Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scatter-gather modello
Intento
Il pattern scatter-collect è uno schema di routing dei messaggi che prevede la trasmissione di richieste simili o correlate a più destinatari e l'aggregazione delle relative risposte in un unico messaggio utilizzando un componente chiamato aggregatore. Questo modello consente di ottenere la parallelizzazione, riduce la latenza di elaborazione e gestisce la comunicazione asincrona. È semplice implementare il pattern scatter-collect utilizzando un approccio sincrono, ma un approccio più potente prevede l'implementazione come routing dei messaggi nelle comunicazioni asincrone, con o senza un servizio di messaggistica.
Motivazione
Nell'elaborazione delle applicazioni, una richiesta che potrebbe richiedere molto tempo per essere elaborata in sequenza può essere suddivisa in più richieste elaborate in parallelo. È inoltre possibile inviare richieste a più sistemi esterni tramite chiamate API per ottenere una risposta. Il pattern scatter-gather è utile quando è necessario un input da più fonti. Scatter-gather aggrega i risultati per aiutarti a prendere una decisione informata o per selezionare la risposta migliore per la richiesta.
Il pattern scatter-gather si compone di due fasi, come suggerisce il nome:
-
La fase di dispersione elabora il messaggio di richiesta e lo invia a più destinatari in parallelo. Durante questa fase, l'applicazione distribuisce le richieste in tutta la rete e continua a funzionare senza attendere risposte immediate.
-
Durante la fase di raccolta, l'applicazione raccoglie le risposte dai destinatari e le filtra o le combina in una risposta unificata. Una volta raccolte tutte le risposte, è possibile aggregarle in un'unica risposta oppure scegliere la migliore per un'ulteriore elaborazione.
Applicabilità
Usa lo schema scatter-gather quando:
-
Hai intenzione di aggregare e consolidare i dati provenienti da varie API per creare una risposta accurata. Il modello consolida le informazioni provenienti da fonti diverse in un insieme coeso. Ad esempio, un sistema di prenotazione può richiedere a più destinatari di ricevere preventivi da più partner esterni.
-
La stessa richiesta deve essere inviata a più destinatari contemporaneamente per completare una transazione. Ad esempio, puoi utilizzare questo modello per interrogare i dati di inventario in parallelo per verificare la disponibilità di un prodotto.
-
Desiderate implementare un sistema affidabile e scalabile in cui sia possibile ottenere il bilanciamento del carico distribuendo le richieste tra più destinatari. Se un destinatario fallisce o subisce un carico di lavoro elevato, gli altri destinatari possono comunque elaborare le richieste.
-
Desideri ottimizzare le prestazioni durante l'implementazione di query complesse che coinvolgono più fonti di dati. È possibile distribuire la query nei database pertinenti, raccogliere i risultati parziali e combinarli in una risposta completa.
-
Stai implementando un tipo di elaborazione map-reduce in cui la richiesta di dati viene indirizzata a più endpoint di elaborazione dei dati per lo sharding e la replica. I risultati parziali vengono filtrati e combinati per comporre la risposta corretta.
-
Desideri distribuire le operazioni di scrittura su uno spazio di chiavi di partizione in carichi di lavoro che richiedono molta scrittura nei database chiave-valore. L'aggregatore legge i risultati interrogando i dati in ogni shard e quindi li consolida in un'unica risposta.
Problemi e considerazioni
-
Tolleranza agli errori: questo modello si basa su più destinatari che lavorano in parallelo, quindi è essenziale gestire gli errori con garbo. Per mitigare l'impatto degli errori dei destinatari sull'intero sistema, è possibile implementare strategie come ridondanza, replica e rilevamento degli errori.
-
Scale-out limiti: all'aumentare del numero totale di nodi di elaborazione, aumenta anche il sovraccarico di rete associato. Ogni richiesta che implica la comunicazione sulla rete può aumentare la latenza e influire negativamente sui vantaggi della parallelizzazione.
-
Ostacoli nei tempi di risposta: per le operazioni che richiedono l'elaborazione di tutti i destinatari prima del completamento dell'elaborazione finale, le prestazioni dell'intero sistema sono limitate dal tempo di risposta del destinatario più lento.
