Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ridurre la quantità di scansione dei dati
Per iniziare, valuta la possibilità di caricare solo i dati di cui hai bisogno. Puoi migliorare le prestazioni semplicemente riducendo la quantità di dati caricati nel cluster Spark per ogni fonte di dati. Per valutare se questo approccio è appropriato, utilizza le seguenti metriche.
CloudWatch metriche
Puoi vedere la dimensione approssimativa di lettura da Amazon S3 ETLin Data Movement (Bytes). Questa metrica mostra il numero di byte letti da Amazon S3 da tutti gli esecutori rispetto al rapporto precedente. Puoi usarlo per monitorare il movimento ETL dei dati da Amazon S3 e confrontare le velocità di lettura con quelle di acquisizione da fonti di dati esterne.
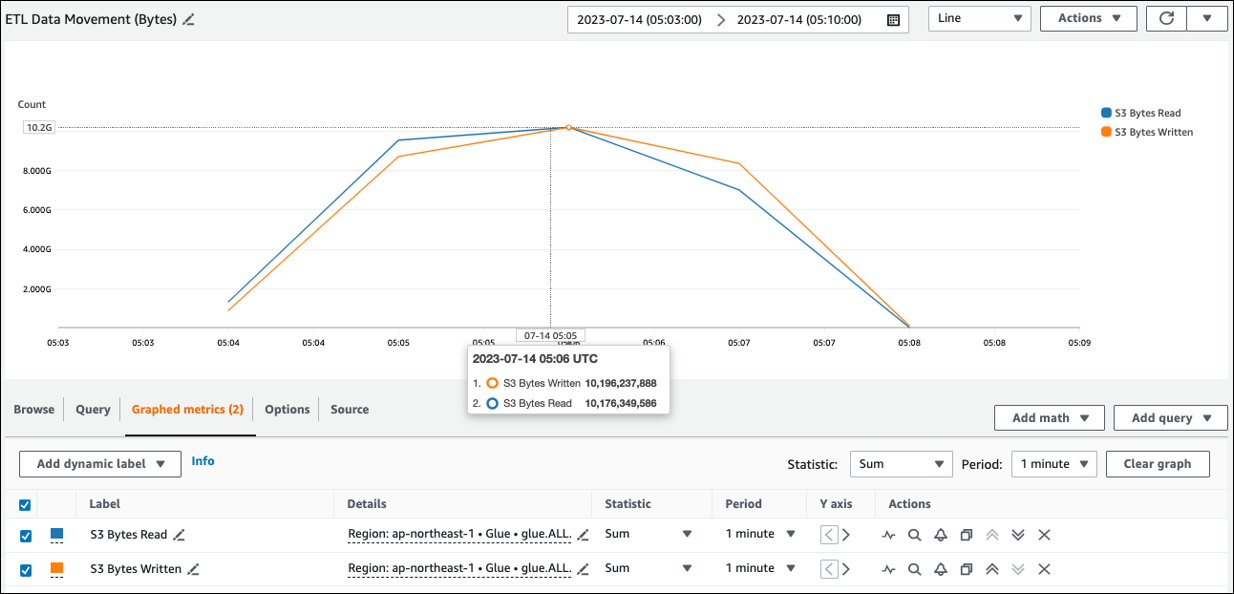
Se osservi un data point S3 Bytes Read più grande del previsto, prendi in considerazione le seguenti soluzioni.
Interfaccia utente di Spark
Nella scheda Stage dell'interfaccia utente AWS Glue di Spark, puoi vedere le dimensioni di input e output. Nell'esempio seguente, lo stage 2 legge 47,4 GiB di input e 47,7 GiB di output, mentre lo stage 5 legge 61,2 MiB di input e 56,6 MiB di output.

Quando utilizzi Spark SQL o DataFrame approcci nel tuo AWS Glue lavoro, la scheda /D mostra ulteriori statistiche su queste fasi. SQL ataFrame In questo caso, la fase 2 mostra il numero di file letti: 430, la dimensione dei file letti: 47,4 GiB e il numero di righe di output: 160.796.570.
