Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Sviluppa un assistente basato su chat completamente automatizzato utilizzando gli agenti e le knowledge base di Amazon Bedrock
Creato da Jundong Qiao (AWS), Kara Yang (), Kiowa Jackson (AWS), Noah Hamilton (), Praveen Kumar Jeyarajan (AWS) e Shuai Cao (AWS) AWS AWS
Riepilogo
Molte organizzazioni affrontano difficoltà quando creano un assistente basato su chat in grado di orchestrare diverse fonti di dati per offrire risposte complete. Questo modello presenta una soluzione per lo sviluppo di un assistente basato su chat in grado di rispondere alle domande provenienti sia dalla documentazione che dai database, con un'implementazione semplice.
A partire da Amazon Bedrock, questo servizio di intelligenza artificiale generativa (AI) completamente gestito offre un'ampia gamma di modelli di base avanzati (FMs). Ciò facilita la creazione efficiente di applicazioni di intelligenza artificiale generativa con una forte attenzione alla privacy e alla sicurezza. Nel contesto del recupero della documentazione, Retrieval Augmented Generation () è una funzionalità fondamentale. RAG Utilizza basi di conoscenza per ampliare i prompt FM con informazioni contestualmente rilevanti provenienti da fonti esterne. Un indice Amazon OpenSearch Serverless funge da database vettoriale alla base delle knowledge base per Amazon Bedrock. Questa integrazione è migliorata attraverso un'attenta progettazione tempestiva per ridurre al minimo le imprecisioni e garantire che le risposte siano ancorate a una documentazione fattuale. Per le query sui database, Amazon Bedrock trasforma le FMs richieste testuali in SQL query strutturate, incorporando parametri specifici. Ciò consente il recupero preciso dei dati dai database gestiti dai database AWSGlue. Amazon Athena viene utilizzato per queste query.
Per gestire interrogazioni più complesse, ottenere risposte complete richiede informazioni provenienti sia dalla documentazione che dai database. Agents for Amazon Bedrock è una funzionalità di intelligenza artificiale generativa che ti aiuta a creare agenti autonomi in grado di comprendere attività complesse e suddividerle in attività più semplici da orchestrare. La combinazione di informazioni ricavate dalle attività semplificate, facilitata dagli agenti autonomi di Amazon Bedrock, migliora la sintesi delle informazioni, portando a risposte più complete ed esaustive. Questo modello dimostra come creare un assistente basato su chat utilizzando Amazon Bedrock e i relativi servizi e funzionalità di intelligenza artificiale generativa all'interno di una soluzione automatizzata.
Prerequisiti e limitazioni
Prerequisiti
Un account attivo AWS
AWSCloud Development Kit (AWSCDK), installato e avviato nelle
us-east-1regioni ous-west-2AWSAWSInterfaccia a riga di comando (AWSCLI), installata e configurata
In Amazon Bedrock, abilita l'accesso a Claude 2, Claude 2.1, Claude Instant e Titan Embeddings G1 — Text
Limitazioni
Questa soluzione viene distribuita su un singolo account. AWS
Questa soluzione può essere implementata solo AWS nelle regioni in cui sono supportati Amazon Bedrock e Amazon OpenSearch Serverless. Per ulteriori informazioni, consulta la documentazione per Amazon Bedrock e Amazon OpenSearch Serverless.
