Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio delle metriche dei OpenSearch cluster con Amazon CloudWatch
Amazon OpenSearch Service pubblica i dati dei tuoi domini su Amazon. CloudWatch CloudWatch ti consente di recuperare le statistiche su tali punti dati sotto forma di un insieme ordinato di dati di serie temporali, noti come metriche. OpenSearch Il servizio invia la maggior parte delle metriche a CloudWatch intervalli di 60 secondi. Se utilizzi volumi magnetici EBS o per uso generale, i parametri relativi al volume EBS si aggiorneranno ogni cinque minuti. Tutte le metriche cumulative (ad esempioThreadpoolSearchRejected) sono in memoria e ThreadpoolWriteRejected perderanno lo stato. Le metriche verranno reimpostate durante la caduta di un nodo, il rimbalzo del nodo, la sostituzione del nodo e la distribuzione. blue/green Per ulteriori informazioni su Amazon CloudWatch, consulta la Amazon CloudWatch User Guide.
La console OpenSearch di servizio mostra una serie di grafici basati sui dati grezzi di CloudWatch. A seconda delle esigenze, potresti preferire visualizzare i dati del cluster CloudWatch anziché i grafici nella console. Il servizio archivia i parametri per due settimane prima di eliminarli. Le metriche vengono fornite senza costi aggiuntivi, ma sono CloudWatch comunque a pagamento per la creazione di dashboard e allarmi. Per ulteriori informazioni, consulta i CloudWatchprezzi di Amazon
OpenSearch Il servizio pubblica le seguenti metriche su: CloudWatch
Visualizzazione delle metriche in CloudWatch
CloudWatch le metriche vengono raggruppate prima in base allo spazio dei nomi del servizio e quindi in base alle varie combinazioni di dimensioni all'interno di ogni spazio dei nomi.
Per visualizzare le metriche utilizzando la console CloudWatch
-
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. -
Nel pannello di navigazione a sinistra, scegli Metrics (Parametri), quindi scegli All metrics (Tutti i parametri). Seleziona lo spazio dei nomi ES.
-
Scegliere una dimensione per visualizzare i parametri corrispondenti. I parametri per i singoli nodi si trovano nella dimensione
ClientId, DomainName, NodeId. I parametri del cluster si trovano nella dimensionePer-Domain, Per-Client Metrics. Alcuni parametri dei nodi vengono aggregati a livello di cluster e quindi inclusi in entrambe le dimensioni. I parametri delle partizioni si trovano nella dimensioneClientId, DomainName, NodeId, ShardRole.
Per visualizzare un elenco di metriche utilizzando il AWS CLI
Esegui il comando seguente:
aws cloudwatch list-metrics --namespace "AWS/ES"
Interpretazione delle cartelle cliniche in Service OpenSearch
Per visualizzare le metriche in OpenSearch Service, utilizza le schede Cluster Health e Instance Health. La scheda Instance Health utilizza diagrammi a riquadri per fornire una visibilità immediata dello stato di ciascun nodo: OpenSearch
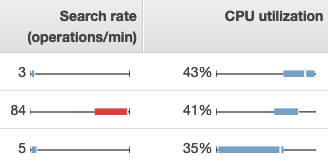
-
Ogni casella colorata mostra l'intervallo di valori per il nodo nel periodo di tempo specificato.
-
Le caselle blu rappresentano i valori che sono compatibili con gli altri nodi. Le caselle rosse rappresentano i valori erratici.
-
La linea bianca all'interno di ogni casella mostra il valore corrente del nodo.
-
Le "parentesi angolari" su entrambi i lati di ciascuna casella mostrano i valori minimo e massimo per tutti i nodi nel periodo di tempo.
Se si apportano modifiche alla configurazione del dominio, l'elenco delle singole istanze nelle schede Cluster health (Stato cluster) e Instance health (Stato istanza) raddoppierà spesso in dimensione per un breve periodo prima di tornare al numero corretto. Per una spiegazione del comportamento, consulta Apportare modifiche alla configurazione in Amazon OpenSearch Service.
Parametri cluster
Amazon OpenSearch Service fornisce le seguenti metriche per i cluster.
| Metrica | Description |
|---|---|
ClusterStatus.green |
Un valore pari a 1 indica che tutte le partizioni di indice sono assegnate a nodi nel cluster. Statistiche rilevanti: Massima |
ClusterStatus.yellow |
Un valore pari a 1 indica che le partizioni principali per tutti gli indici sono allocate a nodi nel cluster, ma che le partizioni di replica per almeno un indice non lo sono. Per ulteriori informazioni, consulta Stato giallo del cluster. Statistiche rilevanti: Massima |
ClusterStatus.red |
Un valore pari a 1 indica che le partizioni primarie e di replica di almeno un indice non sono allocate ai nodi nel cluster. Per ulteriori informazioni, consultare Cluster in stato rosso. Statistiche rilevanti: Massima |
Shards.active |
Il numero totale di partizioni primarie e di replica attive. Statistiche rilevanti: Massima, Somma |
Shards.unassigned |
Il numero di partizioni non allocate ai nodi nel cluster. Statistiche rilevanti: Massima, Somma |
Shards.delayedUnassigned |
Il numero di partizioni la cui allocazione dei nodi è stata ritardata dalle impostazioni di timeout. Statistiche rilevanti: Massima, Somma |
Shards.activePrimary |
Il numero di partizioni primarie attive. Statistiche rilevanti: Massima, Somma |
Shards.initializing |
Il numero di partizioni in fase di inizializzazione. Statistiche rilevanti: Sum (Somma) |
Shards.relocating |
Il numero di partizioni in fase di rilocazione. Statistiche rilevanti: Sum (Somma) |
Nodes |
Il numero di nodi nel cluster di OpenSearch servizio, inclusi i nodi master dedicati e i nodi Warm. Per ulteriori informazioni, consulta Apportare modifiche alla configurazione in Amazon OpenSearch Service. Statistiche rilevanti: Massima |
SearchableDocuments |
Il numero totale di documenti disponibili per la ricerca tra tutti i nodi di dati nel cluster. Statistiche rilevanti: Minima, Massima, Media |
DeletedDocuments |
Il numero totale di documenti contrassegnati per l'eliminazione tra tutti i nodi di dati nel cluster. Questi documenti non vengono più visualizzati nei risultati di ricerca, ma rimuovono dal disco OpenSearch solo i documenti eliminati durante l'unione dei segmenti. Questo parametro aumenta dopo le richieste di eliminazione e diminuisce dopo la fusione dei segmenti. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
CPUUtilization |
Percentuale di utilizzo della CPU per i nodi di dati nel cluster. Il numero massimo mostra il nodo con il più alto utilizzo della CPU. La media rappresenta tutti i nodi del cluster. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Maximum (Massimo), Average (Media) |
FreeStorageSpace |
Lo spazio libero per i nodi di dati nel cluster. La console OpenSearch di servizio visualizza questo valore in GiB. La CloudWatch console Amazon lo visualizza in MiB. Nota
Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo), Average (Media), Sum (Somma) |
ClusterUsedSpace |
Lo spazio totale utilizzato per il cluster. È necessario lasciare il periodo su un minuto per ottenere un valore preciso. La console OpenSearch di servizio visualizza questo valore in GiB. La CloudWatch console Amazon lo visualizza in MiB. Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
ClusterIndexWritesBlocked |
Indica se il cluster accetta o blocca le richieste di scrittura in entrata. Un valore pari a 0 significa che il cluster accetta le richieste. Un valore pari a 1 significa che il cluster blocca le richieste. Alcuni fattori comuni sono i seguenti: Statistiche rilevanti: Massima |
JVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per tutti i nodi di dati del cluster. OpenSearch Il servizio utilizza metà della RAM di un'istanza per l'heap Java, fino a una dimensione dell'heap di 32 GiB. Puoi scalare le istanze verticalmente fino a 64 GiB di RAM e poi scalare orizzontalmente aggiungendo le istanze. Per informazioni, consulta CloudWatch Allarmi consigliati per Amazon Service OpenSearch. Statistiche rilevanti: Massima NotaLa logica di questo parametro è cambiata nel software del servizio R20220323. Per ulteriori informazioni, consulta le note di rilascio. |
OldGenJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per la "vecchia generazione" di tutti i nodi di dati nel cluster. Questo parametro è disponibile anche a livello di nodo. Statistiche rilevanti: Massima |
AutomatedSnapshotFailure |
Il numero di snapshot automatici non riusciti per il cluster. Un valore pari a Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
CPUCreditBalance |
I crediti CPU rimanenti disponibili per i nodi di dati nel cluster. Un credito CPU fornisce le prestazioni di un core CPU completo per un minuto. Per ulteriori informazioni, consultare Crediti CPU nella Guida per gli sviluppatori di Amazon EC2. Questo parametro è disponibile solo per i tipi di istanza T2. Statistiche rilevanti: Minimum (Minimo) |
OpenSearchDashboardsHealthyNodes |
Un controllo dello stato di salute per Dashboards. OpenSearch Se il valore minimo, massimo e medio sono tutti uguali a 1, Dashboards si comporta normalmente. Se si dispone di 10 nodi con un massimo di 1, minimo di 0 e media di 0,7, allora significa che 7 nodi (70%) sono integri e 3 nodi (30%) non lo sono. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
OpensearchDashboardsReportingFailedRequestSysErrCount |
Il numero di richieste di generazione di report di OpenSearch Dashboard che non sono riuscite a causa di problemi del server o limitazioni delle funzionalità. Statistiche rilevanti: Sum (Somma) |
OpensearchDashboardsReportingFailedRequestUserErrCount |
Il numero di richieste di generazione di report di OpenSearch Dashboards che non sono riuscite a causa di problemi del client. Statistiche rilevanti: Sum (Somma) |
OpensearchDashboardsReportingRequestCount |
Il numero totale di richieste per generare OpenSearch report Dashboards. Statistiche rilevanti: Sum (Somma) |
OpensearchDashboardsReportingSuccessCount |
Il numero di richieste riuscite per generare OpenSearch report di Dashboards. Statistiche rilevanti: Sum (Somma) |
KMSKeyError |
Il valore 1 indica che la AWS KMS chiave utilizzata per crittografare i dati inattivi è stata disabilitata. Per ripristinare il dominio sulle operazioni normali, riabilita la chiave. La console visualizza questo parametro solo per i domini che crittografano i dati a riposo. Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
KMSKeyInaccessible |
Il valore 1 indica che la AWS KMS chiave utilizzata per crittografare i dati inattivi è stata eliminata o le relative concessioni al Servizio sono state revocate. OpenSearch Non è possibile recuperare i domini che sono in questo stato. Se hai una snapshot manuale, puoi utilizzarla per migrare i dati del dominio in un nuovo dominio. La console visualizza questo parametro solo per i domini che crittografano i dati a riposo. Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
InvalidHostHeaderRequests |
Il numero di richieste HTTP effettuate al OpenSearch cluster che includevano un'intestazione host non valida (o mancante). Le richieste valide includono il nome host del dominio come valore dell'intestazione dell'host. OpenSearch Il servizio rifiuta le richieste non valide per i domini di accesso pubblico che non dispongono di una politica di accesso restrittiva. Si consiglia di applicare una policy di accesso restrittiva a tutti i domini. Se per questo parametro si rilevano valori di grandi dimensioni, confermare che i client OpenSearch includano il nome host del dominio (e non, ad esempio, l'indirizzo IP) nelle richieste. Statistiche rilevanti: Sum (Somma) |
OpenSearchRequests (previously
ElasticsearchRequests) |
Il numero di richieste fatte al cluster. OpenSearch Statistiche rilevanti: Sum (Somma) |
TLSNegotiationError |
Il numero di tentativi falliti di handshake TLS tra i client e l'endpoint del dominio. Questa metrica aumenta quando un client tenta di connettersi utilizzando una versione TLS o una suite di crittografia non supportata. Statistiche rilevanti: Sum (Somma) |
2xx, 3xx, 4xx, 5xx |
Il numero di richieste al dominio che hanno prodotto il codice di risposta HTTP specificato (2xx, 3xx, 4xx, 5xx). Statistiche rilevanti: Sum (Somma) |
ThroughputThrottle |
Indica se i dischi sono stati limitati o meno. La limitazione si verifica quando la velocità effettiva combinata di Per informazioni sulla velocità effettiva delle istanze, consulta Amazon EBS: istanze ottimizzate. Per informazioni sulla velocità effettiva dei volumi, consulta i tipi di volume di Amazon EBS. Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
IopsThrottle |
Indica se il numero di input/output operazioni al secondo (IOPS) sul dominio è stato limitato o meno. La limitazione si verifica quando gli IOPS del nodo dati superano il limite massimo consentito del volume EBS o dell'istanza EC2 del nodo dati. Per informazioni sugli IOPS delle istanze, consulta Amazon EBS: istanze ottimizzate. Per informazioni sugli IOPS di volume, consulta i tipi di volume di Amazon EBS. Statistiche rilevanti: Minimum (Minimo), Maximum (Massimo) |
HighSwapUsage |
Il valore 1 indica che lo scambio dovuto a errori di pagina ha potenzialmente causato picchi nell'utilizzo del disco sottostante durante un periodo di tempo specifico. Statistiche rilevanti: Massima |
Parametri nodo master dedicato
Amazon OpenSearch Service fornisce le seguenti metriche per i nodi master dedicati.
| Metrica | Description |
|---|---|
MasterCPUUtilization |
La percentuale massima di risorse della CPU utilizzate dai nodi master dedicati. È consigliato aumentare le dimensioni del tipo di istanza quando questo parametro raggiunge 60%. Statistiche rilevanti: Massima |
MasterFreeStorageSpace |
Questo parametro non è rilevante e può essere ignorato. Il servizio non utilizza i nodi master come nodi di dati. |
MasterJVMMemoryPressure |
La percentuale massima dell'heap di Java utilizzata per tutti i nodi master dedicati nel cluster. È consigliato passare a un tipo di istanza più grande quando questo parametro raggiunge 85%. Statistiche rilevanti: Massima NotaLa logica di questo parametro è cambiata nel software del servizio R20220323. Per ulteriori informazioni, consulta le note di rilascio. |
MasterOldGenJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per la "vecchia generazione" per ciascun nodo principale. Statistiche rilevanti: Massima |
MasterCPUCreditBalance |
I crediti CPU rimanenti disponibili per i nodi master dedicati nel cluster. Un credito CPU fornisce le prestazioni di un core CPU completo per un minuto. Per ulteriori informazioni, consultare Crediti CPU nella Guida per gli sviluppatori di Amazon EC2. Questo parametro è disponibile solo per i tipi di istanza T2. Statistiche rilevanti: Minimum (Minimo) |
MasterReachableFromNode |
Un controllo dello stato per le eccezioni Gli errori indicano che il nodo master non è raggiungibile dal nodo di origine. Di solito sono il risultato di un problema di connettività di rete o di un AWS problema di dipendenza. Statistiche rilevanti: Massima |
MasterSysMemoryUtilization |
La percentuale di memoria del nodo master utilizzata. Statistiche rilevanti: Massima |
Metriche del nodo di coordinatore dedicato
Amazon OpenSearch Service fornisce le seguenti metriche per i nodi coordinatori dedicati.