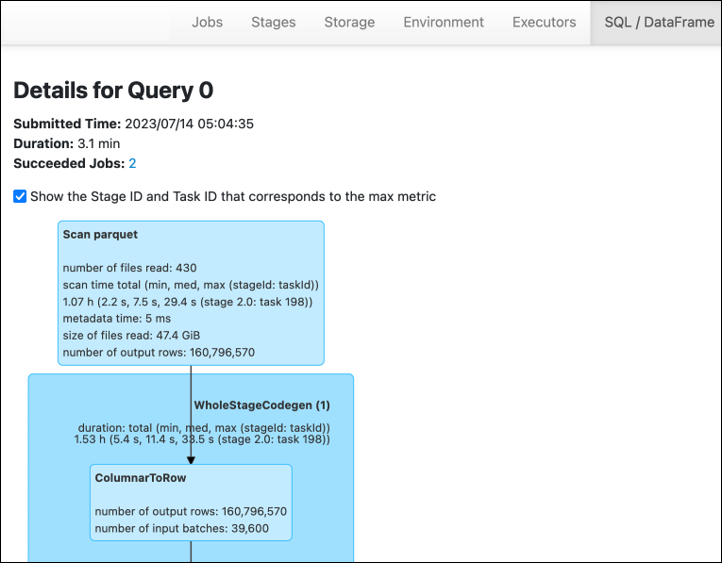
Se notate che esiste una differenza sostanziale nelle dimensioni tra i dati che state leggendo e quelli che state utilizzando, provate le seguenti soluzioni.
Amazon S3
Per ridurre la quantità di dati caricati nel tuo lavoro durante la lettura da Amazon S3, considera le dimensioni, la compressione, il formato del file e il layout del file (partizioni) per il tuo set di dati. AWS Glue per Spark i job vengono spesso utilizzati per ETL dati grezzi, ma per un'elaborazione distribuita efficiente è necessario controllare le caratteristiche del formato di origine dei dati.
-
Dimensioni del file: consigliamo di mantenere le dimensioni dei file di input e output entro un intervallo moderato (ad esempio, 128 MB). File troppo piccoli e file troppo grandi possono causare problemi.
Un numero elevato di file di piccole dimensioni causa i seguenti problemi:
-
Elevato carico di I/O di rete su Amazon S3 a causa del sovraccarico necessario per effettuare richieste (
Listad esempioGet,Heado) per molti oggetti (rispetto a pochi oggetti che memorizzano la stessa quantità di dati). -
Intenso carico di I/O e di elaborazione sul driver Spark, che genererà molte partizioni e attività e porterà a un parallelismo eccessivo.
D'altra parte, se il tipo di file non è divisibile (come gzip) e i file sono troppo grandi, l'applicazione Spark deve attendere il completamento di una singola operazione di lettura dell'intero file.
Per ridurre l'eccessivo parallelismo che si verifica quando viene creata un'attività di Apache Spark per ogni file di piccole dimensioni, utilizzate il raggruppamento di file per. DynamicFrames Questo approccio riduce le possibilità di un'OOMeccezione dal driver Spark. Per configurare il raggruppamento dei file, impostate i parametri
groupFilesandgroupSize. L'esempio di codice seguente utilizza lo script AWS Glue DynamicFrame API in uno ETL script con questi parametri.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Compressione: se i tuoi oggetti S3 misurano centinaia di megabyte, valuta la possibilità di comprimerli. Esistono vari formati di compressione, che possono essere generalmente classificati in due tipi:
-
I formati di compressione non divisibili come gzip richiedono che l'intero file venga decompresso da un operatore.
-
I formati di compressione divisibili, come bzip2 o LZO (indicizzato), consentono la decompressione parziale di un file, che può essere parallelizzata.
