Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS ParallelClusterprocessi
Questa sezione si applica solo ai cluster HPC che vengono distribuiti con uno dei pianificatori dei processi tradizionali supportati (SGE, Slurm o Torque). Se utilizzato con questi scheduler, AWS ParallelCluster gestisce il provisioning e la rimozione dei nodi di calcolo interagendo sia con il gruppo Auto Scaling che con il job scheduler sottostante.
Per i cluster HPC basati suAWS Batch, AWS ParallelCluster si basa sulle funzionalità fornite da AWS Batch per la gestione dei nodi di elaborazione.
Nota
A partire dalla versione 2.11.5, AWS ParallelCluster non supporta l'uso SGE o Torque gli scheduler. Puoi continuare a utilizzarli nelle versioni fino alla 2.11.4 inclusa, ma non sono idonei per aggiornamenti futuri o supporto per la risoluzione dei problemi da parte dei team di AWS assistenza e AWS supporto.
SGE and Torque integration processes
Nota
Questa sezione si applica solo alle AWS ParallelCluster versioni fino alla versione 2.11.4 inclusa. A partire dalla versione 2.11.5, AWS ParallelCluster non supporta l'uso SGE e Torque gli scheduler, Amazon SNS e Amazon SQS.
Panoramica generale
Il ciclo di vita di un cluster inizia dopo che è stato creato da un utente. Di solito, un cluster viene creato dall'interfaccia a riga di comando (CLI). Una volta creato, un cluster esiste finché non viene eliminato. I daemon AWS ParallelCluster vengono eseguiti sui nodi del cluster, principalmente per gestire l’elasticità del cluster HPC. Il seguente diagramma mostra un flusso di lavoro per un utente e il ciclo di vita del cluster. Le sezioni seguenti descrivono i daemon AWS ParallelCluster che vengono utilizzati per gestire il cluster.
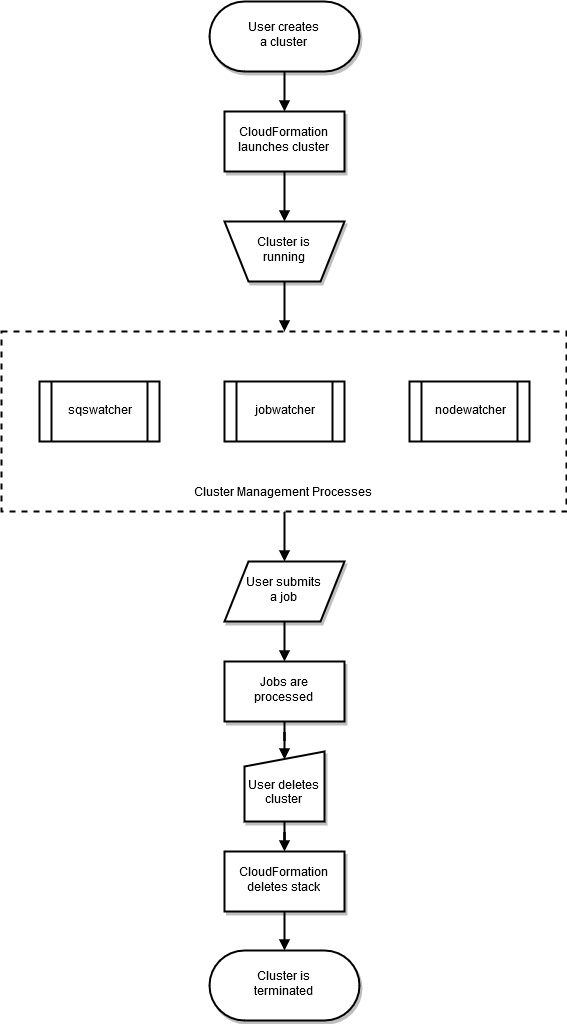
Con SGE e Torque pianificatori nodewatcherjobwatcher, AWS ParallelCluster usi e sqswatcher processi.
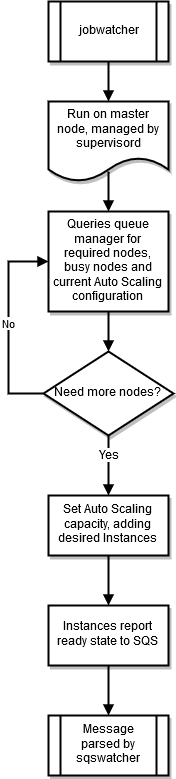
jobwatcher
Quando un cluster è in esecuzione, un processo di proprietà dell'utente root monitora lo scheduler (SGEo) configurato. Torque Ogni minuto valuta la coda per decidere quando aumentare la scala.