| Metrica | Description |
|---|---|
CoordinatorCPUUtilization |
La percentuale massima di risorse CPU utilizzate dai nodi coordinatori dedicati. Ti consigliamo di aumentare la dimensione del tipo di istanza quando questa metrica raggiunge l'80%. Statistiche rilevanti: Massima |
CoordinatorJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per tutti i nodi coordinatori dedicati nel cluster. È consigliato passare a un tipo di istanza più grande quando questo parametro raggiunge 85%. Statistiche rilevanti: Massima |
CoordinatorOldGenJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per la "vecchia generazione" per ciascun nodo principale. Statistiche rilevanti: Massima |
CoordinatorSysMemoryUtilization |
La percentuale di memoria del nodo coordinatore in uso. Statistiche rilevanti: Massima |
CoordinatorFreeStorageSpace |
Questa metrica indica che il servizio non utilizza i nodi coordinatori come nodi di dati. |
Parametri volume EBS
Amazon OpenSearch Service fornisce le seguenti metriche per i volumi EBS.
| Metrica | Description |
|---|---|
ReadLatency |
La latenza, in secondi, per le operazioni di lettura sui volumi di EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
WriteLatency |
La latenza, in secondi, per le operazioni di scrittura sui volumi di EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
ReadThroughput |
Il throughput, in byte al secondo, per le operazioni di lettura sui volumi di EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
ReadThroughputMicroBursting |
Il throughput, in byte al secondo, per le operazioni di lettura sui volumi EBS quando si prende in considerazione il microbursting Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
WriteThroughput |
Il throughput, in byte al secondo, per le operazioni di scrittura sui volumi di EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
WriteThroughputMicroBursting |
La velocità effettiva, in byte al secondo, per le operazioni di scrittura su volumi EBS quando si prende in considerazione il microbursting. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
DiskQueueDepth |
Il numero di richieste di input e output (I/O) in sospeso per un volume EBS. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
ReadIOPS |
Il numero di operazioni di input e output (I/O) al secondo per le operazioni di lettura sui volumi EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
ReadIOPSMicroBursting |
Il numero di operazioni di input e output (I/O) al secondo per le operazioni di lettura sui volumi EBS quando si prende in considerazione il microbursting Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
WriteIOPS |
Il numero di operazioni di input e output (I/O) al secondo per le operazioni di scrittura su volumi EBS. Questo parametro è disponibile anche per singoli nodi. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
WriteIOPSMicroBursting |
Il numero di operazioni di input e output (I/O) al secondo per le operazioni di scrittura sui volumi EBS quando si prende in considerazione il microbursting Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
BurstBalance |
La percentuale di crediti di input e output (I/O) rimanenti nel burst bucket per un volume EBS. Un valore pari a 100 indica che il volume ha accumulato il numero massimo di crediti. Se questa percentuale scende al di sotto del 70%, consulta Saldo di burst EBS basso. Il saldo di espansione rimane a 0 per i domini con tipi di volumi gp3 e i domini con volumi gp2 con una dimensione del volume superiore a 1.000 GiB. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
VolumeStalledIOcheck |
Lo stato dei tuoi volumi EBS per determinare quando sono compromessi. La metrica è un valore binario che restituisce lo stato 0 (passaggio) o 1 (errore) a seconda che il volume EBS sia in grado di completare le operazioni di input e output. Statistiche rilevanti: Minimum, Maximum, Average (Minimo, Massimo, Medio) |
Parametri dell'istanza
Amazon OpenSearch Service fornisce le seguenti metriche per ogni istanza in un dominio. OpenSearch Il servizio aggrega inoltre questi parametri delle istanze per fornire informazioni sullo stato generale del cluster. È possibile verificare questo comportamento utilizzando la statistica Conteggio del campione nella console. Nota che ogni parametro nella tabella seguente dispone di statistiche rilevanti per il nodo e il cluster.
Importante
Versioni diverse di Elasticsearch utilizzano pool di thread diversi per elaborare le chiamate all'API _index. Elasticsearch 1.5 e 2.3 utilizzano il pool di thread di indice. Elasticsearch 5. x, 6.0 e 6.2 utilizzano il pool di thread in blocco. OpenSearch e Elasticsearch 6.3 e versioni successive utilizzano il pool di thread di scrittura. Attualmente, la console OpenSearch di servizio non include un grafico per il pool di thread in blocco.
Utilizzare GET _cluster/settings?include_defaults=true per controllare le dimensioni del pool di thread e della coda per il cluster.
| Metrica | Description |
|---|---|
FetchLatency |
La differenza nel tempo totale, in millisecondi, rilevata da tutte le operazioni di shard fetch in un nodo tra il minuto N e il minuto (N - 1). Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
FetchRate |
Il numero totale di operazioni di shard fetch al minuto per tutti gli shard su un nodo di dati. Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
ScrollTotal |
Il numero totale di operazioni di shard scroll al minuto per tutti gli shard su un nodo di dati. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma |
ScrollCurrent |
Il numero di operazioni di shard scroll attualmente in esecuzione. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma |
OpenContexts |
Il numero di contesti di ricerca aperti. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma |
ThreadCount |
Il numero totale di thread attualmente utilizzati dal OpenSearch processo. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma |
ShardReactivateCount |
Il numero totale di volte in cui tutti gli shard sono stati attivati da uno stato di inattività. Statistiche relative ai nodi: Sum, Maximum Statistiche pertinenti sui cluster: somma, massima |
ConcurrentSearchRate |
Il numero totale di richieste di ricerca che utilizzano la ricerca simultanea per segmenti al minuto per tutti gli shard su un nodo di dati. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
ConcurrentSearchLatency |
La differenza nel tempo totale, in millisecondi, impiegato da tutte le ricerche utilizzando la ricerca simultanea per segmenti in un nodo tra il minuto N e il minuto (). N-1 Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
IndexingLatency |
La differenza nel tempo totale, in millisecondi, rilevata da tutte le operazioni di indicizzazione in un nodo tra il minuto N e il minuto (). N-1 Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
IndexingRate |
Il numero di operazioni di indicizzazione al minuto. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
SearchLatency |
La differenza nel tempo totale, in millisecondi, impiegato da tutte le ricerche in un nodo tra il minuto N e il minuto (). N-1 Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
SearchRate |
Il numero totale di richieste di ricerca al minuto per tutte le partizioni in un nodo di dati. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
SegmentCount |
Il numero di segmenti in un nodo di dati. Più segmenti hai, più tempo impiega ogni ricerca. OpenSearch occasionalmente unisce segmenti più piccoli in segmenti più grandi. Statistiche nodo rilevanti: Massima, Media Statistiche del cluster rilevanti: Somma, Massimo, Media |
SysMemoryUtilization |
La percentuale di memoria dell'istanza utilizzata. I valori elevati per questa metrica sono normali e in genere non rappresentano un problema con il cluster. Per un migliore indicatore dei potenziali problemi di prestazioni e stabilità, vedere la metrica Statistiche di nodo rilevanti: Minima, Massima, Media Statistiche del cluster rilevanti: Minima, Massima, Media |
JVMGCYoungCollectionCount |
Il numero di volte in cui è stata eseguita la garbage collection di "nuova generazione". Un numero elevato e in continua crescita di esecuzioni è una parte normale delle operazioni del cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
JVMGCYoungCollectionTime |
La quantità di tempo, in millisecondi, che il cluster ha impiegato per eseguire la garbage collection di "nuova generazione". Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
JVMGCOldCollectionCount |
