Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risoluzione dei problemi
Quanto segue FAQs può aiutarti a risolvere i problemi con gli endpoint Amazon Asynchronous SageMaker Inference.
Puoi utilizzare i metodi seguenti per trovare il conteggio istanze del tuo endpoint:
Puoi usare l' SageMaker intelligenza artificiale DescribeEndpointAPIper descrivere il numero di istanze alla base dell'endpoint in un dato momento.
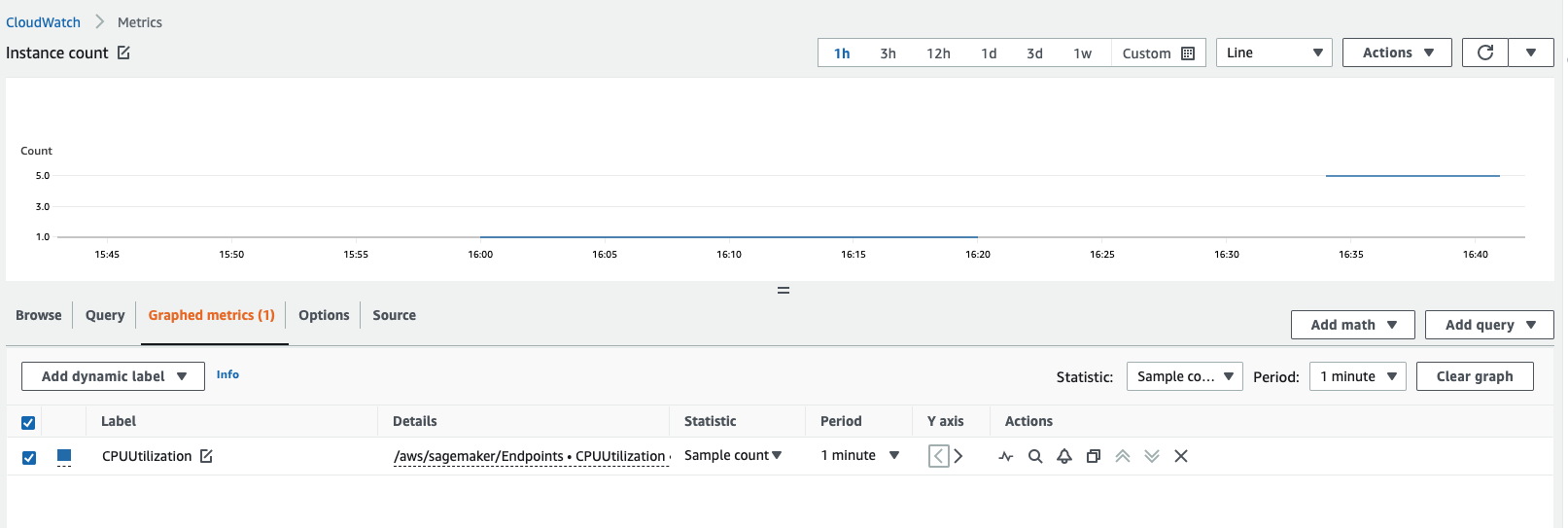
Puoi ottenere il numero di istanze visualizzando i CloudWatch parametri di Amazon. Visualizza i parametri per le tue istanze di endpoint, ad esempio
CPUUtilizationoMemoryUtilizatione controlla la statistica del conteggio di esempio per un periodo di 1 minuto. Il conteggio deve essere uguale al numero di istanze attive. La schermata seguente mostra laCPUUtilizationmetrica rappresentata graficamente nella CloudWatch console, dove la Statistica è impostata suSample count, il Periodo è impostato su e il conteggio1 minuterisultante è 5.
Le tabelle seguenti descrivono le variabili di ambiente regolabili comuni per i contenitori SageMaker AI per tipo di framework.