Per Spark (e altri motori di elaborazione distribuita comuni), suddividerai il file di dati sorgente in blocchi che il tuo motore può elaborare in parallelo. Queste unità vengono spesso chiamate split. Dopo che i dati sono in un formato divisibile, i AWS Glue lettori ottimizzati possono recuperare le suddivisioni da un oggetto S3 offrendo la
Rangepossibilità di recuperare solo blocchi specifici.GetObjectAPI Considerate il diagramma seguente per vedere come funzionerebbe in pratica.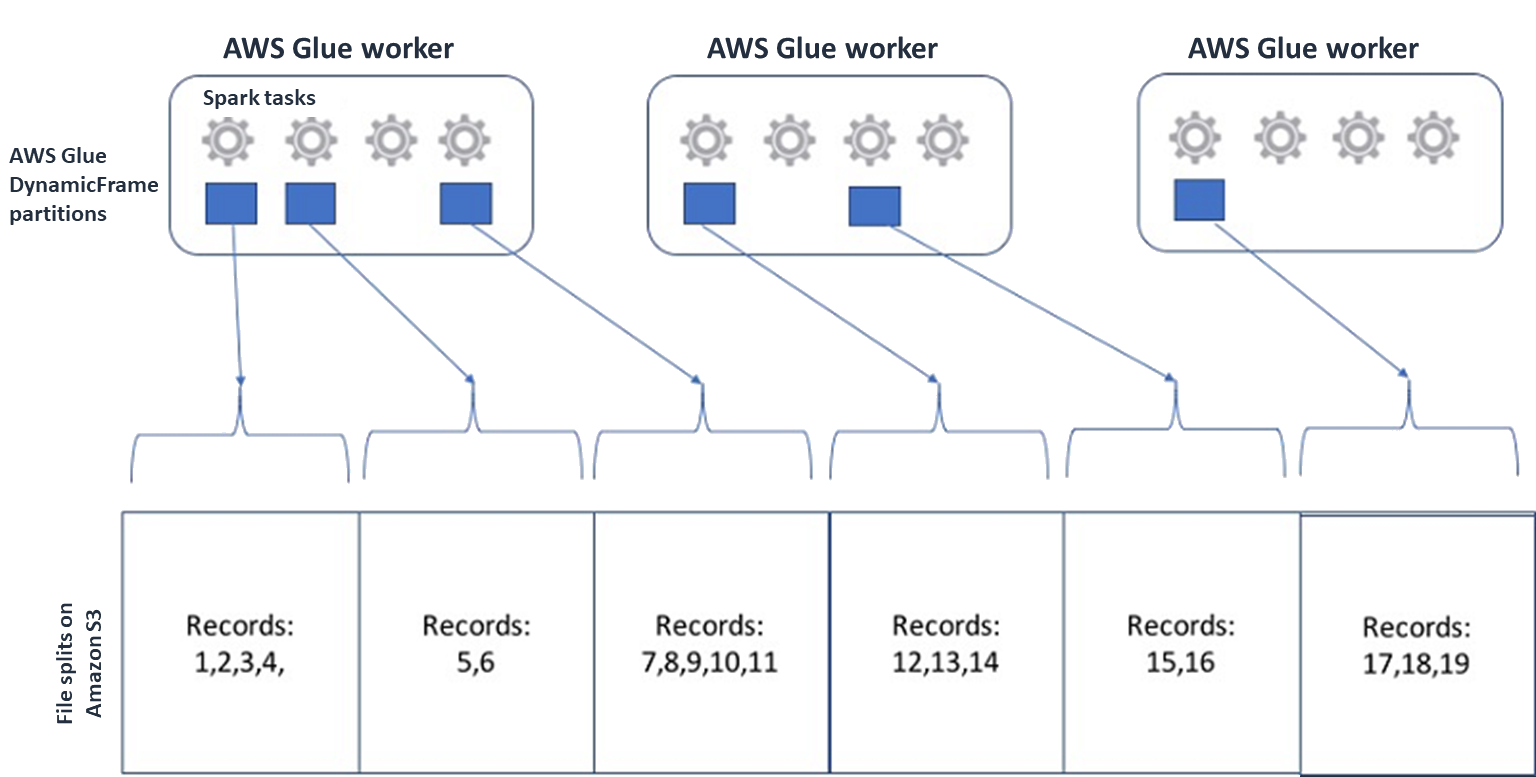
I dati compressi possono velocizzare notevolmente l'applicazione, purché i file abbiano una dimensione ottimale o siano divisibili. Le dimensioni dei dati più piccole riducono i dati scansionati da Amazon S3 e il traffico di rete da Amazon S3 al cluster Spark. D'altra parte, CPU è necessario fare di più per comprimere e decomprimere i dati. La quantità di calcolo richiesta varia in base al rapporto di compressione dell'algoritmo di compressione. Considerate questo compromesso quando scegliete il formato di compressione divisibile.