Il numero di volte in cui è stata eseguita la garbage collection "vecchia generazione". In un cluster con risorse sufficienti, questo numero deve rimanere basso e senza frequenti incrementi. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
JVMGCOldCollectionTime |
La quantità di tempo, in millisecondi, che il cluster ha impiegato per eseguire la garbage collection "vecchia generazione". Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
OpenSearchDashboardsConcurrentConnections |
Il numero di connessioni simultanee attive alle dashboard. OpenSearch Se questo numero cresce costantemente, valutare la possibilità di dimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
OpenSearchDashboardsHealthyNode |
Un controllo di integrità per il singolo nodo OpenSearch Dashboards. Un valore pari a 1 indica un comportamento normale. Un valore pari a 0 indica che Dashboards non è accessibile. Statistiche nodo rilevanti: Minima Statistiche del cluster rilevanti: Minima, Massima, Media |
OpenSearchDashboardsHeapTotal |
La quantità di memoria heap allocata alle OpenSearch dashboard in MiB. Diversi tipi di istanza EC2 possono influire sull'esatta allocazione della memoria. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
OpenSearchDashboardsHeapUsed |
La quantità assoluta di memoria heap utilizzata dai OpenSearch dashboard in MiB. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
OpenSearchDashboardsHeapUtilization |
La percentuale massima di memoria heap disponibile utilizzata dai dashboard. OpenSearch Se questo valore supera l'80%, valutare la possibilità di dimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Minima, Massima, Media |
OpenSearchDashboardsOS1MinuteLoad |
La media di carico della CPU in un minuto per le dashboard. OpenSearch Il carico della CPU dovrebbe idealmente rimanere al di sotto di 1. Mentre i picchi temporanei vanno bene, se questo parametro è costantemente superiore a 1 si consiglia di aumentare la dimensione del tipo di istanza. Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
OpenSearchDashboardsRequestTotal |
Il numero totale di richieste HTTP inviate alle OpenSearch dashboard. Se il sistema è lento o viene visualizzato un numero elevato di richieste Dashboards, è consigliabile aumentare le dimensioni del tipo di istanza. Statistiche del nodo rilevanti: Somma Statistiche del cluster rilevanti: Somma |
OpenSearchDashboardsResponseTimesMaxInMillis |
Il tempo massimo, in millisecondi, impiegato dai OpenSearch dashboard per rispondere a una richiesta. Se le richieste richiedono molto tempo per restituire i risultati, è consigliabile aumentare le dimensioni del tipo di istanza. Statistiche di nodo rilevanti: Massima Statistiche cluster rilevanti: Massima, Media |
SearchTaskCancelled |
Il numero di cancellazioni del nodo coordinatore. Statistiche del nodo rilevanti: Somma Statistiche del cluster rilevanti: Somma |
SearchShardTaskCancelled |
Il numero di cancellazioni dei nodi dati. Statistiche del nodo rilevanti: Somma Statistiche pertinenti sui cluster: somma, |
ThreadpoolForce_mergeQueue |
Il numero di attività in coda nel pool di thread forza unione. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
ThreadpoolForce_mergeRejected |
Il numero di attività rifiutate nel pool di thread forza unione. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
ThreadpoolForce_mergeThreads |
Le dimensioni del pool di thread forza unione. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolIndexQueue |
Il numero di attività in coda nel pool di thread di indice. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. La dimensione massima della coda dell'indice è di 200. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
ThreadpoolIndexRejected |
Il numero di attività rifiutate nel pool di thread di indice. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
ThreadpoolIndexThreads |
Le dimensioni del pool di thread di indice. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolSearchQueue |
Il numero di attività in coda nel pool di thread di ricerca. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. La dimensione massima della coda di ricerca è di 1.000. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
ThreadpoolSearchRejected |
Il numero di attività rifiutate nel pool di thread di ricerca. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
ThreadpoolSearchThreads |
Le dimensioni del pool di thread di ricerca. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
Threadpoolsql-workerQueue |
Il numero di attività in coda nel pool di thread di ricerca SQL. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
Threadpoolsql-workerRejected |
Il numero di attività rifiutate nel pool di thread di ricerca SQL. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
Threadpoolsql-workerThreads |
Le dimensioni del pool di thread di ricerca SQL. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolBulkQueue |
Il numero di attività in coda nel pool di thread blocco. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
ThreadpoolBulkRejected |
Il numero di attività rifiutate nel pool di thread blocco. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
ThreadpoolBulkThreads |
Le dimensioni del pool di thread blocco. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolIndexSearcherQueue |
Il numero di attività in coda nel pool di thread di Index Searcher. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
ThreadpoolIndexSearcherRejected |
Il numero di attività rifiutate nel pool di thread di index searcher. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
ThreadpoolIndexSearcherThreads |
La dimensione del pool di thread di Index Searcher. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolWriteThreads |
La dimensione del pool di thread di scrittura. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolWriteQueue |
Il numero di attività in coda nel pool di thread di scrittura. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
ThreadpoolWriteRejected |
Il numero di attività rifiutate nel pool di thread di scrittura. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma NotaPoiché la dimensione predefinita della coda di scrittura è stata aumentata da 200 a 10000 nella versione 7.1, questa metrica non è più l'unico indicatore dei rifiuti da parte del Servizio. OpenSearch Utilizzare i parametri |
CoordinatingWriteRejected |
Il numero totale di rifiuti si è verificato sul nodo di coordinamento a causa della pressione di indicizzazione dall'ultimo avvio del processo di servizio. OpenSearch Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
PrimaryWriteRejected |
Il numero totale di rifiuti si è verificato sugli shard primari a causa della pressione di indicizzazione dall'ultimo avvio del processo di servizio. OpenSearch Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
ReplicaWriteRejected |
Il numero totale di rifiuti si è verificato sugli shard di replica a causa della pressione di indicizzazione dall'ultimo avvio del processo di servizio. OpenSearch Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
WorkloadManagementEnabled |
Indica se la funzionalità di gestione del carico di lavoro è abilitata. Un valore pari a 1 indica che è abilitata e un valore pari a 0 indica che è attiva Statistiche relative ai nodi: massimo, minimo Statistiche del cluster rilevanti: Media, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
SoftQueryGroupCount |
Numero di gruppi di query in modalità soft nel dominio. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
EnforcedQueryGroupCount |
Numero di gruppi di query in modalità applicata nel dominio. Statistiche rilevanti sui nodi: media, massima Statistiche del cluster rilevanti: Media, Massima, Somma Questo parametro è disponibile nella versione 7.1 e nelle versioni successive. |
Metriche calde
Amazon OpenSearch Service fornisce le seguenti metriche per l'architettura Multi-tier di storage e UltraWarm
Nota
Le metriche relative all'indicizzazione a caldo sono applicabili solo all'architettura di storage Multi-tier
| Metrica | Description |
|---|---|
WarmIndexingLatency
|
La differenza nel tempo totale, in millisecondi, rilevata da tutte le operazioni di indicizzazione in un nodo caldo tra i minuti N e i minuti (). N-1 Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
WarmIndexingRate
|
Il numero di operazioni di indicizzazione a caldo al minuto. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
WarmThreadpoolIndexingQueue
|
