Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Riduzione al minimo dei tempi di vuoto
Amazon Redshift riordina automaticamente i dati ed esegue VACUUM DELETE in background. Ciò riduce la necessità di eseguire il comando VACUUM. L'aspirazione è un processo potenzialmente dispendioso in termini di tempo. A seconda della natura dei dati, consigliamo le seguenti pratiche per ridurre al minimo i tempi di vuoto.
Argomenti
Decidi se reindicizzare
Spesso è possibile migliorare in modo significativo le prestazioni delle query utilizzando uno stile di ordinamento interleaved, ma le prestazioni nel tempo potrebbero peggiorare se la distribuzione dei valori nelle colonne delle chiavi di ordinamento cambia.
Quando inizialmente si carica una tabella interlacciata vuota utilizzando COPY o CREATE TABLE AS, Amazon Redshift crea automaticamente l'indice interlacciato. Se inizialmente carichi una tabella interleaved utilizzando INSERT, è necessario eseguire VACUUM REINDEX in seguito per inizializzare l'indice interleaved.
Nel corso del tempo, quando aggiungi righe con nuovi valori di chiave di ordinamento, le prestazioni potrebbero peggiorare se la distribuzione dei valori nelle colonne della chiave di ordinamento cambia. Se le nuove righe rientrano principalmente nell'intervallo dei valori delle chiavi di ordinamento esistenti, non è necessario reindicizzare. Esegui VACUUM SORT ONLY o VACUUM FULL per ripristinare l'ordinamento.
Il motore di query è in grado di utilizzare l'ordinamento per selezionare in modo efficiente i blocchi di dati che devono essere sottoposti a scansione per elaborare una query. Per un ordinamento interlacciato, Amazon Redshift analizza i valori della colonna chiave di ordinamento per determinare l'ordinamento ottimale. Se la distribuzione dei valori delle chiavi cambia o si differenzia, quando vengono aggiunte le righe, la strategia di ordinamento non sarà più ottimale e il vantaggio in termini di prestazioni dell'ordinamento diminuirà. Per analizzare nuovamente la distribuzione delle chiavi di ordinamento è possibile eseguire un VACUUM REINDEX. L'operazione di reindicizzazione richiede molto tempo, quindi per decidere se una tabella trarrà vantaggio da una reindicizzazione, esegui una query sulla vista SVV_INTERLEAVED_COLUMNS.
Ad esempio, la seguente query mostra i dettagli per le tabelle che utilizzano chiavi di ordinamento interleaved.
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
Il valore per interleaved_skew è un rapporto che indica la quantità di differenza. Il valore 1 indica nessuna differenza. Se la differenza è maggiore di 1,4, un VACUUM REINDEX di solito migliora le prestazioni a meno che la differenza non riguardi il set sottostante.
È possibile utilizzare il valore della data last_reindex per determinare quanto tempo è passato dall'ultima reindicizzazione.
Riduci le dimensioni della regione non ordinata
La regione non ordinata aumenta quando carichi grandi quantità di nuovi dati in tabelle che contengono già dati o quando non esegui il vacuum delle tabelle come parte delle operazioni di manutenzione ordinaria. Per evitare operazioni di vacuum a lunga durata, utilizza le seguenti pratiche:
-
Esegui le operazioni di vacuum su una pianificazione regolare.
Se carichi le tabelle in piccoli incrementi (come gli aggiornamenti giornalieri che rappresentano una piccola percentuale del numero totale di righe nella tabella), eseguire regolarmente VACUUM contribuirà a garantire che le singole operazioni di vacuum siano rapide.
-
Esegui prima il carico maggiore.
Se è necessario caricare una nuova tabella con più operazioni di COPY, esegui prima il carico più grande. Quando esegui un caricamento iniziale in una tabella nuova o troncata, tutti i dati vengono caricati direttamente nella regione ordinata, quindi non è richiesto il vacuum.
-
Tronca una tabella anziché eliminare tutte le righe.
L'eliminazione di righe da una tabella non recupera lo spazio occupato dalle righe finché non esegui un'operazione di vacuum; tuttavia, il troncamento di una tabella svuota la tabella e recupera lo spazio su disco, quindi non è richiesto il vacuum. In alternativa, rilascia la tabella e creala nuovamente.
-
Tronca o rilascia tabelle di test.
Se stai caricando un numero limitato di righe in una tabella a scopo di test, non eliminare le righe al termine dell'operazione. Tronca, invece, la tabella e ricarica quelle righe come parte della successiva operazione di caricamento di produzione.