Versioni del prodotto
Llama-index versione 0.10.6 o successiva
Sqlalchemy versione 2.0.23 o successiva
OpenSearch-PY versione 2.4.2 o successiva
Requests_AWS4Auth versione 1.2.3 o successiva
AWSSDKper Python (Boto3) versione 1.34.57 o successiva
Architettura
Stack tecnologico Target
Il AWSCloud Development Kit (AWSCDK) è un framework di sviluppo software open source per definire l'infrastruttura cloud nel codice e fornirla tramite AWS CloudFormation. Lo AWS CDK stack utilizzato in questo modello distribuisce le seguenti risorse: AWS
AWSServizio di gestione delle chiavi () AWS KMS
Amazon Simple Storage Service (Amazon S3)
AWSGlue Data Catalog, per il componente del database AWS Glue
AWS Lambda
AWSIdentity and Access Management (IAM)
Amazon OpenSearch Serverless
Registro Amazon Elastic Container (AmazonECR)
Amazon Elastic Container Service (AmazonECS)
AWS Fargate
Amazon Cloud Privato Virtuale (AmazonVPC)
Architettura Target
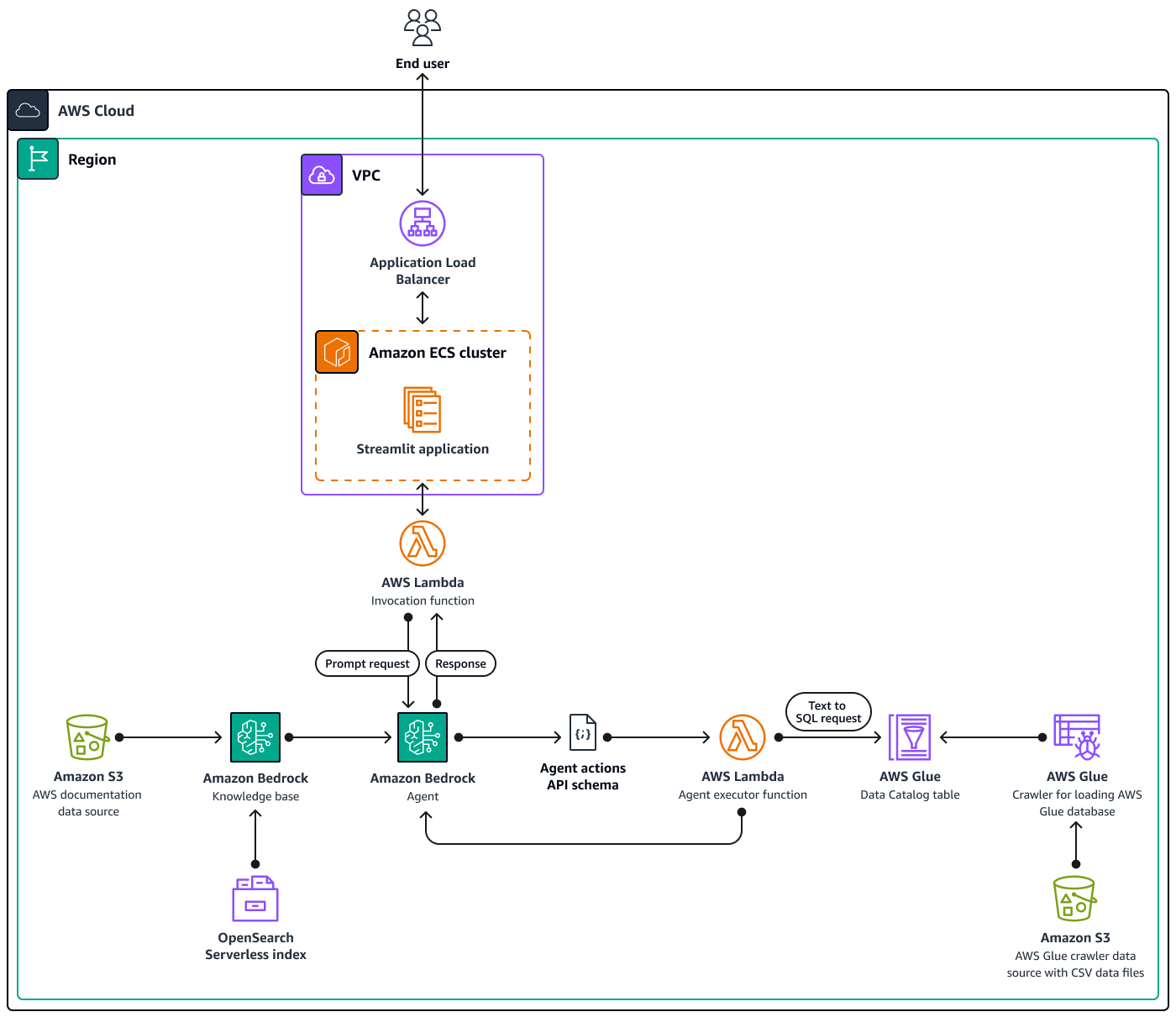
Il diagramma mostra una configurazione AWS nativa del cloud completa all'interno di una singola AWS regione, che utilizza più servizi. AWS L'interfaccia principale per l'assistente basato sulla chat è un'applicazione StreamlitInvocation Lambda, che si interfaccia quindi con gli agenti per Amazon Bedrock. Questo agente risponde alle richieste degli utenti consultando le knowledge base per Amazon Bedrock o richiamando una funzione Lambda. Agent executor Questa funzione attiva una serie di azioni associate all'agente, seguendo uno schema predefinito. API Le knowledge base di Amazon Bedrock utilizzano un indice OpenSearch Serverless come base per il database vettoriale. Inoltre, la Agent executor funzione genera SQL query che vengono eseguite sul database AWS Glue tramite Amazon Athena.