Il numero di attività in coda nel pool di thread di indice. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. La dimensione massima della coda dell'indice è di 200. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Massima, Somma |
WarmThreadpoolIndexingRejected
|
Il numero di attività rifiutate nel pool di thread di indice. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
WarmThreadpoolIndexingThreads
|
Le dimensioni del pool di thread di indice. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
WarmCPUUtilization |
La percentuale di utilizzo della CPU per i nodi Warm nel cluster. Il numero massimo mostra il nodo con il più alto utilizzo della CPU. La media rappresenta tutti i nodi Warm del cluster. Questa metrica è disponibile anche per i singoli nodi Warm. Statistiche rilevanti: Maximum (Massimo), Average (Media) |
WarmFreeStorageSpace |
La quantità di spazio di archiviazione a caldo gratuito in MiB. Poiché Warm utilizza Amazon S3 anziché dischi collegati, Statistiche rilevanti: Sum (Somma) |
WarmSearchableDocuments |
Il numero totale di documenti disponibili per la ricerca tra tutti gli indici a caldo nel cluster. È necessario lasciare il periodo su un minuto per ottenere un valore preciso. Statistiche rilevanti: Sum (Somma) |
WarmSearchLatency
|
La differenza nel tempo totale, in millisecondi, rilevato da tutte le ricerche in un Warm tra il minuto N e il minuto (). N-1 Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima |
WarmSearchRate
|
Il numero totale di richieste di ricerca al minuto per tutti gli shard su un nodo Warm. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Media, Massima, Somma |
WarmStorageSpaceUtilization |
La quantità totale di spazio di archiviazione a caldo, in MiB, che sta utilizzando il cluster. Statistiche rilevanti: Massima |
HotStorageSpaceUtilization
|
La quantità totale di spazio di archiviazione ad accesso frequente utilizzata dal cluster. Statistiche rilevanti: Massima |
WarmSysMemoryUtilization |
La percentuale di memoria del nodo Warm utilizzata. Statistiche rilevanti: Massima |
HotToWarmMigrationQueueSize
|
Il numero di indici attualmente in attesa di migrazione dall'archiviazione ad accesso frequente a quella a caldo. Statistiche rilevanti: Massima |
WarmToHotMigrationQueueSize
|
Il numero di indici attualmente in attesa di migrazione dall'archiviazione a caldo a quella ad accesso frequente. Statistiche rilevanti: Massima |
HotToWarmMigrationFailureCount
|
Il numero totale di migrazioni da "ad accesso frequente" a "a caldo" non riuscite. Questa metrica è disponibile solo per i UltraWarm nodi. Statistiche rilevanti: Sum (Somma) |
HotToWarmMigrationForceMergeLatency
|
La latenza media della fase di unione forzata del processo di migrazione. Se questa fase richiede sempre troppo tempo, valuta la possibilità di aumentarla. Questa metrica è disponibile solo per UltraWarm i nodi. Statistiche rilevanti: Average (Media) |
HotToWarmMigrationSnapshotLatency
|
La latenza media della fase di snapshot del processo di migrazione. Se questa fase richiede troppo tempo, assicurarsi che le partizioni siano dimensionate e distribuite in modo appropriato in tutto il cluster. Questa metrica è disponibile solo per UltraWarm i nodi. Statistiche rilevanti: Average (Media) |
HotToWarmMigrationProcessingLatency
|
La latenza media delle migrazioni riuscite da "ad accesso frequente" a "a caldo", senza includere il tempo trascorso nella coda. Questo valore è la somma del tempo necessario per completare le fasi di unione forzata, snapshot e rilocazione delle partizioni del processo di migrazione. Questa metrica è disponibile solo per i UltraWarm nodi. Statistiche rilevanti: Average (Media) |
HotToWarmMigrationSuccessCount
|
Il numero totale di migrazioni riuscite da "ad accesso frequente" a "a caldo". Statistiche rilevanti: Sum (Somma) |
HotToWarmMigrationSuccessLatency
|
La latenza media delle migrazioni riuscite da "ad accesso frequente" a "a caldo", compreso il tempo trascorso nella coda. Statistiche rilevanti: Average (Media) |
WarmThreadpoolSearchThreads |
La dimensione del pool di thread di ricerca di Warm. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Media, Somma |
WarmThreadpoolSearchRejected |
Il numero di attività rifiutate nel pool di thread di ricerca di Warm. Se questo numero aumenta continuamente, valuta la possibilità di aggiungere altri nodi Warm. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
WarmThreadpoolSearchQueue |
Il numero di attività in coda nel pool di thread di ricerca di Warm. Se la dimensione della coda è costantemente elevata, valuta la possibilità di aggiungere altri nodi Warm. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per i nodi Warm. Statistiche rilevanti: Massima NotaLa logica di questo parametro è cambiata nel software del servizio R20220323. Per ulteriori informazioni, consulta le note di rilascio. |
WarmOldGenJVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per la «vecchia generazione» per nodo Warm. Statistiche rilevanti: Massima |
WarmJVMGCYoungCollectionCount |
Il numero di volte in cui la raccolta dei rifiuti delle «giovani generazioni» è stata eseguita sui nodi Warm. Un numero elevato e in continua crescita di esecuzioni è una parte normale delle operazioni del cluster. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmJVMGCYoungCollectionTime |
La quantità di tempo, in millisecondi, impiegata dal cluster per eseguire la raccolta dei rifiuti di «nuova generazione» sui nodi Warm. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmJVMGCOldCollectionCount |
Il numero di volte in cui la raccolta dei rifiuti di «vecchia generazione» è stata eseguita sui nodi Warm. In un cluster con risorse sufficienti, questo numero deve rimanere basso e senza frequenti incrementi. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmConcurrentSearchRate |
Il numero totale di richieste di ricerca che utilizzano la ricerca simultanea per segmenti al minuto per tutti gli shard su un nodo Warm. Una singola chiamata all'API Statistiche di nodo rilevanti: Media Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmConcurrentSearchLatency |
La differenza nel tempo totale, in millisecondi, impiegato da tutte le ricerche utilizzando la ricerca simultanea per segmenti in un nodo Warm tra il minuto N e il minuto (). N-1 Statistiche di nodo rilevanti: Media Statistiche cluster rilevanti: Massima, Media |
WarmThreadpoolIndexSearcherQueue |
Il numero di attività in coda nel pool di thread di Warm index searcher. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma, Massimo, Media |
WarmThreadpoolIndexSearcherRejected |
Il numero di attività rifiutate nel pool di thread di Warm index searcher. Statistiche di nodo rilevanti: Massima Statistiche del cluster rilevanti: Somma |
WarmThreadpoolIndexSearcherThreads |
La dimensione del pool di thread di Warm index searcher. Statistiche di nodo rilevanti: Massima Statistiche pertinenti sui cluster: somma, media |
Parametri di archiviazione a freddo
Amazon OpenSearch Service fornisce le seguenti metriche per la conservazione a freddo.
| Metrica | Description |
|---|---|
ColdStorageSpaceUtilization
|
La quantità totale di spazio di archiviazione a freddo, in MiB, utilizzato dal cluster. Statistiche rilevanti: Max (Massimo) |
ColdToWarmMigrationFailureCount |
Il numero totale di migrazioni da freddo a caldo non riuscite. Statistiche rilevanti: Sum (Somma) |
ColdToWarmMigrationLatency |
Il tempo necessario per completare le migrazioni da freddo a caldo riuscite. Statistiche rilevanti: Average (Media) |
ColdToWarmMigrationQueueSize |
Il numero di indici attualmente in attesa di migrazione dall'archiviazione a freddo a quella a caldo. Statistiche rilevanti: Massima |
ColdToWarmMigrationSuccessCount
|
Il numero totale di migrazioni da freddo a caldo riuscite. Statistiche rilevanti: Sum (Somma) |
WarmToColdMigrationFailureCount
|
Il numero totale di migrazioni da caldo a freddo non riuscite. Statistiche rilevanti: Sum (Somma) |
WarmToColdMigrationLatency |
Il tempo necessario per completare le migrazioni da caldo a freddo riuscite. Statistiche rilevanti: Average (Media) |
WarmToColdMigrationQueueSize |
Il numero di indici attualmente in attesa di migrazione dall'archiviazione a caldo a quella a freddo. Statistiche rilevanti: Massima |
WarmToColdMigrationSuccessCount |
Il numero totale di migrazioni da caldo a freddo riuscite. Statistiche rilevanti: Sum (Somma) |
OpenSearch Metriche relative alle istanze ottimizzate (OR1)
Amazon OpenSearch Service fornisce i seguenti parametri per le istanze OR1.
