pertinenti vengano memorizzati nella cache.
La terza sezione dell'output di profile contiene le statistiche di esecuzione e i risultati dell'attraversamento. Per capire come queste informazioni possano essere utili per ottimizzare un attraversamento, considerare il seguente attraversamento, che trova tutti gli aeroporti il cui nome inizia con "Anchora" e tutti gli aeroporti raggiungibili in due fermate da tali aeroporti, indicando i codici aeroportuali, le rotte di volo e le distanze:
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Metriche trasversali nell'output di Neptune profile API
Il primo set di metriche disponibile in tutti gli output di profile è costituito dalle metriche di attraversamento. Sono simili alle metriche del passaggio profile() di Gremlin, con alcune differenze:
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
La prima colonna della tabella delle metriche di attraversamento elenca i passaggi eseguiti dall'attraversamento. I primi due passaggi sono generalmente i passaggi specifici di Neptune, NeptuneGraphQueryStep e NeptuneTraverserConverterStep.
NeptuneGraphQueryStep rappresenta il tempo di esecuzione per l'intera porzione dell'attraversamento che potrebbe essere convertito ed eseguito in modo nativo dal motore Neptune.
NeptuneTraverserConverterSteprappresenta il processo di conversione dell'output di quei passaggi convertiti in TinkerPop traverser che consentono di elaborare passaggi che non possono essere convertiti, se ce ne sono, o di restituire i risultati in un formato compatibile. TinkerPop
Nell'esempio precedente, abbiamo diversi passaggi non convertiti, quindi vediamo che ognuno di questi TinkerPop passaggi (ProjectStep,PathStep) appare quindi come una riga nella tabella.
Nell'esempio ci sono 3.856 vertici e 3.856 traverser restituiti da NeptuneGraphQueryStep, e questi numeri rimangono invariati per tutta l'elaborazione rimanente perché ProjectStep e PathStep stanno formattando i risultati, non li filtrano.
Nota
Al contrario TinkerPop, il motore Neptune non ottimizza le prestazioni ingombrando i suoi passaggi. NeptuneGraphQueryStep NeptuneTraverserConverterStep Il bulking è l' TinkerPopoperazione che combina i trasversali sullo stesso vertice per ridurre il sovraccarico operativo, e questo è ciò che causa la differenza tra i numeri e. Count Traversers Poiché il bulking si verifica solo nelle fasi a cui Neptune è delegato e non nelle fasi gestite TinkerPop da Neptune in modo nativo, le colonne and raramente differiscono. Count Traverser
La colonna Time riporta il numero di millisecondi impiegato dal passaggio e la colonna % Dur riporta la percentuale del tempo di elaborazione totale impiegato dal passaggio. Queste sono le metriche che indicano dove concentrare gli sforzi di ottimizzazione, mostrando i passaggi che hanno richiesto più tempo.
Indicizza le metriche operative nell'output di Neptune profile API
Un altro set di metriche nell'output del API profilo Neptune sono le operazioni sull'indice:
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
Queste metriche riportano:
Numero totale di ricerche nell'indice.
Numero di ricerche univoche eseguite nell'indice.
Rapporto tra le ricerche totali nell'indice e quelle univoche. Un rapporto più basso indica una minore ridondanza.
Numero di termini materializzati dal dizionario dei termini.
Ripeti le metriche nell'output di Neptune profile API
Se l'attraversamento utilizza un passaggio repeat() come nell'esempio precedente, nell'output di profile viene visualizzata una sezione contenente le metriche di ripetizione:
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
Queste metriche riportano:
Conteggio dei cicli per una riga (colonna
Iteration).Numero di elementi visitati dal ciclo (colonna
Visited).Numero di elementi restituiti dal ciclo (colonna
Output).Ultimo elemento restituito dal ciclo (colonna
Until).Numero di elementi emessi dal ciclo (colonna
Emit).Numero di elementi passati dal ciclo al ciclo successivo (colonna
Next).
Queste metriche di ripetizione sono molto utili per comprendere il fattore di ramificazione dell'attraversamento e per avere un'idea di quanto lavoro venga svolto dal database. È possibile utilizzare questi numeri per diagnosticare problemi di prestazioni, soprattutto quando lo stesso attraversamento si comporta in modo notevolmente diverso con parametri diversi.
Metriche di ricerca full-text nell'output di Neptune profile API
Quando un traversal utilizza una ricerca di testo completo, come nell'esempio precedente, nell'output viene visualizzata una sezione contenente le metriche di ricerca full-text (): FTS profile
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
Questo mostra la query inviata al cluster ElasticSearch (ES) e riporta diverse metriche sull'interazione con ElasticSearch cui puoi individuare i problemi di prestazioni relativi alla ricerca di testo completo:
-
Informazioni di riepilogo sulle chiamate all'indice: ElasticSearch
Il numero totale di millisecondi richiesti da tutti remoteCalls per soddisfare la query ().
totalIl numero medio di millisecondi trascorsi in a (). remoteCall
avgIl numero minimo di millisecondi trascorsi in a (). remoteCall
minIl numero massimo di millisecondi trascorsi in a (). remoteCall
max
Tempo totale impiegato da remoteCalls to ElasticSearch ().
remoteCallTimeIl numero di remoteCalls made to ElasticSearch (
remoteCalls).Il numero di millisecondi spesi per unire i risultati (). ElasticSearch
joinTimeNumero di millisecondi trascorsi nelle ricerche nell'indice (
indexTime).Il numero totale di risultati restituiti da (). ElasticSearch
remoteResults