-
Risposte parziali: quando le richieste vengono distribuite a più destinatari, alcuni destinatari possono scadere. In questi casi, l'implementazione dovrebbe comunicare al client che la risposta è incompleta. È inoltre possibile visualizzare i dettagli di aggregazione della risposta utilizzando un frontend dell'interfaccia utente.
-
Coerenza dei dati: quando si elaborano dati tra più destinatari, è necessario considerare attentamente le tecniche di sincronizzazione dei dati e di risoluzione dei conflitti, per garantire che i risultati aggregati finali siano accurati e coerenti.
Implementazione
High-level architettura
Il pattern scatter-gather utilizza un controller root per distribuire le richieste ai destinatari che le elaboreranno. Durante la fase di dispersione, questo pattern può utilizzare due meccanismi per inviare messaggi ai destinatari:
-
Scatter by distribution: l'applicazione dispone di un elenco noto di destinatari che devono essere chiamati per ottenere i risultati. I destinatari possono essere processi diversi con funzioni uniche o un singolo processo che è stato ridimensionato per distribuire il carico di elaborazione. Se uno dei nodi di elaborazione scade o mostra ritardi nella risposta, il controller può ridistribuire l'elaborazione su un altro nodo.
-
Scatter by auction: l'applicazione trasmette il messaggio ai destinatari interessati utilizzando uno schema di pubblicazione e sottoscrizione. In questo caso, i destinatari possono iscriversi al messaggio o recedere dall'abbonamento in qualsiasi momento.
Spargi per distribuzione
Nel metodo di distribuzione scatter by, il root controller divide la richiesta in entrata in attività indipendenti e le assegna ai destinatari disponibili (la fase di dispersione). Ogni destinatario (processo, contenitore o funzione Lambda) esegue il calcolo in modo indipendente e parallelo e produce una parte della risposta. Quando i destinatari completano le proprie attività, inviano le risposte a un aggregatore (la fase di raccolta). L'aggregatore combina le risposte parziali e restituisce il risultato finale al cliente. Il diagramma seguente illustra questo flusso di lavoro.
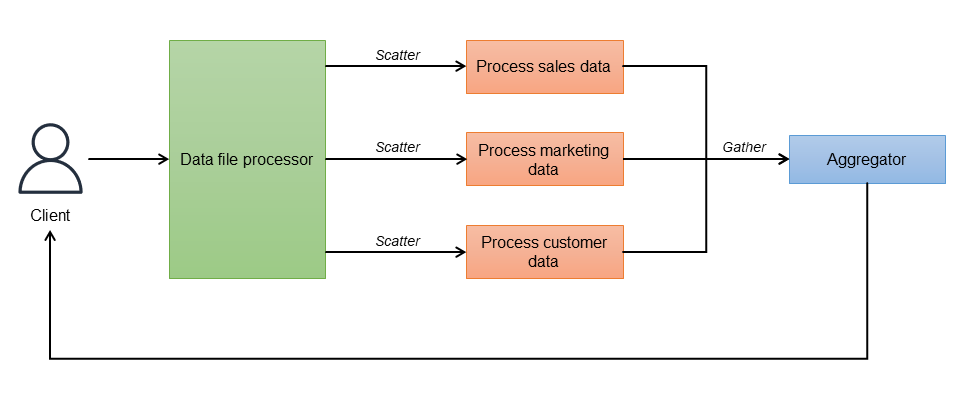
Il controller (elaboratore di file di dati) orchestra l'intero set di chiamate ed è a conoscenza di tutti gli endpoint di prenotazione da chiamare. Può configurare un parametro di timeout per ignorare le risposte che richiedono troppo tempo. Una volta inviate le richieste, l'aggregatore attende le risposte da ciascun endpoint. Per implementare la resilienza, ogni microservizio può essere distribuito con più istanze per il bilanciamento del carico. L'aggregatore ottiene i risultati, li combina in un unico messaggio di risposta e rimuove i dati duplicati prima dell'ulteriore elaborazione. Le risposte scadute vengono ignorate. Il controller può anche fungere da aggregatore anziché utilizzare un servizio di aggregazione separato.