| Metrica | Description |
|---|---|
RemoteStorageUsedSpace
|
La quantità totale di spazio Amazon S3, in MiB, utilizzata dal cluster. Statistiche rilevanti: Sum (Somma) |
RemoteStorageWriteRejected |
Il numero totale di richieste rifiutate sugli shard primari a causa della pressione di storage e replica remoti. Viene calcolato a partire dall'ultimo avvio del processo OpenSearch di servizio. Statistiche rilevanti: Sum (Somma) |
ReplicationLagMaxTime |
La quantità di tempo, in millisecondi, in cui gli shard di replica restano indietro rispetto agli shard primari. Statistiche rilevanti: Massima |
Metriche ottimizzate del motore
Amazon OpenSearch Service fornisce le seguenti metriche per i domini che utilizzano il motore Optimized (analisi dei log). Per ulteriori informazioni, consulta Ottimizzato per l'analisi dei log.
| Parametro | Description |
|---|---|
NativeMemoryPressure |
La percentuale di memoria nativa (off-heap) in uso sul nodo. Questa metrica è analoga, Statistiche rilevanti: Massima |
NativeRuntimeResidentMemory |
La quantità di memoria residente, in byte, consumata dal motore di analisi nativo sul nodo. Applicabile ai nodi hot, warm e coordinator. Statistiche rilevanti: Maximum (Massimo), Average (Media) |
NativeSearchRuntimeCPUUtilization |
L'utilizzo della CPU, in percentuale, del motore di esecuzione delle DataFusion query sul nodo. Applicabile ai nodi hot, warm e coordinator. Statistiche rilevanti: Maximum (Massimo), Average (Media) |
ThreadpoolNativeSearchCPUQueue |
Il numero di attività in coda nel pool di thread della CPU di ricerca nativo. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. Applicabile ai nodi hot, warm e coordinator. Statistiche rilevanti: Massima |
ThreadpoolNativeSearchCPUThreads |
La dimensione del pool di thread della CPU di ricerca nativo. Applicabile ai nodi hot, warm e coordinator. Statistiche rilevanti: Massima |
Nota
Le seguenti metriche non si applicano ai domini ottimizzati perché i OpenSearch dashboard non sono disponibili:
OpenSearchDashboardsHealthyNodesOpensearchDashboardsReportingFailedRequestSysErrCountOpensearchDashboardsReportingFailedRequestUserErrCountOpensearchDashboardsReportingRequestCountOpensearchDashboardsReportingSuccessCount
Parametri di avvisi
Amazon OpenSearch Service fornisce le seguenti metriche per gli avvisi.
| Metrica | Description |
|---|---|
AlertingDegraded |
Il valore 1 indica che l'indice di allerta è rosso oppure uno o più nodi non sono pianificati. Un valore 0 indica un comportamento normale. Statistiche rilevanti: Massima |
AlertingIndexExists |
Un valore pari a 1 significa che l'indice Statistiche rilevanti: Massima |
AlertingIndexStatus.green |
La salute dell'indice. Un valore pari a 1 significa verde. Un valore pari a 0 significa che l'indice non esiste o non è verde. Statistiche rilevanti: Massima |
AlertingIndexStatus.red |
La salute dell'indice. Un valore pari a 1 significa rosso. Un valore pari a 0 significa che l'indice non esiste o non è rosso. Statistiche rilevanti: Massima |
AlertingIndexStatus.yellow |
La salute dell'indice. Un valore pari a 1 significa giallo. Un valore pari a 0 significa che l'indice non esiste o non è giallo. Statistiche rilevanti: Massima |
AlertingNodesNotOnSchedule |
Il valore 1 indica che alcuni processi non sono in esecuzione nei tempi previsti. Il valore 0 indica che tutti i processi di allerta sono in esecuzione nella pianificazione (o che non esistono processi di avvisi). Controlla la console OpenSearch di servizio o fai una Statistiche rilevanti: Massima |
AlertingNodesOnSchedule |
Il valore 1 indica che tutti i processi di allerta sono in esecuzione nella pianificazione (o che non esistono processi di avvisi). Un valore pari a 0 indica che alcuni processi non sono in esecuzione nella pianificazione. Statistiche rilevanti: Massima |
AlertingScheduledJobEnabled |
Il valore 1 indica che l'impostazione del cluster Statistiche rilevanti: Massima |
Parametri di rilevamento delle anomalie
Amazon OpenSearch Service fornisce le seguenti metriche per il rilevamento delle anomalie.
| Metrica | Description |
|---|---|
ADPluginUnhealthy |
Il valore 1 indica che il plug-in di rilevamento delle anomalie non funziona correttamente, a causa di un numero elevato di errori o perché uno degli indici utilizzati è rosso. Il valore 0 indica che il plugin funziona come previsto. Statistiche rilevanti: Massima |
ADExecuteRequestCount |
Numero di richieste per il rilevamento delle anomalie. Statistiche rilevanti: Sum (Somma) |
ADExecuteFailureCount
|
Numero di richieste non riuscite per il rilevamento delle anomalie. Statistiche rilevanti: Sum (Somma) |
ADHCExecuteFailureCount |
Il numero di richieste non riuscite per il rilevamento delle anomalie per i rilevatori ad alta cardinalità. Statistiche rilevanti: Sum (Somma) |
ADHCExecuteRequestCount |
Il numero di richieste per il rilevamento delle anomalie per i rilevatori ad alta cardinalità. Statistiche rilevanti: Sum (Somma) |
ADAnomalyResultsIndexStatusIndexExists |
Il valore 1 indica che l'indice a cui punta l'alias Statistiche rilevanti: Massima |
ADAnomalyResultsIndexStatus.red |
Il valore 1 indica che l'indice a cui punta l'alias Statistiche rilevanti: Massima |
ADAnomalyDetectorsIndexStatusIndexExists |
Un valore pari a 1 significa che l'indice Statistiche rilevanti: Massima |
ADAnomalyDetectorsIndexStatus.red |
Un valore pari a 1 indica che l'indice Statistiche rilevanti: Massima |
ADModelsCheckpointIndexStatusIndexExists |
Un valore pari a 1 significa che l'indice Statistiche rilevanti: Massima |
ADModelsCheckpointIndexStatus.red |
Un valore pari a 1 indica che l'indice Statistiche rilevanti: Massima |
Parametri di ricerca asincrona
Amazon OpenSearch Service fornisce le seguenti metriche per la ricerca asincrona.
Statistiche del nodo coordinatore di ricerca asincrona (per nodo coordinatore)
| Metrica | Description |
|---|---|
AsynchronousSearchSubmissionRate |
Il numero di ricerche asincrone inviate nell'ultimo minuto. |
AsynchronousSearchInitializedRate |
Il numero di ricerche asincrone inizializzate nell'ultimo minuto. |
AsynchronousSearchRunningCurrent |
Il numero di ricerche asincrone correntemente in esecuzione. |
AsynchronousSearchCompletionRate |
Il numero di ricerche asincrone completate correttamente nell'ultimo minuto. |
AsynchronousSearchFailureRate |
Il numero di ricerche asincrone completate e non riuscite nell'ultimo minuto. |
AsynchronousSearchPersistRate |
Il numero di ricerche asincrone conservate nell'ultimo minuto. |
AsynchronousSearchPersistFailedRate |
Il numero di ricerche asincrone che non sono state conservate nell'ultimo minuto. |
AsynchronousSearchRejected |
Il numero totale di ricerche asincrone rifiutate dall'attivazione del nodo. |
AsynchronousSearchCancelled |
Il numero totale di ricerche asincrone cancellate dall'attivazione del nodo. |
AsynchronousSearchMaxRunningTime |
La durata della ricerca asincrona più lunga in esecuzione su un nodo nell'ultimo minuto. |
Statistiche del cluster di ricerca asincrona
| Metrica | Description |
|---|---|
AsynchronousSearchStoreHealth |
Lo stato del negozio nell'indice persistente (RED/non-RED) nell'ultimo minuto. |
AsynchronousSearchStoreSize |
La dimensione dell'indice di sistema su tutte le partizioni nell'ultimo minuto. |
AsynchronousSearchStoredResponseCount |
Il numero di risposte memorizzate nell'indice di sistema nell'ultimo minuto. |
Auto-Tune metriche
Amazon OpenSearch Service fornisce le seguenti metriche per Auto-Tune.
