Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurare e avviare il processo di ottimizzazione degli iperparametri
Importante
Le politiche IAM personalizzate che consentono ad Amazon SageMaker Studio o Amazon SageMaker Studio Classic di creare SageMaker risorse Amazon devono inoltre concedere le autorizzazioni per aggiungere tag a tali risorse. L'autorizzazione per aggiungere tag alle risorse è necessaria perché Studio e Studio Classic taggano automaticamente tutte le risorse che creano. Se una policy IAM consente a Studio e Studio Classic di creare risorse ma non consente l'aggiunta di tag, si possono verificare errori AccessDenied "" durante il tentativo di creare risorse. Per ulteriori informazioni, consulta Fornisci le autorizzazioni per SageMaker etichettare le risorse AI.
AWS politiche gestite per Amazon SageMaker AIche danno i permessi per creare SageMaker risorse includono già le autorizzazioni per aggiungere tag durante la creazione di tali risorse.
Un iperparametro è un parametro di alto livello che influenza il processo di addestramento durante l’addestramento del modello. Per ottenere le migliori previsioni del modello, è possibile ottimizzare una configurazione degli iperparametri o impostare valori degli iperparametri. Il processo di ricerca di una configurazione ottimale si chiama ottimizzazione degli iperparametri. Per configurare e avviare un processo di ottimizzazione degli iperparametri, completa le fasi descritte in queste guide.
Argomenti
Impostazioni per il processo di ottimizzazione degli iperparametri
Per specificare le impostazioni per il processo di ottimizzazione degli iperparametri, definisci un oggetto JSON quando crei il processo di ottimizzazione. Passa questo oggetto JSON come valore del parametro HyperParameterTuningJobConfig all'API CreateHyperParameterTuningJob.
In questo oggetto JSON, specifica quanto segue:
In questo oggetto JSON, specifica:
-
HyperParameterTuningJobObjective: il parametro obiettivo utilizzato per valutare le prestazioni del processo di addestramento lanciato dal processo di ottimizzazione degli iperparametri. -
ParameterRanges: l'intervallo di valori che un iperparametro regolabile può utilizzare durante l'ottimizzazione. Per ulteriori informazioni, consulta Definire gli intervalli degli iperparametri -
RandomSeed: un valore usato per inizializzare un generatore di numeri pseudo-casuali. L'impostazione di un seed casuale consentirà alle strategie di ricerca dell'ottimizzazione degli iperparametri di produrre configurazioni più coerenti per lo stesso processo di ottimizzazione (facoltativo). -
ResourceLimits: il numero massimo di processi di addestramento e di addestramento parallelo che il processo di ottimizzazione degli iperparametri può utilizzare.
Nota
Se utilizzi il tuo algoritmo per l'ottimizzazione degli iperparametri, anziché un algoritmo integrato di SageMaker intelligenza artificiale, devi definire le metriche per l'algoritmo. Per ulteriori informazioni, consulta Definizione dei parametri.
Il seguente esempio di codice mostra come configurare un processo di ottimizzazione degli iperparametri utilizzando l'algoritmo integrato. XGBoost L'esempio di codice mostra come definire gli intervalli per gli iperparametri eta, alpha, min_child_weight e max_depth. Per ulteriori informazioni su questi e altri iperparametri, vedete Parametri. XGBoost
In questo esempio di codice, la metrica obiettivo per il processo di ottimizzazione degli iperparametri trova la configurazione iperparametrica che massimizza. validation:auc SageMaker Gli algoritmi integrati nell'intelligenza artificiale scrivono automaticamente la metrica dell'obiettivo in Logs. CloudWatch L'esempio di codice seguente mostra anche come impostare un RandomSeed.
tuning_job_config = { "ParameterRanges": { "CategoricalParameterRanges": [], "ContinuousParameterRanges": [ { "MaxValue": "1", "MinValue": "0", "Name": "eta" }, { "MaxValue": "2", "MinValue": "0", "Name": "alpha" }, { "MaxValue": "10", "MinValue": "1", "Name": "min_child_weight" } ], "IntegerParameterRanges": [ { "MaxValue": "10", "MinValue": "1", "Name": "max_depth" } ] }, "ResourceLimits": { "MaxNumberOfTrainingJobs": 20, "MaxParallelTrainingJobs": 3 }, "Strategy": "Bayesian", "HyperParameterTuningJobObjective": { "MetricName": "validation:auc", "Type": "Maximize" }, "RandomSeed" : 123 }
Configurare i processi di addestramento
Il processo di ottimizzazione degli iperparametri avvierà processi di addestramento per trovare una configurazione ottimale degli iperparametri. Questi lavori di formazione devono essere configurati utilizzando l' SageMaker API AI. CreateHyperParameterTuningJob
Per configurare i processi di addestramento, definisci un oggetto JSON e passalo come valore del parametro TrainingJobDefinition dentro CreateHyperParameterTuningJob.
In questo oggetto JSON, puoi specificare quanto segue:
-
AlgorithmSpecification: il percorso di registro dell'immagine Docker contenente l'algoritmo di addestramento e i relativi metadati. Per specificare un algoritmo, puoi utilizzare il tuo algoritmo personalizzato all'interno di un contenitore Dockero un algoritmo integrato SageMaker AI (richiesto). -
InputDataConfig: la configurazione di input, inclusoChannelName,ContentTypee l’origine dati dei dati di addestramento e test (obbligatorio). -
InputDataConfig: la configurazione di input, inclusoChannelName,ContentTypee l’origine dati dei dati di addestramento e test (obbligatorio). -
Il percorso di storage per l'output dell'algoritmo. Specifica il bucket S3 in cui archiviare l'output dei processi di addestramento.