Nota
Sebbene i file gzip non siano generalmente divisibili, puoi comprimere singoli blocchi di parquet con gzip e quei blocchi possono essere parallelizzati.
-
-
Formato di file: utilizza un formato colonnare. Apache Parquet e Apache
ORC sono i formati di dati colonnari più diffusi. Parquet e ORC archivia i dati in modo efficiente utilizzando la compressione, la codifica e la compressione basate su colonne in base al tipo di dati. Per ulteriori informazioni sulle codifiche Parquet, consulta Definizioni di codifica Parquet. I file Parquet sono anche divisibili. I formati colonnari raggruppano i valori per colonna e li memorizzano in blocchi. Quando usi i formati colonnari, puoi saltare i blocchi di dati che corrispondono a colonne che non intendi utilizzare. Le applicazioni Spark possono recuperare solo le colonne di cui hai bisogno. In genere, rapporti di compressione migliori o il salto di blocchi di dati implicano la lettura di un numero inferiore di byte da Amazon S3, con conseguente miglioramento delle prestazioni. Entrambi i formati supportano anche i seguenti approcci pushdown per ridurre l'I/O:
-
Projection pushdown: il proiection pushdown è una tecnica per recuperare solo le colonne specificate nell'applicazione. È possibile specificare le colonne nell'applicazione Spark, come mostrato negli esempi seguenti:
-
DataFrame esempio:
df.select("star_rating") -
SQLEsempio di Spark:
spark.sql("select start_rating from <table>")
-
-
Predicate pushdown: il predicate pushdown è una tecnica per l'elaborazione efficiente di clausole e clausole.
WHEREGROUP BYEntrambi i formati hanno blocchi di dati che rappresentano i valori delle colonne. Ogni blocco contiene le statistiche relative al blocco, ad esempio i valori massimi e minimi. Spark può utilizzare queste statistiche per determinare se il blocco deve essere letto o ignorato a seconda del valore del filtro utilizzato nell'applicazione. Per utilizzare questa funzione, aggiungi altri filtri nelle condizioni, come mostrato negli esempi seguenti:-
DataFrame esempio:
df.select("star_rating").filter("star_rating < 2") -
SQLEsempio di Spark:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Layout dei file: archiviando i dati S3 su oggetti in percorsi diversi in base a come verranno utilizzati i dati, puoi recuperare in modo efficiente i dati pertinenti. Per ulteriori informazioni, consulta Organizzazione degli oggetti utilizzando i prefissi nella documentazione di Amazon S3. AWS Glue supporta la memorizzazione di chiavi e valori nei prefissi Amazon S3 nel formato
key=value, partizionando i dati in base al percorso Amazon S3. Partizionando i dati, puoi limitare la quantità di dati scansionati da ciascuna applicazione di analisi downstream, migliorando le prestazioni e riducendo i costi. Per ulteriori informazioni, consulta Gestione delle partizioni per l'output in. ETL AWS GlueIl partizionamento divide la tabella in diverse parti e mantiene i dati correlati in file raggruppati in base ai valori delle colonne come anno, mese e giorno, come illustrato nell'esempio seguente.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...È possibile definire le partizioni per il set di dati modellandolo con una tabella in. AWS Glue Data CatalogÈ quindi possibile limitare la quantità di dati scansionati utilizzando la rimozione delle partizioni come segue:
-
Per AWS Glue DynamicFrame, set
push_down_predicate(ocatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Per Spark DataFrame, imposta un percorso fisso per eliminare le partizioni.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Per SparkSQL, puoi impostare la clausola where per eliminare le partizioni dal Data Catalog.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Per partizionare i dati partitionKeysin base alla data con cui scrivi i dati AWS Glue, devi inserire DynamicFrame o partitionBy() inserire
le informazioni sulla data nelle DataFrame colonne nel modo seguente. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Ciò può migliorare le prestazioni degli utenti dei dati di output.