| Metrica | Description |
|---|---|
AutoTuneChangesHistoryHeapSize |
La cronologia delle modifiche in MiB per i valori di ottimizzazione delle dimensioni dell'heap. |
AutoTuneChangesHistoryJVMYoungGenArgs |
La cronologia delle modifiche per gli argomenti JVM. YongGen |
AutoTuneFailed |
Un valore booleano che indica se la modifica non è riuscita. Auto-Tune |
AutoTuneSucceeded |
Un valore booleano che indica se la modifica è riuscita. Auto-Tune |
AutoTuneValue |
La cronologia delle modifiche alla coda (count) e le ottimizzazioni della cache modificano la cronologia (in MiB) per modifiche senza interruzioni. |
Multi-AZ con metriche Standby
Amazon OpenSearch Service fornisce le seguenti metriche per Multi-AZ Standby.
Node-level metriche per i nodi di dati nelle zone di disponibilità attive
| Metrica | Description |
|---|---|
CPUUtilization |
Percentuale di utilizzo della CPU per i nodi di dati nel cluster. Il numero massimo mostra il nodo con il più alto utilizzo della CPU. La media rappresenta tutti i nodi del cluster. Questo parametro è disponibile anche per singoli nodi. |
FreeStorageSpace |
Lo spazio libero per i nodi di dati nel cluster. La console OpenSearch di servizio visualizza questo valore in GiB. La CloudWatch console Amazon lo visualizza in MiB. |
JVMMemoryPressure |
La percentuale massima dell'heap Java utilizzata per tutti i nodi di dati del cluster. OpenSearch Il servizio utilizza metà della RAM di un'istanza per l'heap Java, fino a una dimensione dell'heap di 32 GiB. Puoi scalare le istanze verticalmente fino a 64 GiB di RAM e poi scalare orizzontalmente aggiungendo le istanze. Per informazioni, consulta CloudWatch Allarmi consigliati per Amazon Service OpenSearch. |
SysMemoryUtilization |
La percentuale di memoria dell'istanza utilizzata. I valori elevati per questa metrica sono normali e in genere non rappresentano un problema con il cluster. Per un migliore indicatore dei potenziali problemi di prestazioni e stabilità, vedere la metrica JVMMemoryPressure. |
IndexingLatency |
La differenza nel tempo totale, in millisecondi, rilevata da tutte le operazioni di indicizzazione in un nodo tra i minuti N e i minuti (). N-1 |
IndexingRate |
Il numero di operazioni di indicizzazione al minuto. |
SearchLatency |
La differenza nel tempo totale, in millisecondi, rilevato da tutte le ricerche in un nodo tra il minuto N e il minuto (). N-1 |
SearchRate |
Il numero totale di richieste di ricerca al minuto per tutte le partizioni in un nodo di dati. |
ThreadpoolSearchQueue |
Il numero di attività in coda nel pool di thread di ricerca. Se la dimensione della coda è costantemente elevata, valutare la possibilità di ridimensionare il cluster. La dimensione massima della coda di ricerca è di 1.000. |
ThreadpoolWriteQueue |
Il numero di attività in coda nel pool di thread di scrittura. |
ThreadpoolSearchRejected |
Il numero di attività rifiutate nel pool di thread di ricerca. Se questo numero cresce costantemente, valutare la possibilità di ridimensionare il cluster. |
ThreadpoolWriteRejected |
Il numero di attività rifiutate nel pool di thread di scrittura. |
Cluster-level metriche per i cluster nelle zone di disponibilità attive
| Metrica | Description |
|---|---|
DataNodes |
Il numero totale di shard attivi e in standby. |
DataNodesShards.active |
Il numero totale di partizioni primarie e di replica attive. |
DataNodesShards.unassigned |
Il numero di partizioni non allocate ai nodi nel cluster. |
DataNodesShards.initializing |
Il numero di partizioni in fase di inizializzazione. |
DataNodesShards.relocating |
Il numero di partizioni in fase di rilocazione. |
Metriche di rotazione della zona di disponibilità
SeActiveReads., allora la zona è attiva. SeAvailability-Zone = 1ActiveReads., allora la zona è in standby.Availability-Zone =
0
Metriche puntuali
Amazon OpenSearch Service fornisce le seguenti metriche per le ricerche point-in-time (PIT).
Statistiche sul nodo coordinatore PIT (per nodo coordinatore)
| Metrica | Description |
|---|---|
CurrentPointInTime |
Il numero di contesti di ricerca PIT attivi nel nodo. |
TotalPointInTime |
Il numero di contesti di ricerca PIT scaduti dal momento dell'attività del nodo. |
AvgPointInTimeAliveTime |
Il mantenimento medio dei contesti di ricerca PIT dal momento in cui il nodo è attivo. |
HasActivePointInTime |
Il valore 1 indica che ci sono contesti PIT attivi sui nodi sin dal momento in cui il nodo è attivo. Un valore pari a 0 significa che non ce ne sono. |
HasUsedPointInTime |
Il valore 1 indica che ci sono contesti PIT scaduti sui nodi dal momento in cui il nodo è attivo. Un valore pari a 0 significa che non ce ne sono. |
Parametri SQL
Amazon OpenSearch Service fornisce le seguenti metriche per il supporto SQL.
| Metrica | Description |
|---|---|
SQLFailedRequestCountByCusErr |
Numero di richieste all'API Statistiche rilevanti: Sum (Somma) |
SQLFailedRequestCountBySysErr |
Numero di richieste all'API Statistiche rilevanti: Sum (Somma) |
SQLRequestCount |
Il numero di richieste all'API Statistiche rilevanti: Sum (Somma) |
SQLDefaultCursorRequestCount |
Simile a Statistiche rilevanti: Sum (Somma) |
SQLUnhealthy |
Un valore pari a 1 indica che, in risposta a determinate richieste, il plugin SQL restituisce 5 codici di rispostaxx o passa query DSL non valida a OpenSearch. Altre richieste dovrebbero continuare ad avere esito positivo. Un valore pari a 0 indica nessun errore recente. Se viene visualizzato un valore sostenuto pari a 1, risolvere i problemi relativi alle richieste che i client stanno facendo al plugin. Statistiche rilevanti: Massima |
Parametri k-NN
Amazon OpenSearch Service include le seguenti metriche per il plugin k-Nearest Neighbor (k-NN).
