Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprendere il carico di lavoro
Per applicare il framework, inizia a comprendere il carico di lavoro che desideri analizzare. Un diagramma dell'architettura del sistema fornisce un punto di partenza per documentare i dettagli più rilevanti del sistema. Tuttavia, cercare di analizzare un intero carico di lavoro può essere complesso, poiché molti sistemi hanno numerosi componenti e interazioni. Ti consigliamo invece di concentrarti sulle storie degli utenti
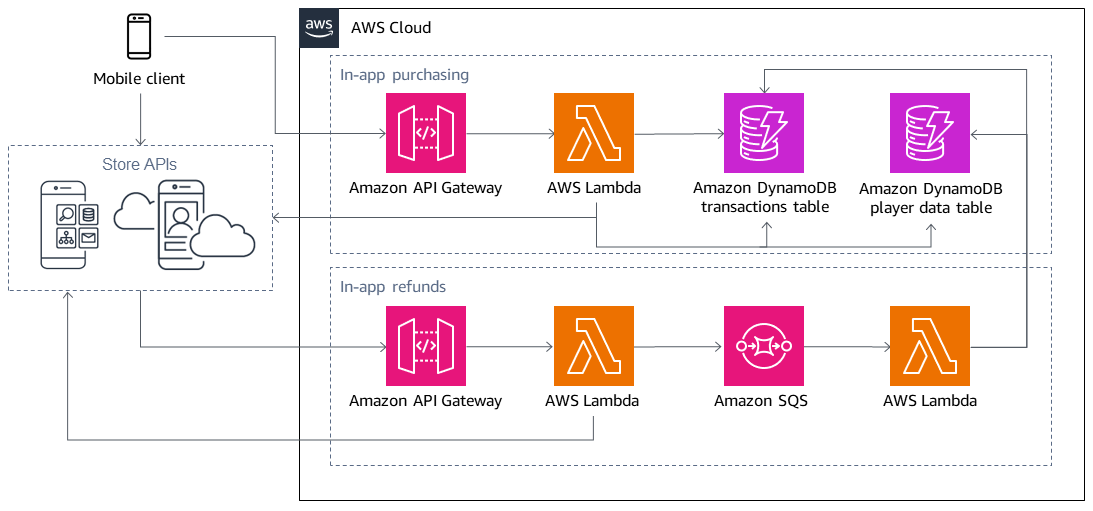
Ogni storia utente è composta da quattro componenti comuni: codice e configurazione, infrastruttura, archivi dati e dipendenze esterne. I diagrammi devono includere tutti questi componenti e riflettere le interazioni tra i componenti. Ad esempio, se il carico sull'endpoint Amazon API Gateway è eccessivo, considera in che modo tale carico si ripercuote su altri componenti del sistema, come AWS Lambda le funzioni o le tabelle Amazon DynamoDB. Il monitoraggio di queste interazioni ti aiuta a capire in che modo la modalità di errore può influire sulla storia dell'utente. È possibile acquisire questo flusso visivamente con un diagramma di flusso di dati o utilizzando semplici frecce di flusso in un diagramma di architettura, come nell'illustrazione precedente. Per ogni componente, prendete in considerazione l'acquisizione di dettagli come il tipo di informazioni che vengono trasmesse, le informazioni ricevute, se la comunicazione è sincrona o asincrona e quali limiti di errore vengono superati. Nell'esempio, le tabelle DynamoDB sono condivise in entrambe le storie utente, come si può vedere dalle frecce che indicano che il componente Lambda nella storia dei rimborsi in-app accede alle tabelle DynamoDB nella storia degli acquisti in-app. Ciò significa che un errore causato dalla storia utente relativa agli acquisti in-app potrebbe ripercuotersi a cascata sulla storia utente relativa ai rimborsi in-app come conseguenza di un destino condiviso.
Inoltre, è importante comprendere la configurazione di base per ogni componente. La configurazione di base identifica vincoli quali il numero medio e massimo di transazioni al secondo, la dimensione massima di un payload, il timeout del client e le quote di servizio predefinite o correnti per la risorsa. Se state modellando un nuovo progetto, vi consigliamo di documentarne i requisiti funzionali e di considerarne i limiti. Questo aiuta a capire come potrebbero manifestarsi le modalità di guasto nel componente.
Infine, è necessario dare priorità alle storie degli utenti in base al valore aziendale che forniscono. Questa prioritizzazione ti aiuta a concentrarti innanzitutto sulle funzionalità più importanti del tuo carico di lavoro. È quindi possibile concentrare l'analisi sui componenti del carico di lavoro che fanno parte del percorso critico per tale funzionalità e ottenere valore dall'utilizzo più rapido del framework. Durante l'iterazione del processo, è possibile esaminare storie utente aggiuntive con priorità diverse.