-
Esegui una copia completa.
Se una tabella che utilizza una tabella di chiavi di ordinamento composta presenta un'ampia regione non ordinata, una copia completa risulta molto più veloce di un vacuum. Una copia completa ricrea e ripopola una tabella tramite inserimento di massa, che ordina di nuovo automaticamente la tabella. Se una tabella ha una regione ampia e non ordinata, una copia completa è molto più veloce di un vacuum. Lo svantaggio è che non è possibile effettuare aggiornamenti simultanei durante un'operazione di copia completa, possibile invece durante un vacuum. Per ulteriori informazioni, consulta Best practice di Amazon Redshift per la progettazione di query.
Ridurre il volume delle righe unite
Se un'operazione di vacuum deve unire nuove righe nella regione ordinata di una tabella, il tempo richiesto per un vacuum aumenterà man mano che le dimensioni della tabella aumenteranno. È possibile migliorare le prestazioni di vacuum riducendo il numero di righe che devono essere unite.
Prima di un'operazione vacuum, una tabella è composta da una regione ordinata nella parte superiore della tabella, seguita da una regione non ordinata, che aumenta ogni volta che vengono aggiunte o aggiornate delle righe. Quando un set di righe viene aggiunto da un'operazione di COPY, il nuovo set di righe viene ordinato sulla chiave di ordinamento quando viene aggiunto alla regione non ordinata nella parte inferiore della tabella. Le nuove righe sono ordinate all'interno dello stesso set, ma non all'interno della regione non ordinata.
Il diagramma seguente illustra la regione non ordinata dopo due successive operazioni di COPY, dove la chiave di ordinamento è CUSTID. Per semplicità, questo esempio mostra una chiave di ordinamento composta, ma gli stessi principi si applicano alle chiavi di ordinamento interleaved, tranne per il fatto che l'impatto della regione non ordinata è maggiore per le tabelle interleaved.

Un vacuum ripristina l'ordinamento della tabella in due fasi:
-
Ordina la regione non ordinata in una regione appena ordinata.
La prima fase è relativamente economica, poiché viene riscritta solo la regione non ordinata. Se l'intervallo dei valori delle chiavi di ordinamento della regione appena ordinata è superiore all'intervallo esistente, solo le nuove righe devono essere riscritte e l'operazione vacuum è completa. Ad esempio, se la regione ordinata contiene valori di ID da 1 a 500 e le successive operazioni di COPY aggiungono valori chiave maggiori di 500, è necessario riscrivere solo la regione non ordinata.
-
Unisci la regione appena ordinata alla regione precedentemente ordinata.
Se le chiavi nella regione appena ordinata si sovrappongono alle chiavi nella regione ordinata, VACUUM deve unire le righe. Partendo dall'inizio della regione appena ordinata (con la chiave di ordinamento più bassa), il vacuum scrive le righe unite dalla regione ordinata in precedenza e la regione appena ordinata in una nuova serie di blocchi.
La misura in cui il nuovo intervallo di chiavi di ordinamento si sovrappone alle chiavi di ordinamento esistenti determina la misura in cui la regione precedentemente ordinata dovrà essere riscritta. Se le chiavi non ordinate sono distribuite nell'intero intervallo di ordinamento esistente, potrebbe essere necessario un vacuum per riscrivere le parti esistenti della tabella.
Il seguente diagramma mostra come un vacuum dovrebbe ordinare e unire righe che vengono aggiunte a una tabella in cui CUSTID è la chiave di ordinamento. Dato che ogni operazione di COPY aggiunge un nuovo set di righe con valori chiave che si sovrappongono alle chiavi esistenti, è necessario riscrivere quasi l'intera tabella. Il diagramma mostra una singola operazione di ordinamento e unione, ma in pratica, un'ampia operazione di vacuum consiste in una serie di fasi incrementali di ordinamento e unione.

Se l'intervallo di chiavi di ordinamento in un set di nuove righe si sovrappone all'intervallo di chiavi esistenti, il costo della fase di unione continua ad aumentare in proporzione alle dimensioni della tabella man mano che queste aumentano, mentre il costo della fase di ordinamento rimane proporzionale alla dimensione della regione non ordinata. In tal caso, il costo della fase di unione eclissa il costo della fase di ordinamento, come mostra il diagramma seguente.