Scatter per asta
Se il controllore non conosce i destinatari o se i destinatari sono associati in modo incerto, puoi utilizzare il metodo scatter by auction. In questo metodo, i destinatari sottoscrivono un argomento e il controller pubblica la richiesta sull'argomento. I destinatari pubblicano i risultati in una coda di risposta. Poiché il controller principale non conosce i destinatari, il processo di raccolta utilizza un aggregatore (un altro modello di messaggistica) per raccogliere le risposte e distillarle in un unico messaggio di risposta. L'aggregatore utilizza un ID univoco per identificare un gruppo di richieste.
Ad esempio, nel diagramma seguente, il metodo scatter by auction viene utilizzato per implementare un servizio di prenotazione di voli per il sito Web di una compagnia aerea. Il sito Web consente agli utenti di cercare e visualizzare voli del vettore della compagnia aerea e dei vettori dei suoi partner e deve visualizzare lo stato della ricerca in tempo reale. Il servizio di prenotazione voli è composto da tre microservizi di ricerca: voli diretti, voli con scali e compagnie aeree partner. La ricerca della compagnia aerea partner chiama gli endpoint API del partner per ottenere le risposte.
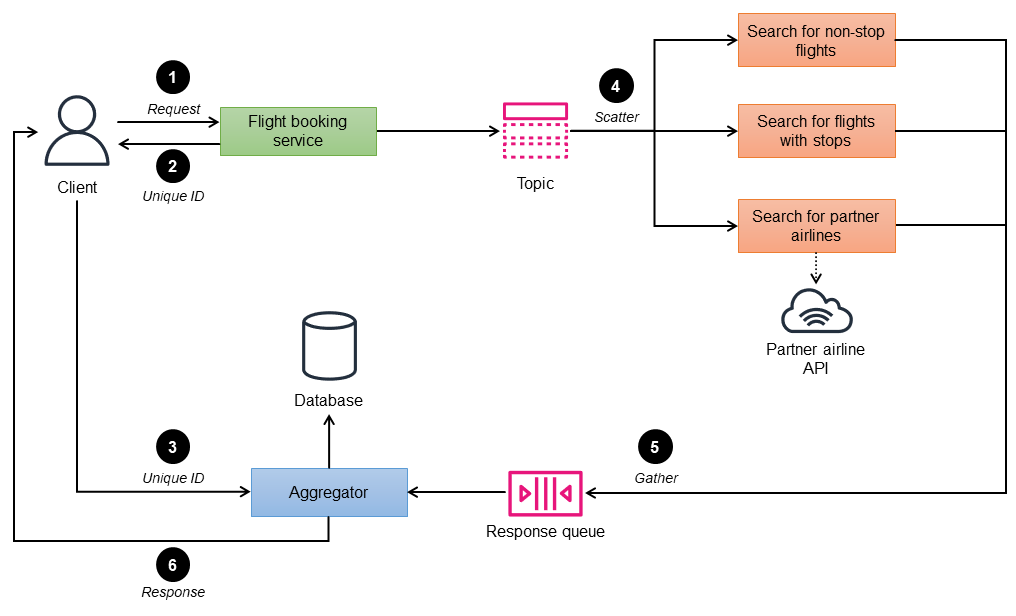
-
Il servizio di prenotazione dei voli (controller) accetta i criteri di ricerca inseriti dal cliente, elabora e pubblica la richiesta sull'argomento.
-
Il controller utilizza un ID univoco per identificare ogni gruppo di richieste.
-
Il client invia l'ID univoco all'aggregatore per la fase 6.
-
I microservizi di ricerca delle prenotazioni che hanno sottoscritto l'argomento di prenotazione ricevono la richiesta.
-
I microservizi elaborano la richiesta e restituiscono la disponibilità dei posti per i criteri di ricerca specificati in una coda di risposta.
-
L'aggregatore raccoglie tutti i messaggi di risposta archiviati in un database temporaneo, raggruppa i voli per ID univoco, crea un'unica risposta unificata e la rispedisce al client.