TensorFlow
| Variabile di ambiente | Descrizione |
|---|---|
|
|
Per i modelli TensorFlow basati, il |
|
|
Questo parametro regola la frazione di memoria disponibile GPU per inizializzare /cu e altre librerie. CUDA DNN GPU |
|
Ciò si ricollega alla variabile |
|
Ciò si ricollega alla variabile |
|
Questo regola il numero di processi di lavoro che Gunicorn deve generare per la gestione delle richieste. Questo valore viene utilizzato in combinazione con altri parametri per ricavare un set che massimizzi la velocità di inferenza. Inoltre, |
|
Questo regola il numero di processi di lavoro che Gunicorn deve generare per la gestione delle richieste. Questo valore viene utilizzato in combinazione con altri parametri per ricavare un set che massimizzi la velocità di inferenza. Inoltre, |
|
Python utilizza internamente OpenMP per implementare il multithreading all'interno dei processi. In genere, vengono generati thread equivalenti al numero di CPU core. Tuttavia, se implementato su Simultaneous Multi Threading (SMT), come quello di Intel HypeThreading, un determinato processo potrebbe superare la sottoscrizione di un particolare core generando il doppio dei thread rispetto al numero di core effettivi. CPU In alcuni casi, un binario Python potrebbe finire per generare fino a quattro volte più thread dei core del processore disponibili. Pertanto, l'impostazione ideale per questo parametro, se avete registrato un numero eccessivo di core disponibili utilizzando i thread di lavoro |
|
|
In alcuni casi, la disattivazione MKL può velocizzare l'inferenza se e sono impostate su. |
PyTorch
| Variabile di ambiente | Descrizione |
|---|---|
|
|
Si tratta del tempo massimo di TorchServe attesa per la ricezione del batch. |
|
|
Se TorchServe non riceve il numero di richieste specificato in |
|
|
Il numero minimo di lavoratori a cui TorchServe è consentito ridurre. |
|
|
Il numero massimo di lavoratori a cui TorchServe è consentito aumentare. |
|
|
Il ritardo temporale, dopo il quale scade l'inferenza in assenza di una risposta. |
|
|
La dimensione massima del carico utile per TorchServe. |
|
|
La dimensione massima di risposta per TorchServe. |
Server multimodello () MMS
| Variabile di ambiente | Descrizione |
|---|---|
|
|
Questo parametro è utile per effettuare la regolazione in uno scenario in cui il tipo di payload della richiesta di inferenza è elevato e, a causa della maggiore dimensione del payload, è possibile che si verifichi un maggiore consumo di memoria nell'heap di quella JVM in cui viene mantenuta questa coda. Idealmente, potresti voler mantenere i requisiti di memoria heap JVM inferiori e consentire ai lavoratori Python di allocare più memoria per l'effettivo servizio del modello. JVMserve solo per ricevere le HTTP richieste, metterle in coda e inviarle ai worker basati su Python per l'inferenza. Se si aumenta il |
|
|
Questo parametro è destinato al servizio del modello di back-end e potrebbe essere utile da ottimizzare poiché questo è il componente fondamentale del servizio complessivo del modello, in base al quale i processi Python generano i thread per ciascun modello. Se questo componente è più lento (o non ottimizzato correttamente), l'ottimizzazione del front-end potrebbe non essere efficace. |
Puoi utilizzare lo stesso container per l'inferenza asincrona utilizzato per l'inferenza in tempo reale o la trasformazione in batch. Devi confermare che i timeout e i limiti di dimensione del payload sul container siano impostati per gestire payload più grandi e timeout più lunghi.
Fai riferimento ai seguenti limiti per l'inferenza asincrona:
Limite di dimensione del payload: 1 GB
Limite di timeout: una richiesta può richiedere fino a 60 minuti.
Messaggio in coda TimeToLive (TTL): 6 ore
Numero di messaggi che possono essere inseriti in AmazonSQS: illimitato. Tuttavia, esiste una quota di 120.000 per il numero di messaggi in volo per una coda standard e di 20.000 per una coda. FIFO
In generale, con l’inferenza asincrona, puoi aumentare orizzontalmente in base a invocazioni o istanze. Per quanto riguarda i parametri di invocazione, è una buona idea consultare ApproximateBacklogSize, che è un parametro che definisce il numero di elementi nella coda che devono ancora essere elaborati. Puoi utilizzare questa metrica o la tua InvocationsPerInstance metrica per capire a cosa potresti essere limitato. TPS A livello di istanza, controlla il tipo di istanza e il relativo GPU utilizzo diCPU/per definire quando effettuare la scalabilità orizzontale. Se un’istanza singola ha una capacità superiore al 60-70%, questo è spesso un buon segno che si sta saturando l'hardware.