Se non avete accesso per modificare la pipeline che crea il set di dati di input, il partizionamento non è un'opzione. Invece, puoi escludere percorsi S3 non necessari utilizzando modelli a glob. Imposta le esclusioni durante la lettura. DynamicFrame Ad esempio, il codice seguente esclude i giorni nei mesi da 01 a 09, nell'anno 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )Puoi anche impostare esclusioni nelle proprietà della tabella nel Catalogo dati:
-
Chiave:
exclusions -
Valore:
["**year=2023/month=0[1-9]/**"]
-
-
-
Troppe partizioni Amazon S3: evita di partizionare i dati Amazon S3 su colonne che contengono un'ampia gamma di valori, ad esempio una colonna ID con migliaia di valori. Ciò può aumentare notevolmente il numero di partizioni nel bucket, poiché il numero di partizioni possibili è il prodotto di tutti i campi in base ai quali hai partizionato. Troppe partizioni potrebbero causare quanto segue:
-
Maggiore latenza per il recupero dei metadati delle partizioni dal Data Catalog
-
Aumento del numero di file di piccole dimensioni, che richiede più API richieste Amazon S3 (
ListGet, e)Head
Ad esempio, quando si imposta un tipo di data in
partitionByorpartitionKeys, il partizionamento a livello di datayyyy/mm/ddè utile per molti casi d'uso. Tuttavia,yyyy/mm/dd/<ID>potrebbe generare così tante partizioni da influire negativamente sulle prestazioni complessive.D'altra parte, alcuni casi d'uso, come le applicazioni di elaborazione in tempo reale, richiedono molte partizioni come.
yyyy/mm/dd/hhSe il tuo caso d'uso richiede partizioni sostanziali, prendi in considerazione l'utilizzo di indici di AWS Glue partizione per ridurre la latenza per il recupero dei metadati delle partizioni dal Data Catalog. -
Database e JDBC
Per ridurre la scansione dei dati durante il recupero di informazioni da un database, è possibile specificare un where predicato (o una clausola) in una query. SQL I database che non forniscono un'SQLinterfaccia forniranno il proprio meccanismo di interrogazione o filtraggio.
Quando utilizzate le connessioni Java Database Connectivity (JDBC), fornite una query di selezione con la where clausola per i seguenti parametri:
-
Per DynamicFrame, utilizzate l'sampleQueryopzione. Durante l'utilizzo
create_dynamic_frame.from_catalog, configura l'additional_optionsargomento come segue.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Quando
using create_dynamic_frame.from_options, configura l'connection_optionsargomento come segue.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Per DataFrame, usa l'opzione di interrogazione
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Per Amazon Redshift, usa la AWS Glue versione 4.0 o successiva per sfruttare il supporto pushdown nel connettore Amazon Redshift Spark.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Per altri database, consulta la documentazione relativa a quel database.
AWS Glue opzioni
-
Per evitare una scansione completa per tutte le esecuzioni continue dei lavori ed elaborare solo i dati che non erano presenti durante l'ultima esecuzione del processo, abilita i segnalibri dei lavori.
-
Per limitare la quantità di dati di input da elaborare, abilita l'esecuzione limitata con i segnalibri dei lavori. Questo aiuta a ridurre la quantità di dati scansionati per ogni esecuzione di lavoro.