Implementazione utilizzando Servizi AWS
Dispersione per distribuzione
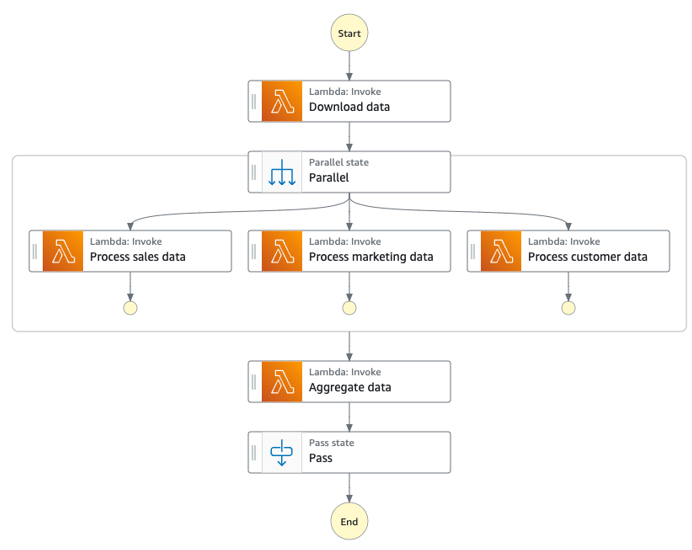
Nella seguente architettura, il root controller è un processore di file di dati (Amazon ECS) che suddivide i dati della richiesta in entrata in singoli bucket Amazon Simple Storage Service (Amazon S3) e avvia un flusso di lavoro. AWS Step Functions Il flusso di lavoro scarica i dati e avvia l'elaborazione parallela dei file. Lo Parallel stato attende che tutte le attività restituiscano una risposta. Una AWS Lambda funzione aggrega i dati e li salva su Amazon S3.
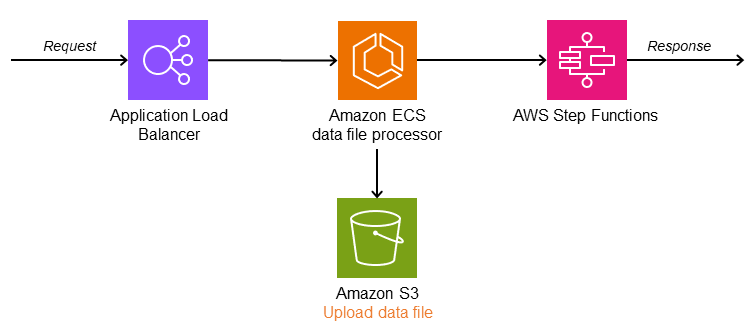
Il diagramma seguente illustra il flusso di lavoro Step Functions con lo Parallel stato.
Scatter per asta
Il diagramma seguente mostra un' AWS architettura per il metodo Scatter by auction. Il servizio di prenotazione dei voli root controller distribuisce la richiesta di ricerca del volo su più microservizi. Un canale di pubblicazione e iscrizione è implementato con Amazon Simple Notification Service (Amazon SNS), un servizio di messaggistica gestito per le comunicazioni. Amazon SNS supporta messaggi tra applicazioni di microservizi disaccoppiate o comunicazioni dirette con gli utenti. Puoi distribuire i microservizi del destinatario su Amazon Elastic Kubernetes Service (Amazon EKS) o Amazon Elastic Container Service (Amazon ECS) per una migliore gestione e scalabilità. Il servizio per i risultati dei voli restituisce i risultati al cliente. Può essere implementato in AWS Lambda o in altri servizi di orchestrazione di container come Amazon ECS o Amazon EKS.
