Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Autenticazione con il connettore Spark
Il diagramma seguente descrive l'autenticazione tra Amazon S3, Amazon Redshift, il driver Spark e gli executor Spark.
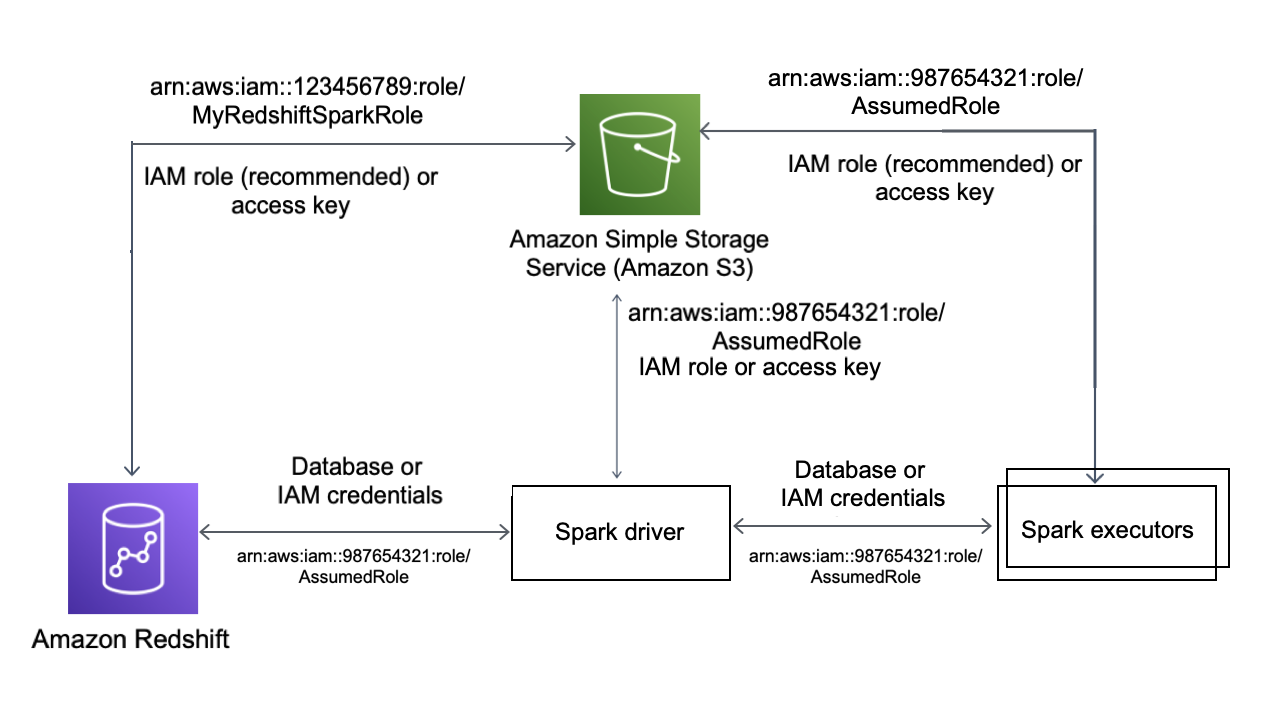
Autenticazione tra Redshift e Spark
Puoi utilizzare il JDBC driver versione 2 fornito da Amazon Redshift per connetterti ad Amazon Redshift con il connettore Spark specificando le credenziali di accesso. Per utilizzarloIAM, configura il tuo URL per utilizzare l'autenticazione. JDBC IAM Per connetterti a un cluster Redshift da Amazon EMR oppure AWS Glue, assicurati che il tuo IAM ruolo disponga delle autorizzazioni necessarie per recuperare le credenziali temporanee. IAM L'elenco seguente descrive tutte le autorizzazioni necessarie al tuo IAM ruolo per recuperare le credenziali ed eseguire le operazioni di Amazon S3.
-
Redshift: GetClusterCredentials (per cluster Redshift con provisioning)
-
Redshift: DescribeClusters (per cluster Redshift con provisioning)
-
Redshift: GetWorkgroup (per gruppi di lavoro Serverless Amazon Redshift)
-
Redshift: GetCredentials (per gruppi di lavoro Serverless Amazon Redshift)
Per ulteriori informazioni su GetClusterCredentials, vedere Politiche relative alle risorse per GetClusterCredentials.
Inoltre, devi assicurarti che Amazon Redshift possa assumere il IAM ruolo durante COPY le UNLOAD operazioni.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Se utilizzi il JDBC driver più recente, il driver gestirà automaticamente la transizione da un certificato autofirmato Amazon Redshift a un certificato. ACM Tuttavia, devi specificare le SSL opzioni nell'URL. JDBC
Di seguito è riportato un esempio di come specificare il JDBC driver URL e aws_iam_role connettersi ad Amazon Redshift.
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Autenticazione tra Amazon S3 e Spark
Se utilizzi un IAM ruolo per l'autenticazione tra Spark e Amazon S3, usa uno dei seguenti metodi:
-
The AWS SDK for Java tenterà automaticamente di trovare AWS le credenziali utilizzando la catena di provider di credenziali predefinita implementata dalla classe D. efaultAWSCredentials ProviderChain Per ulteriori informazioni, consulta Utilizzo della catena di provider delle credenziali predefinita.
-
È possibile specificare AWS le chiavi tramite le proprietà di configurazione di Hadoop
. Ad esempio, se la tua tempdirconfigurazione punta a uns3n://filesystem, imposta lefs.s3n.awsSecretAccessKeyproprietàfs.s3n.awsAccessKeyIdand in un file di configurazione Hadoop o chiamasc.hadoopConfiguration.set()per modificare la XML configurazione Hadoop globale di Spark.
Ad esempio, se utilizzi il file system s3n, aggiungi:
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
Per il file system s3a, aggiungi:
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
Se utilizzi Python, utilizza le seguenti operazioni:
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
tempdirURLCodifica le chiavi di autenticazione in. Ad esempio, URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/dircodifica la coppia di chiavi (ACCESSKEY,SECRETKEY).
Autenticazione tra Redshift e Amazon S3
Se utilizzi UNLOAD i comandi COPY and nella tua query, devi inoltre concedere ad Amazon S3 l'accesso ad Amazon Redshift per eseguire le query per tuo conto. A tale scopo, autorizza innanzitutto Amazon Redshift ad accedere ad AWS altri servizi, quindi autorizza le operazioni UNLOADe le operazioni utilizzando i COPY ruoli. IAM
Come best practice, consigliamo di allegare politiche di autorizzazione a un IAM ruolo e quindi di assegnarlo a utenti e gruppi in base alle esigenze. Per ulteriori informazioni, consulta Identity and access management in Amazon Redshift.
Integrazione con AWS Secrets Manager
Puoi recuperare le credenziali del nome utente e della password di Redshift da un segreto archiviato in AWS Secrets Manager. Per fornire automaticamente le credenziali Redshift, utilizza il parametro secret.id. Per ulteriori informazioni su come creare un segreto per le credenziali Redshift, consulta Creazione di un segreto del database AWS Secrets Manager.
| GroupID | ArtifactID | Revisioni supportate | Descrizione |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | La AWS Secrets Manager SQL Connection Library for Java consente agli sviluppatori Java di connettersi facilmente ai SQL database utilizzando segreti archiviati in. AWS Secrets Manager |
Nota
Questa documentazione contiene codice e linguaggio di esempio sviluppati da Apache Software Foundation