Per determinare quale proporzione di una tabella è stata rimossa, esegui una query su SVV_VACUUM_SUMMARY al termine dell'operazione di vacuum. La seguente query mostra l'effetto di sei successive operazioni di vacuum man mano che CUSTSALES aumentava nel tempo.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
La colonna merge_increments fornisce un'indicazione della quantità di dati che è stata unita per ciascuna operazione di vacuum. Se il numero di incrementi di unione in operazioni vacuum consecutive aumenta in proporzione alla crescita delle dimensioni della tabella, ciò indica che ogni operazione vacuum sta unendo nuovamente un numero crescente di righe nella tabella, poiché le regioni esistenti e appena ordinate si sovrappongono.
Carica i dati nell'ordine delle chiavi di ordinamento
Se carichi i dati nell'ordine delle chiavi di ordinamento utilizzando un comando COPY, è possibile ridurre o anche eliminare la necessità di eseguire un'operazione vacuum.
COPY aggiunge automaticamente nuove righe alla regione ordinata della tabella quando sono vere tutte le seguenti condizioni:
-
La tabella utilizza una chiave di ordinamento composta con una sola colonna di ordinamento.
-
La colonna di ordinamento è NOT NULL.
-
La tabella è ordinata al 100% o vuota.
-
Tutte le nuove righe sono più alte nell'ordinamento rispetto alle righe esistenti, incluse le righe contrassegnate per l'eliminazione. In questo caso, Amazon Redshift utilizza i primi otto byte della chiave di ordinamento per determinare l'ordinamento.
Ad esempio, supponiamo di disporre di una tabella che registra gli eventi dei clienti utilizzando un ID cliente e l'ora. Se ordini in base all'ID cliente, è probabile che l'intervallo di chiavi di ordinamento delle nuove righe aggiunte da carichi incrementali si sovrapponga all'intervallo esistente, come illustrato nell'esempio precedente, portando a una costosa operazione di vacuum.
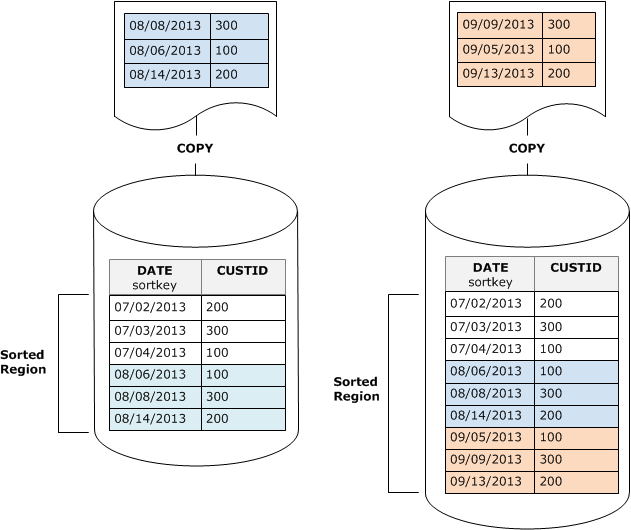
Se imposti la chiave di ordinamento su una colonna timestamp, le nuove righe verranno aggiunte in ordine nella parte inferiore della tabella, come illustrato nel diagramma seguente, riducendo o addirittura eliminando la necessità di eseguire un'operazione vacuum.
Utilizza le tabelle delle serie temporali per ridurre i dati archiviati
Se conservi i dati per un periodo di tempo continuo, utilizza una serie di tabelle, come illustrato nel diagramma seguente.

Crea una nuova tabella ogni volta che aggiungi un set di dati, quindi elimina la tabella più vecchia della serie. Ottieni un doppio vantaggio:
-
Eviti il costo aggiuntivo dell'eliminazione delle righe, poiché un'operazione di DROP TABLE è molto più efficiente di una di DELETE di massa.
-
Se le tabelle sono ordinate per timestamp, non è necessario il vacuum. Se ogni tabella contiene dati per un mese, il vacuum dovrà al massimo riscrivere i dati di un mese, anche se le tabelle non sono ordinate per timestamp.
È possibile creare una vista UNION ALL per l'utilizzo segnalando query che nascondono il fatto che i dati sono archiviati in più tabelle. Se una query filtra la chiave di ordinamento, il pianificatore di query può ignorare in modo efficiente tutte le tabelle che non vengono utilizzate. Un UNION ALL può essere meno efficiente per altri tipi di query, pertanto è necessario valutare le prestazioni delle query nel contesto di tutte le query che utilizzano le tabelle.
