Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Database-per-service modello
L'accoppiamento libero è la caratteristica principale di un'architettura di microservizi, poiché ogni singolo microservizio può archiviare e recuperare informazioni in modo indipendente dal proprio archivio dati. Implementando il modello «database per servizio», è possibile scegliere gli archivi dati più appropriati (ad esempio database relazionali o non relazionali) per le applicazioni e i requisiti aziendali. Ciò significa che i microservizi non condividono un livello di dati, le modifiche al database individuale di un microservizio non influiscono sugli altri microservizi, i singoli archivi dati non sono accessibili direttamente da altri microservizi e i dati persistenti sono accessibili solo tramite API. Il disaccoppiamento degli archivi dati migliora anche la resilienza dell'intera applicazione e garantisce che un singolo database non possa essere un singolo punto di errore.
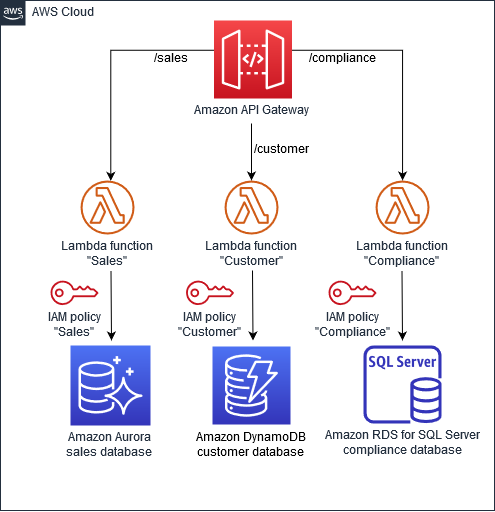
Nella figura seguente, i microservizi «Vendite», «Clienti» e «Conformità» utilizzano diversi AWS database. Questi microservizi vengono distribuiti come AWS Lambda funzioni e vi si accede tramite un'API Amazon API Gateway. AWS Identity and Access Management Le policy (IAM) garantiscono che i dati siano mantenuti privati e non condivisi tra i microservizi. Ogni microservizio utilizza un tipo di database che soddisfa i suoi requisiti individuali; ad esempio, «Sales» utilizza Amazon Aurora, «Customer» utilizza Amazon DynamoDB e «Compliance» utilizza Amazon Relational Database Service (Amazon RDS) per SQL Server.
Dovresti prendere in considerazione l'utilizzo di questo modello se:
-
È necessario un accoppiamento libero tra i microservizi.
-
I microservizi hanno requisiti di conformità o sicurezza diversi per i loro database.
-
È necessario un controllo più granulare della scalabilità.
L'utilizzo del modello database-per-service presenta i seguenti svantaggi:
-
Potrebbe essere difficile implementare transazioni e query complesse che si estendono su più microservizi o archivi di dati.
-
È necessario gestire più database relazionali e non relazionali.
-
I tuoi archivi dati devono soddisfare due dei requisiti del teorema CAP
: coerenza, disponibilità o tolleranza delle partizioni.
Nota
Se si utilizza il modello database per servizio, è necessario implementare un altro modello per implementare query che si estendono su più microservizi. È possibile utilizzare il pattern di sourcing degli Modello di composizione delle API eventi (che è possibile velocizzare conModello CQRS) o l'event sourcing per creare risultati aggregati.
