Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizza le funzioni definite dall'utente
Le funzioni definite dall'utente (UDFs) PySpark spesso riducono notevolmente RDD.map le prestazioni. Ciò è dovuto al sovraccarico richiesto per rappresentare accuratamente il codice Python nell'implementazione Scala sottostante di Spark.
Il diagramma seguente mostra l'architettura dei job. PySpark Quando si utilizza PySpark, il driver Spark utilizza la libreria Py4j per richiamare i metodi Java da Python. Quando si chiamano Spark SQL o funzioni DataFrame integrate, c'è poca differenza di prestazioni tra Python e Scala perché le funzioni vengono eseguite su ciascun esecutore utilizzando un piano JVM di esecuzione ottimizzato.
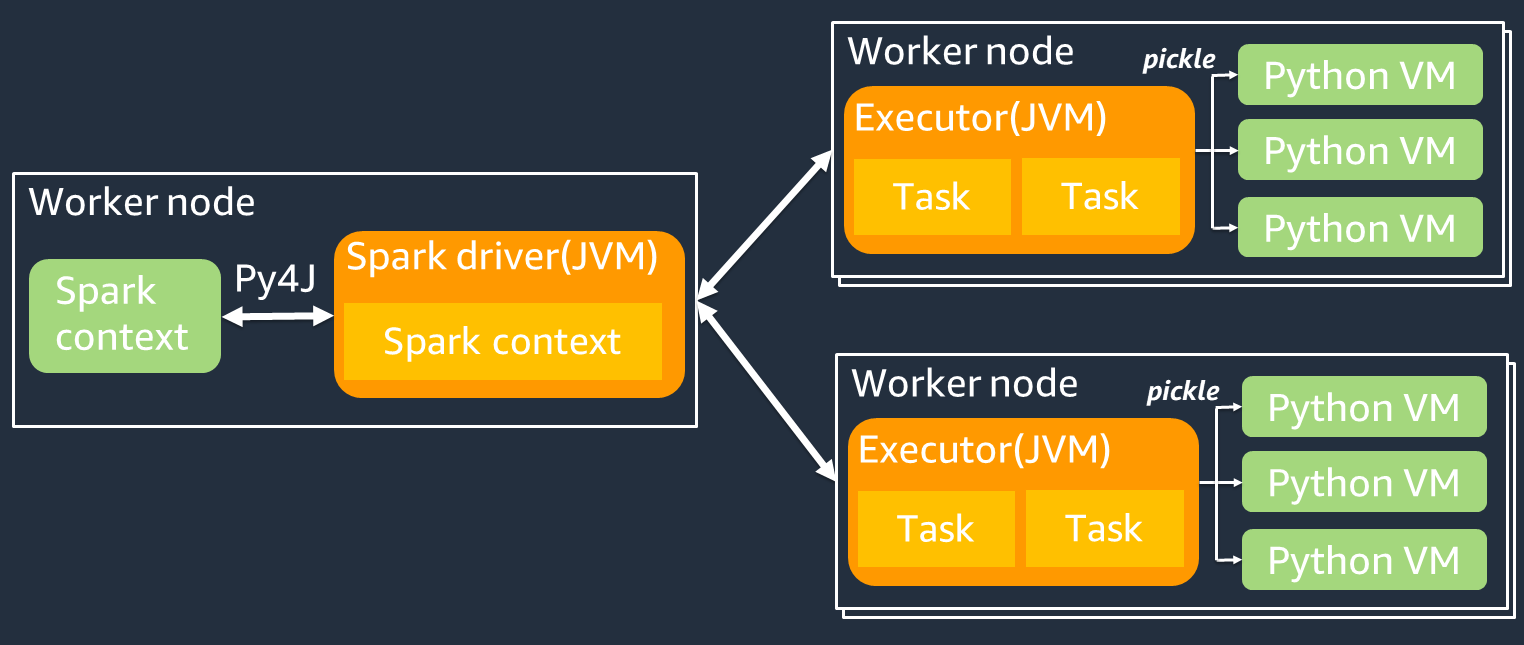
Se usi la tua logica Python, ad esempio usingmap/ mapPartitions/ udf, l'attività verrà eseguita in un ambiente di runtime Python. La gestione di due ambienti comporta un costo generale. Inoltre, i dati in memoria devono essere trasformati per essere utilizzati dalle funzioni integrate dell'ambiente di JVM runtime. Pickle è un formato di serializzazione utilizzato di default per lo scambio tra i runtime e JVM Python. Tuttavia, il costo di questo costo di serializzazione e deserializzazione è molto elevato, quindi gli UDFs scritti in Java o Scala sono più veloci di Python. UDFs
Per evitare il sovraccarico di serializzazione e deserializzazione, considerate quanto segue: PySpark
-
Usa le SQL funzioni Spark integrate: valuta la possibilità di sostituire la tua funzione o quella della mappa con Spark UDF o con funzioni integrate. SQL DataFrame Quando si eseguono Spark SQL o funzioni DataFrame integrate, c'è poca differenza di prestazioni tra Python e Scala perché le attività vengono gestite su ciascun esecutore. JVM
-
UDFsImplementa in Scala o Java: prendi in considerazione l'utilizzo di file scritti in Java o Scala, perché vengono eseguiti su. UDF JVM
-
Usa sistemi basati su Apache Arrow UDFs per carichi di lavoro vettoriali: valuta la possibilità di utilizzare quelli basati su Apache Arrow. UDFs Questa funzionalità è nota anche come vettorializzata (Pandas). UDF UDF Apache Arrow
è un formato di dati in memoria indipendente dalla lingua che AWS Glue può essere utilizzato per trasferire in modo efficiente i dati tra e processi Python. JVM Questo è attualmente molto vantaggioso per gli utenti di Python che lavorano con Panda o dati. NumPy Arrow è un formato colonnare (vettoriale). Il suo utilizzo non è automatico e potrebbe richiedere alcune piccole modifiche alla configurazione o al codice per trarne il massimo vantaggio e garantire la compatibilità. Per maggiori dettagli e limitazioni, consulta Apache Arrow in PySpark
. L'esempio seguente confronta un incrementale di base UDF in Python standard, come UDF vettorizzato e in Spark. SQL
Python standard UDF
Il tempo di esempio è 3,20 (sec).
Esempio di codice
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Piano di esecuzione
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Vettorizzato UDF
Il tempo di esempio è 0,59 (sec).
Vectorized UDF è 5 volte più veloce dell'esempio precedente. UDF VerificaPhysical Plan, come puoi vedereArrowEvalPython, che mostra che questa applicazione è vettorializzata da Apache Arrow. Per abilitare VectorizedUDF, è necessario specificare nel codice. spark.sql.execution.arrow.pyspark.enabled = true
Esempio di codice
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Piano di esecuzione
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Spark SQL
Il tempo di esempio è 0,087 (sec).
Spark SQL è molto più veloce di VectorizedUDF, perché le attività vengono eseguite su ogni executor senza JVM un runtime Python. Se puoi sostituire la tua UDF con una funzione integrata, ti consigliamo di farlo.
Esempio di codice
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Usare i panda per i big data
Se conosci già i panda e