Non è consigliabile adottare più policy di dimensionamento, in quanto possono entrare in conflitto e creare confusione a livello hardware, causando ritardi nell’aumento.
Verifica se il tuo contenitore è in grado di gestire le richieste di ping e invocazione contemporaneamente. SageMaker Le richieste di richiamo AI richiedono circa 3 minuti e, in questo periodo, di solito più richieste di ping finiscono per fallire a causa del timeout che causa il rilevamento del container da parte dell' SageMaker IA. Unhealthy
Sì MaxConcurrentInvocationsPerInstance è una funzionalità degli endpoint asincroni. Ciò non dipende dall'implementazione del container personalizzato. MaxConcurrentInvocationsPerInstance controlla la frequenza con cui le richieste di invoca vengono inviate al container del cliente. Se questo valore è impostato su 1, viene inviata solo 1 richiesta alla volta al container, indipendentemente dal numero di worker presenti nel container del cliente.
L'errore indica che il contenitore del cliente ha restituito un errore. SageMaker L'intelligenza artificiale non controlla il comportamento dei container dei clienti. SageMaker L'intelligenza artificiale restituisce semplicemente la risposta da ModelContainer e non riprova. Se lo desideri, puoi configurare l’invocazione per riprovare in caso di errore. Ti consigliamo di attivare la registrazione dei container e di controllarli per trovare la causa principale dell'errore 500 relativo al tuo modello. Controlla anche i parametri CPUUtilization e MemoryUtilization corrispondenti nel punto in cui si è verificato l'errore. Puoi anche configurare S3 in base FailurePath al modello di risposta in Amazon SNS come parte delle notifiche di errore asincrone per indagare sugli errori.
Puoi controllare il parametro InvocationsProcesssed, che dovrebbe essere in linea con il numero di invocazioni che prevedi vengano elaborate in un minuto in base a una singola concorrenza.
La best practice consiste nell'abilitare AmazonSNS, un servizio di notifica per applicazioni orientate alla messaggistica, con più abbonati che richiedono e ricevono notifiche «push» di messaggi urgenti da una scelta di protocolli di trasporto, HTTP tra cui Amazon ed e-mail. SQS Asynchronous Inference pubblica notifiche quando crei un endpoint con e CreateEndpointConfig specifichi un argomento Amazon. SNS
Per utilizzare Amazon SNS per controllare i risultati delle previsioni dal tuo endpoint asincrono, devi prima creare un argomento, iscriverti all'argomento, confermare la tua iscrizione all'argomento e annotare il nome della risorsa Amazon () ARN di quell'argomento. Per informazioni dettagliate su come creare, abbonarsi e trovare l'SNSargomento Amazon ARN di un Amazon, consulta Configuring Amazon SNS nell'Amazon SNS Developer Guide. Per ulteriori informazioni su come usare Amazon SNS con Asynchronous Inference, consulta Verifica i risultati delle previsioni.
Sì. L'inferenza asincrona fornisce un meccanismo per ridurre a zero istanze quando non ci sono richieste. Se l'endpoint è stato ridimensionato a zero istanze durante questi periodi, l'endpoint non aumenterà nuovamente fino a quando il numero di richieste in coda non supererà l'obiettivo specificato nella policy di dimensionamento. Ciò può comportare lunghi tempi di attesa per le richieste in coda. In questi casi, se desideri passare da zero istanze per nuove richieste inferiori all'obiettivo di coda specificato, puoi utilizzare una policy di dimensionamento aggiuntiva denominata HasBacklogWithoutCapacity. Per ulteriori informazioni su come definire questa policy di dimensionamento, consulta Scalabilità automatica di un endpoint asincrono.
Per un elenco completo delle istanze supportate da Asynchronous Inference per regione, consulta i prezzi di AI. SageMaker