| Metrica | Description |
|---|---|
KNNCacheCapacityReached |
Per-node metrica che indica se è stata raggiunta la capacità della cache. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Massima |
KNNCircuitBreakerTriggered |
Per-cluster metrica che indica se l'interruttore è attivato. Se alcuni nodi restituiscono un valore pari a 1 per Statistiche rilevanti: Massima |
KNNEvictionCount |
Per-node metrica per il numero di grafici che sono stati rimossi dalla cache a causa di vincoli di memoria o tempi di inattività. Le rimozioni esplicite che si verificano a causa dell'eliminazione dell'indice non vengono conteggiate. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
KNNGraphIndexErrors |
Per-node metrica per il numero di richieste di aggiunta del Statistiche rilevanti: Sum (Somma) |
KNNGraphIndexRequests |
Per-node metrica per il numero di richieste per aggiungere il Statistiche rilevanti: Sum (Somma) |
KNNGraphMemoryUsage |
Per-node metrica per la dimensione corrente della cache (dimensione totale di tutti i grafici in memoria) in kilobyte. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Average (Media) |
KNNGraphMemoryUsagePercentage |
Per-node metrica per la percentuale di memoria nativa utilizzata per i grafici k-NN rispetto al limite dell'interruttore automatico (). Statistiche rilevanti: Massima |
KNNGraphQueryErrors |
Per-node metrica per il numero di interrogazioni grafiche che hanno prodotto un errore. Statistiche rilevanti: Sum (Somma) |
KNNGraphQueryRequests |
Per-node metrica per il numero di interrogazioni grafiche. Statistiche rilevanti: Sum (Somma) |
KNNHitCount |
Per-node metrica per il numero di accessi alla cache. Una occorrenza della cache si verifica quando un utente esegue una query su un grafico già caricato in memoria. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
KNNLoadExceptionCount |
Per-node metrica per il numero di volte in cui si è verificata un'eccezione durante il tentativo di caricare un grafico nella cache. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
KNNLoadSuccessCount |
Per-node metrica per il numero di volte in cui il plugin ha caricato con successo un grafico nella cache. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
KNNMissCount |
Per-node metrica per il numero di errori nella cache. Un mancato riscontro nella cache si verifica quando un utente esegue una query su un grafico non ancora caricato in memoria. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
KNNQueryRequests |
Per-node metrica per il numero di richieste di query ricevute dal plugin k-NN. Statistiche rilevanti: Sum (Somma) |
KNNRemoteBuildEnabled |
Valore binario che specifica se la funzionalità è abilitata. Statistiche pertinenti: binario |
KNNRemoteIndexBuildFailureCount |
Numero totale di errori di compilazione. Statistiche rilevanti: Sum (Somma) |
KNNRemoteIndexBuildSuccessCount |
Numero totale di build riuscite. Statistiche rilevanti: Sum (Somma) |
KNNScriptCompilationErrors |
Per-node metrica per il numero di errori durante la compilazione dello script. Questa statistica è rilevante solo per la ricerca di script di punteggio k-NN. Statistiche rilevanti: Sum (Somma) |
KNNScriptCompilations |
Per-node metrica per il numero di volte in cui lo script k-NN è stato compilato. Questo valore dovrebbe in genere essere 1 o 0, ma se la cache contenente gli script compilati viene riempita, lo script k-NN potrebbe essere ricompilato. Questa statistica è rilevante solo per la ricerca di script di punteggio k-NN. Statistiche rilevanti: Sum (Somma) |
KNNScriptQueryErrors |
Per-node metrica per il numero di errori durante le interrogazioni degli script. Questa statistica è rilevante solo per la ricerca di script di punteggio k-NN. Statistiche rilevanti: Sum (Somma) |
KNNScriptQueryRequests |
Per-node metrica per il numero totale di query di script. Questa statistica è rilevante solo per la ricerca di script di punteggio k-NN. Statistiche rilevanti: Sum (Somma) |
KNNTotalLoadTime |
Il tempo in nanosecondi impiegato da k-NN per caricare i grafici nella cache. Questo parametro è rilevante solo per approssimare la ricerca k-NN. Statistiche rilevanti: Sum (Somma) |
VectorIndexBuildAccelerationOCU |
Il numero di unità di OpenSearch calcolo (OCU) utilizzate per accelerare l'indicizzazione vettoriale. Statistiche rilevanti: Sum (Somma) |
Cross-cluster metriche di ricerca
Amazon OpenSearch Service fornisce le seguenti metriche per la ricerca tra cluster.
Parametri del dominio di origine
| Metrica | Dimensione | Description |
|---|---|---|
CrossClusterOutboundConnections |
|
Numero di nodi connessi. Se la risposta include uno o più domini ignorati, utilizzare questo parametro per tracciare eventuali connessioni non integre. Se questo numero scende a 0, la connessione non è integra. |
CrossClusterOutboundRequests |
|
Numero di richieste di ricerca inviate al dominio di destinazione. Utilizzalo per verificare se il carico di richieste di ricerca tra cluster sta sovraccaricando il tuo dominio, e metti in correlazione qualsiasi picco di questa metrica con qualsiasi picco. JVM/CPU |
Parametri del dominio di destinazione
| Metrica | Dimensione | Description |
|---|---|---|
CrossClusterInboundRequests |
|
Numero di richieste di connessione in ingresso ricevute dal dominio di origine. |
Aggiungi un CloudWatch allarme nel caso in cui perdi una connessione in modo imprevisto. Per i passaggi per creare un allarme, vedi Creare un CloudWatch allarme basato su una soglia statica.
Cross-cluster metriche di replica
Amazon OpenSearch Service fornisce le seguenti metriche per la replica tra cluster.
| Metrica | Description |
|---|---|
ReplicationRate |
La percentuale media di operazioni di replica al secondo. Questo parametro è analogo al parametro |
LeaderCheckPoint |
Per una connessione specifica, la somma dei valori del checkpoint leader in tutti gli indici di replica. Puoi utilizzare questo parametro per misurare la latenza di replica. |
FollowerCheckPoint |
Per una connessione specifica, la somma dei valori del checkpoint follower in tutti gli indici di replica. Puoi utilizzare questo parametro per misurare la latenza di replica. |
ReplicationNumSyncingIndices |
Il numero di indici con uno stato di replica di |
ReplicationNumBootstrappingIndices |
Il numero di indici con uno stato di replica di |
ReplicationNumPausedIndices |
Il numero di indici con uno stato di replica di |
ReplicationNumFailedIndices |
Il numero di indici con uno stato di replica di |
|
|
Il numero di richieste di trasporto di replica sul dominio del follower. Le richieste di trasporto sono interne e si verificano ogni volta che viene chiamata un'operazione API di replica. Si verificano anche quando il polling del dominio follower cambia rispetto al dominio leader. |
|
|
Il numero di richieste di trasporto di replica sul dominio leader. Le richieste di trasporto sono interne e si verificano ogni volta che viene chiamata un'operazione API di replica. |
AutoFollowNumSuccessStartReplication |
Il numero di indici follower creati correttamente da una regola di replica per una connessione specifica. |
AutoFollowNumFailedStartReplication |
Il numero di indici follower che non sono stati creati da una regola di replica in presenza di un modello corrispondente. Questo problema potrebbe sorgere a causa di un problema di rete sul cluster remoto o di un problema di sicurezza (ad esempio, il ruolo associato non ha l'autorizzazione per avviare la replica). |
AutoFollowLeaderCallFailure |
Se ci sono state query non riuscite dall'indice follower all'indice leader per estrarre nuovi dati. Un valore pari a |
Parametri di Learning to Rank
Amazon OpenSearch Service fornisce le seguenti metriche per Learning to Rank.
| Metrica | Description |
|---|---|
LTRRequestTotalCount |
Conteggio totale delle richieste di classificazione. |
LTRRequestErrorCount |
Conteggio totale delle richieste non riuscite. |
LTRStatus.red |
Traccia se uno degli indici necessari per eseguire il plug-in è rosso. |
LTRMemoryUsage |
La memoria totale utilizzata dal plug-in. |
LTRFeatureMemoryUsageInBytes |
La quantità di memoria, espressa in byte, utilizzata dai campi della funzionalità Learning to Rank. |
LTRFeaturesetMemoryUsageInBytes |
La quantità di memoria, espressa in byte, utilizzata dai set di funzionalità Learning to Rank. |
LTRModelMemoryUsageInBytes |
La quantità di memoria, espressa in byte, utilizzata da tutti i modelli Learning to Rank. |
Parametri Piped Processing Language (PPL)
Amazon OpenSearch Service fornisce le seguenti metriche per Piped Processing Language.
| Metrica | Description |
|---|---|
PPLFailedRequestCountByCusErr |
Numero di richieste all'API |
PPLFailedRequestCountBySysErr |
Numero di richieste all'API |
PPLRequestCount |
Il numero di richieste all'API |
