Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica del framework
Il framework di analisi della resilienza è stato sviluppato identificando le proprietà di resilienza desiderate di un carico di lavoro. Le proprietà desiderate sono le cose che volete che siano vere riguardo al sistema. La resilienza viene generalmente misurata in base alla disponibilità, quindi cinque proprietà sono le caratteristiche di un sistema distribuito ad alta disponibilità: ridondanza, capacità sufficiente, output tempestivo, output corretto e isolamento dai guasti. Queste proprietà sono illustrate nel diagramma seguente.
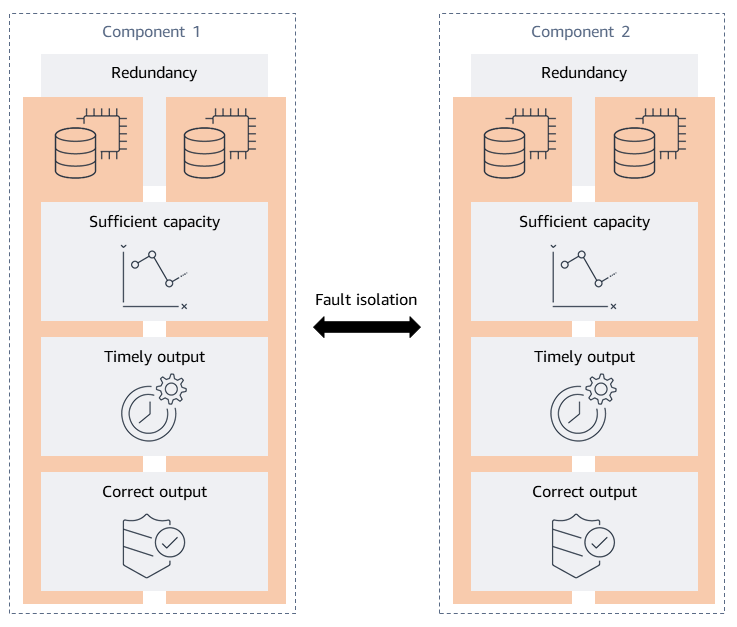
-
Ridondanza: la tolleranza agli errori si ottiene attraverso la ridondanza che elimina i singoli punti di errore (SPOF). La ridondanza può spaziare dai componenti di ricambio del carico di lavoro alle repliche complete dell'intero stack di applicazioni. Quando si considera la ridondanza delle applicazioni, è importante tenere conto del livello di ridondanza fornito dall'infrastruttura, dagli archivi di dati e dalle dipendenze utilizzate. Ad esempio, Amazon DynamoDB e Amazon Simple Storage Service (Amazon S3) forniscono ridondanza replicando i dati su più zone di disponibilità in una AWS Lambda regione ed eseguono le funzioni su più nodi di lavoro in più zone di disponibilità. Per ogni servizio che utilizzi, prendi in considerazione ciò che viene fornito dal servizio e per cosa devi progettare.
-
Capacità sufficiente: il carico di lavoro richiede risorse sufficienti per funzionare come previsto. Le risorse includono memoria, cicli di CPU, thread, storage, velocità effettiva, quote di servizio e molte altre.
-
Produzione tempestiva: quando i clienti utilizzano il carico di lavoro, si aspettano che svolga la funzione prevista entro un periodo di tempo ragionevole. A meno che il servizio non fornisca un accordo sul livello di servizio (SLA) per la latenza, le loro aspettative si basano generalmente su prove empiriche, vale a dire sulla loro esperienza. Questa esperienza media del cliente è generalmente considerata la latenza mediana (P50) del sistema. Se il carico di lavoro richiede più tempo del previsto, questa latenza può influire sull'esperienza dei clienti.
-
Output corretto: è necessario l'output corretto del software del carico di lavoro per fornire le funzionalità previste. Un risultato errato o incompleto può essere peggio di nessuna risposta.
-
Isolamento dei guasti: l'isolamento dei guasti limita l'ambito di impatto al contenitore di guasto previsto quando si verifica un guasto. Garantisce che componenti specifici del carico di lavoro si guastino insieme, impedendo al contempo che un guasto si ripercuota a cascata su altri componenti non intenzionali. Inoltre, aiuta a limitare l'ambito di impatto del carico di lavoro sui clienti. L'isolamento dei guasti è leggermente diverso dalle quattro proprietà precedenti, poiché accetta che si sia già verificato un errore ma deve essere contenuto. È possibile creare l'isolamento degli errori nell'infrastruttura, nelle dipendenze e nelle funzioni software.
La violazione di una proprietà desiderata può causare l'indisponibilità, o la percezione, dell'indisponibilità di un carico di lavoro. Sulla base di queste caratteristiche di resilienza desiderate e della nostra esperienza di lavoro con molti AWS clienti, abbiamo identificato cinque categorie di errori comuni: singoli punti di errore, carico eccessivo, latenza eccessiva, configurazioni errate e bug e destino condiviso, che abbreviiamo in SEEMS. Questi forniscono un metodo coerente per classificare le potenziali modalità di errore e sono descritti nella tabella seguente.
Categoria di errore |
Viola |
Definizione |
|---|---|---|
Singoli punti di guasto (SPOF) |
Ridondanza |
Un guasto in un singolo componente danneggia il sistema a causa della mancanza di ridondanza del componente. |
Carico eccessivo |
Capacità sufficiente |
Over-consumption la presenza di una risorsa a causa di una domanda o di un traffico eccessivi impedisce alla risorsa di svolgere la funzione prevista. Ciò può includere il raggiungimento di limiti e quote, che causano la limitazione e il rifiuto delle richieste. |
Latenza eccessiva |
Uscita tempestiva |
L'elaborazione del sistema o la latenza del traffico di rete superano il tempo, gli obiettivi a livello di servizio (SLO) o gli accordi sui livelli di servizio (SLA) previsti. |
Errori di configurazione e bug |
Output corretto |
I bug del software o l'errata configurazione del sistema portano a un output errato. |
Destino condiviso |
Isolamento degli errori |
Un guasto causato da una delle precedenti categorie di guasto supera i limiti di isolamento dei guasti previsti e si ripercuote a cascata su altre parti del sistema o su altri clienti. |