Strumenti
Servizi AWS
Amazon Athena è un servizio di query interattivo che ti aiuta ad analizzare i dati direttamente in Amazon Simple Storage Service (Amazon S3) utilizzando standard. SQL
Amazon Bedrock è un servizio completamente gestito che rende disponibili modelli di base ad alte prestazioni (FMs) delle principali startup di intelligenza artificiale e di Amazon per l'utilizzo tramite un sistema unificato. API
AWSCloud Development Kit (AWSCDK) è un framework di sviluppo software che consente di definire e fornire l'infrastruttura AWS Cloud in codice.
AWSCommand Line Interface (AWSCLI) è uno strumento open source che consente di interagire con i AWS servizi tramite comandi nella shell della riga di comando.
Amazon Elastic Container Service (AmazonECS) è un servizio di gestione dei container veloce e scalabile che ti aiuta a eseguire, arrestare e gestire i container su un cluster.
Elastic Load Balancing (ELB) distribuisce il traffico di applicazioni o di rete in entrata su più destinazioni. Ad esempio, puoi distribuire il traffico tra istanze Amazon Elastic Compute Cloud (AmazonEC2), contenitori e indirizzi IP in una o più zone di disponibilità.
AWSGlue è un servizio di estrazione, trasformazione e caricamento (ETL) completamente gestito. Ti aiuta a classificare, pulire, arricchire e spostare i dati in modo affidabile tra archivi di dati e flussi di dati. Questo modello utilizza un crawler AWS Glue e una tabella AWS Glue Data Catalog.
AWSLambda è un servizio di elaborazione che ti aiuta a eseguire il codice senza dover effettuare il provisioning o gestire i server. Esegue il codice solo quando necessario e si ridimensiona automaticamente, quindi paghi solo per il tempo di elaborazione che utilizzi.
Amazon OpenSearch Serverless è una configurazione serverless su richiesta per Amazon Service. OpenSearch In questo modello, un indice OpenSearch Serverless funge da database vettoriale per le knowledge base di Amazon Bedrock.
Amazon Simple Storage Service (Amazon S3) è un servizio di archiviazione degli oggetti basato sul cloud che consente di archiviare, proteggere e recuperare qualsiasi quantità di dati.
Altri strumenti
Streamlit
è un framework Python open source per creare applicazioni di dati.
Deposito di codice
Il codice per questo pattern è disponibile nel GitHub genai-bedrock-agent-chatbot
assetscartella: le risorse statiche, come il diagramma dell'architettura e il set di dati pubblico.code/lambdas/action-lambdafolder — Il codice Python per la funzione Lambda che funge da azione per l'agente Amazon Bedrock.code/lambdas/create-index-lambdafolder — Il codice Python per la funzione Lambda che crea l'indice Serverless. OpenSearchcode/lambdas/invoke-lambdafolder — Il codice Python per la funzione Lambda che richiama l'agente Amazon Bedrock, chiamato direttamente dall'applicazione Streamlit.code/lambdas/update-lambdafolder — Il codice Python per la funzione Lambda che aggiorna o elimina le risorse dopo che le risorse sono state distribuite tramite. AWS AWS CDKcode/layers/boto3_layerfolder: lo AWS CDK stack che crea un livello Boto3 condiviso tra tutte le funzioni Lambda.code/layers/opensearch_layerfolder: lo AWS CDK stack che crea un livello OpenSearch Serverless che installa tutte le dipendenze per creare l'indice.code/streamlit-appfolder — Il codice Python che viene eseguito come immagine del contenitore in Amazon ECScode/code_stack.py— I file di AWS CDK costruzione in Python che AWS creano risorse.app.py— I file Python AWS CDK dello stack che AWS distribuiscono le risorse nell'account di destinazione. AWSrequirements.txt— L'elenco di tutte le dipendenze Python che devono essere installate per. AWS CDKcdk.json— Il file di input per fornire i valori necessari per creare risorse. Inoltre, neicontext/configcampi, è possibile personalizzare la soluzione di conseguenza. Per ulteriori informazioni sulla personalizzazione, vedere la sezione Informazioni aggiuntive.