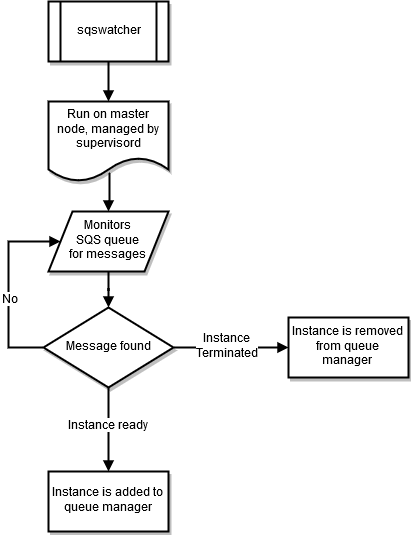
sqswatcher
Il sqswatcher processo monitora i messaggi Amazon SQS inviati da Auto Scaling per notificare i cambiamenti di stato all'interno del cluster. Quando un'istanza è online, invia un messaggio «Instance ready» ad Amazon SQS. Questo messaggio viene raccolto dasqs_watcher, in esecuzione sul nodo principale. Questi messaggi vengono utilizzati per segnalare al responsabile della coda quando nuove istanze sono online o vengono terminate, in modo che possano essere aggiunte o rimosse dalla coda.
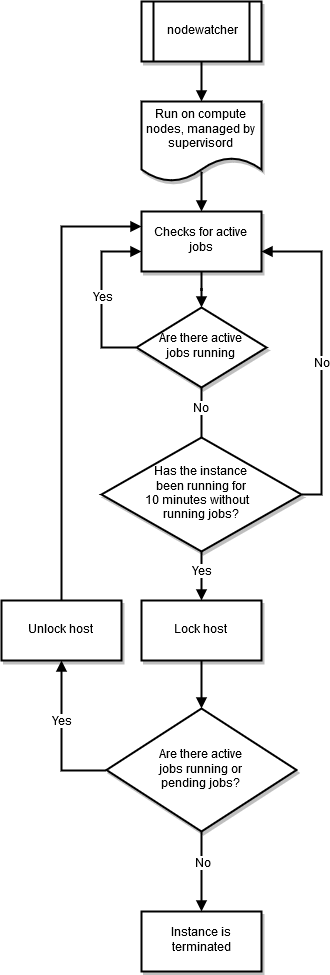
nodewatcher
Il processo nodewatcher viene eseguito su ogni nodo del parco istanze di calcolo. Dopo il periodo scaledown_idletime, come definito dall'utente, l'istanza viene terminata.
Slurm integration processes
Con Slurm pianificatori, AWS ParallelCluster usi clustermgtd e computemgt processi.
clustermgtd
I cluster eseguiti in modalità eterogenea (indicata specificando un queue_settings valore) dispongono di un processo daemon di gestione dei cluster (clustermgtd) che viene eseguito sul nodo principale. Queste attività vengono eseguite dal demone di gestione del cluster.
-
Pulizia delle partizioni inattive
-
Gestione della capacità statica: assicurati che la capacità statica sia sempre attiva e integra
-
Pianificatore di sincronizzazione con Amazon EC2.
-
Pulizia delle istanze orfane
-
Ripristina lo stato del nodo di pianificazione in caso di terminazione di Amazon EC2 che si verifica al di fuori del flusso di lavoro di sospensione
-
Gestione non corretta delle istanze Amazon EC2 (con esito negativo dei controlli di integrità di Amazon EC2)
-
Gestione degli eventi di manutenzione programmata
-
Gestione non integra dei nodi di Scheduler (con esito negativo dei controlli di integrità dello Scheduler)
computemgtd
I cluster che vengono eseguiti in modalità eterogenea (indicata specificando un queue_settings valore) dispongono di processi di elaborazione daemon (computemgtd) che vengono eseguiti su ciascun nodo di elaborazione. Ogni cinque (5) minuti, il demone di gestione dell'elaborazione conferma che il nodo principale è raggiungibile e che è integro. Se trascorrono cinque (5) minuti durante i quali il nodo principale non può essere raggiunto o non è integro, il nodo di elaborazione viene spento.