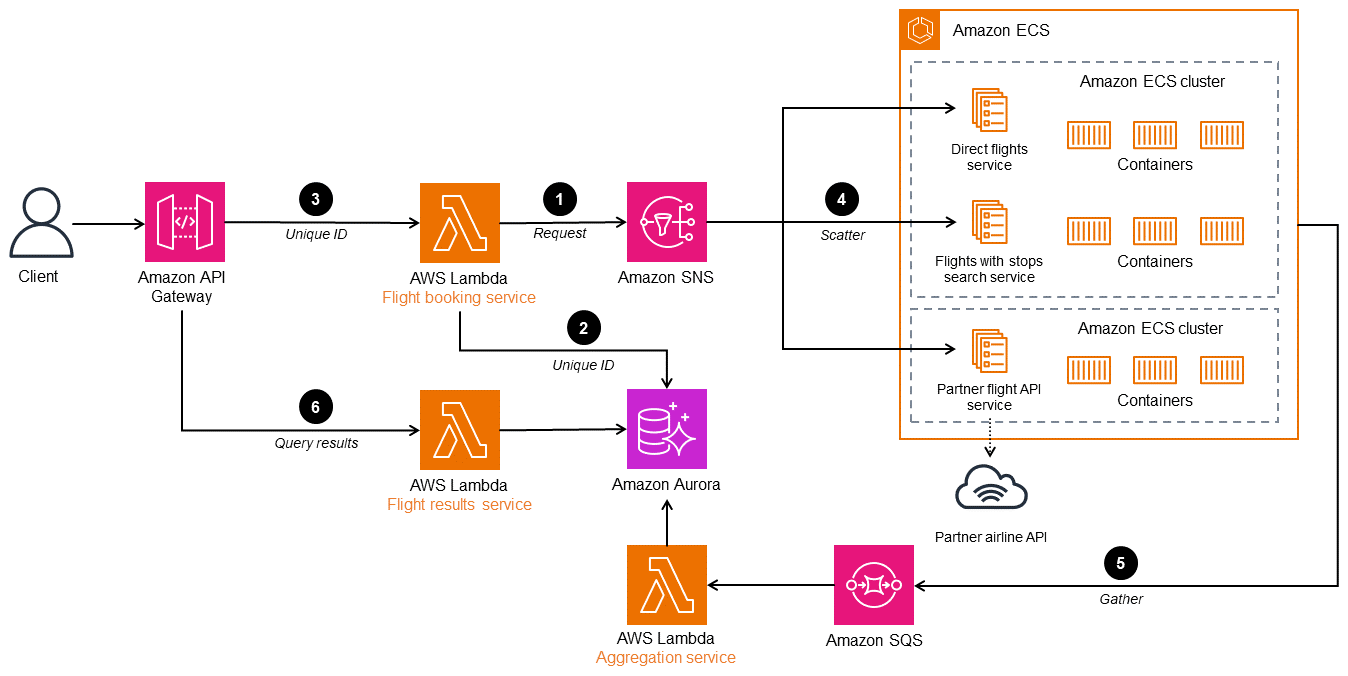
-
Il servizio di prenotazione dei voli (controller) accetta i criteri di ricerca come input dal cliente, elabora e pubblica la richiesta sull'argomento SNS.
-
Il controller pubblica l'ID univoco in un database Amazon Aurora per identificare la richiesta.
-
Il client invia l'ID univoco al client per la fase 6.
-
I microservizi di ricerca delle prenotazioni che hanno sottoscritto l'argomento di prenotazione ricevono la richiesta.
-
I microservizi elaborano la richiesta e restituiscono la disponibilità dei posti per i criteri di ricerca specificati in una coda di risposta in Amazon Simple Queue Service (Amazon SQS). L'aggregatore raccoglie tutti i messaggi di risposta e li archivia in un database temporaneo.
-
Il servizio di risultati dei voli raggruppa i voli in base a un ID univoco, crea un'unica risposta unificata e la rispedisce al cliente.
Se desideri aggiungere un'altra ricerca di compagnie aeree a questa architettura, aggiungi un microservizio che sottoscrive l'argomento SNS e pubblica nella coda SQS.
Riassumendo, il pattern scatter-collect consente ai sistemi distribuiti di ottenere una parallelizzazione efficiente, ridurre la latenza e gestire senza problemi le comunicazioni asincrone.
GitHub deposito
Per un'implementazione completa dell'architettura di esempio per questo modello, consulta il GitHub repository all'indirizzo. https://github.com/aws-samples/asynchronous-messaging-workshop/tree/master/code/lab-3
Workshop
-
Scatter-gather laboratorio
nel workshop Decoupled Microservices
Riferimenti del blog
Contenuti correlati
-
Publish-subscribemodello