Best practice
L'esempio di codice fornito qui è solo a scopo proof-of-concept (PoC) o pilota. Se vuoi portare il codice in produzione, assicurati di utilizzare le seguenti best practice:
Abilita la registrazione degli accessi ad Amazon S3
Imposta il monitoraggio e gli avvisi per le funzioni Lambda. Per ulteriori informazioni, consulta Monitoraggio e risoluzione dei problemi delle funzioni Lambda. Per le best practice, consulta le Best practice per lavorare con le funzioni AWS Lambda.
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Esporta le variabili per l'account e la regione. | Per fornire AWS le credenziali AWS CDK utilizzando le variabili di ambiente, esegui i seguenti comandi.
| AWS DevOps, DevOps ingegnere |
Configura il profilo AWS CLI denominato. | Per configurare il profilo AWS CLI denominato per l'account, segui le istruzioni in Configurazione e impostazioni del file di credenziali. | AWS DevOps, DevOps ingegnere |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Clona il repository sulla tua workstation locale. | Per clonare il repository, esegui il seguente comando nel tuo terminale.
| DevOps ingegnere, AWS DevOps |
Configura l'ambiente virtuale Python. | Per configurare l'ambiente virtuale Python, esegui i seguenti comandi.
Per configurare le dipendenze richieste, esegui il comando seguente.
| DevOps ingegnere, AWS DevOps |
Configura l'AWSCDKambiente. | Per convertire il codice in un AWS CloudFormation modello, esegui il comando | AWS DevOps, DevOps ingegnere |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Distribuisci risorse nell'account. | Per distribuire risorse nell'AWSaccount utilizzando il AWSCDK, procedi come segue:
Una volta completata con successo la distribuzione, puoi accedere all'applicazione di assistenza basata sulla chat utilizzando l'URLapposito comando nella scheda Output della console. CloudFormation | DevOps ingegnere, AWS DevOps |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Rimuovi le AWS risorse. | Dopo aver testato la soluzione, per ripulire le risorse, esegui il comando | AWS DevOps, DevOps ingegnere |
Risorse correlate
Documentazione di AWS
Risorse Amazon Bedrock:
AWSCDKrisorse:
Altre risorse AWS
Altre risorse
Informazioni aggiuntive
Personalizza l'assistente basato sulla chat con i tuoi dati
Per integrare i dati personalizzati per l'implementazione della soluzione, segui queste linee guida strutturate. Questi passaggi sono progettati per garantire un processo di integrazione semplice ed efficiente, che ti consenta di implementare la soluzione in modo efficace con i tuoi dati personalizzati.
Per l'integrazione dei dati nella knowledge base
Preparazione dei dati
Individua la
assets/knowledgebase_data_source/cartella.Posiziona il tuo set di dati in questa cartella.
Modifiche alla configurazione
Apri il file
cdk.json.Vai al
context/configure/paths/knowledgebase_file_namecampo, quindi aggiornalo di conseguenza.Passa al
bedrock_instructions/knowledgebase_instructioncampo, quindi aggiornalo per riflettere accuratamente le sfumature e il contesto del nuovo set di dati.
Per l'integrazione strutturale dei dati
Organizzazione dei dati
All'interno della
assets/data_query_data_source/directory, crea una sottodirectory, ad esempiotabular_data.Inserisci il tuo set di dati strutturato (i formati accettabili includonoCSV, JSONORC, e Parquet) in questa sottocartella appena creata.
Se ti stai connettendo a un database esistente, aggiorna la funzione
code/lambda/action-lambda/build_query_engine.pyper connetterticreate_sql_engine()al tuo database.
Aggiornamenti della configurazione e del codice
Nel
cdk.jsonfile, aggiorna ilcontext/configure/paths/athena_table_data_prefixcampo per allinearlo al nuovo percorso dei dati.Esegui la revisione
code/lambda/action-lambda/dynamic_examples.csvincorporando nuovi text-to-SQL esempi che corrispondono al tuo set di dati.Esegui la revisione
code/lambda/action-lambda/prompt_templates.pyper rispecchiare gli attributi del tuo set di dati strutturato.Nel
cdk.jsonfile, aggiorna ilcontext/configure/bedrock_instructions/action_group_descriptioncampo per spiegare lo scopo e la funzionalità della funzioneAction groupLambda.Nel
assets/agent_api_schema/artifacts_schema.jsonfile, spiega le nuove funzionalità della tua funzioneAction groupLambda.
Aggiornamento generale
Nel cdk.json file, nella context/configure/bedrock_instructions/agent_instruction sezione, fornisci una descrizione completa della funzionalità e dello scopo di progettazione previsti per l'agente Amazon Bedrock, tenendo conto dei nuovi dati integrati.