-
RoleArn— L'Amazon Resource Name (ARN) di un ruolo AWS Identity and Access Management (IAM) utilizzato dall' SageMaker IA per eseguire attività. Le attività includono la lettura dei dati di input, il download di un'immagine Docker, la scrittura di artefatti del modello in un bucket S3, la scrittura di log su Amazon Logs e la scrittura di metriche su Amazon CloudWatch (obbligatorio). CloudWatch -
StoppingCondition: il tempo massimo di esecuzione, in secondi, che un processo di training può eseguire prima di essere interrotto. Questo valore deve essere maggiore del tempo necessario per addestrare il modello (obbligatorio). -
MetricDefinitions: il nome e l'espressione regolare che definiscono tutti i parametri emessi dai processi di addestramento. Definisci i parametri solo quando utilizzi un algoritmo di addestramento personalizzato. L'esempio riportato nel codice seguente utilizza un algoritmo integrato, che ha già definito i parametri. Per informazioni sulla definizione dei parametri (facoltativo), consulta Definizione dei parametri. -
TrainingImage: l'immagine del container Dockerche specifica l'algoritmo di addestramento (facoltativo). -
StaticHyperParameters: i valori degli iperparametri dell'algoritmo che non sono ottimizzati nel processo di ottimizzazione (facoltativo).
Il seguente codice di esempio imposta valori statici per i parametri eval_metric, num_round, objective, rate_drop e tweedie_variance_power dell'algoritmo integrato XGBoost algoritmo con Amazon SageMaker AI.
Assegnare un nome e avviare il processo di ottimizzazione degli iperparametri
Dopo aver configurato il processo di ottimizzazione degli iperparametri, puoi lanciarlo chiamando l'API CreateHyperParameterTuningJob. Il codice di esempio seguente usa tuning_job_config e training_job_definition. Questi sono stati definiti nei due esempi di codice precedenti per creare un processo di ottimizzazione degli iperparametri.
tuning_job_name = "MyTuningJob" smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name, HyperParameterTuningJobConfig = tuning_job_config, TrainingJobDefinition = training_job_definition)
Visualizzare lo stato dei processi di addestramento
Per visualizzare lo stato dei processi di addestramento avviati dal processo di ottimizzazione iperparametri
-
Nell'elenco dei processi di ottimizzazione degli iperparametri, scegliere il processo avviato.
-
Scegliere Processi di addestramento.
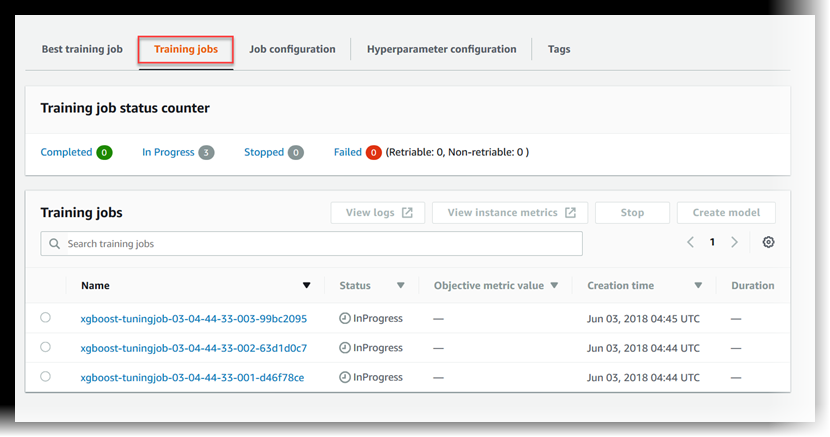
-
Visualizzare lo stato di ogni processo di addestramento. Per visualizzare ulteriori dettagli su un processo, sceglierlo nell'elenco dei processi di addestramento. Per visualizzare un riepilogo dello stato di tutti i processi di addestramento avviati dal processo di ottimizzazione degli iperparametri, consulta Training job status counter.
Un processo di addestramento può essere:
-
Completed: il processo di addestramento è stato completato con successo. -
InProgress: il processo di addestramento è in corso. -
Stopped: il processo di addestramento è stato interrotto manualmente prima del suo completamento. -
Failed (Retryable): il processo di addestramento non è riuscito, ma può essere riprovato. Un processo di addestramento non riuscito può essere ritentato solo se il mancato completamento è dipeso da un errore interno del servizio. -
Failed (Non-retryable): il processo di addestramento non è riuscito e non può essere riprovato. Un processo di addestramento non riuscito non può essere rieseguito quando si verifica errore del client.
Nota
I processi di ottimizzazione degli iperparametri possono essere interrotti e le risorse sottostanti eliminate, ma i processi stessi non possono essere eliminati.
-
Visualizzare il processo di addestramento migliore
Un processo di ottimizzazione degli iperparametri utilizza il parametro obiettivo restituito da ogni processo di addestramento per valutare i processi di addestramento. Mentre il processo di ottimizzazione degli iperparametri è in corso, il processo di addestramento migliore è quello che ha restituito il miglior parametro obiettivo fino a quel momento. Una volta completato il processo di ottimizzazione degli iperparametri, il processo di addestramento migliore è quello che ha restituito il miglior parametro obiettivo.
Per visualizzare il processo di addestramento migliore, scegli Processo di addestramento migliore.

Per implementare il miglior processo di formazione come modello da ospitare su un endpoint di SageMaker intelligenza artificiale, scegli Crea modello.
Fase succcessiva
