Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Associazione dei risultati delle previsioni ai record di input
Quando si creano previsioni su un set di dati di grandi dimensioni, è possibile escludere gli attributi non necessari per la previsione. Una volta create le previsioni, è possibile associare alcuni attributi esclusi a tali previsioni o ad altri dati di input nel report. Usando la trasformazione in batch per eseguire queste fasi di elaborazione dei dati, spesso è possibile eliminare operazioni aggiuntive di preelaborazione o postelaborazione. Si possono utilizzare file di input solo in formato JSON e CSV.
Argomenti
Flusso di lavoro per associare le inferenze ai record di input
Il seguente diagramma mostra il flusso di lavoro per associare le inferenze ai record di input.
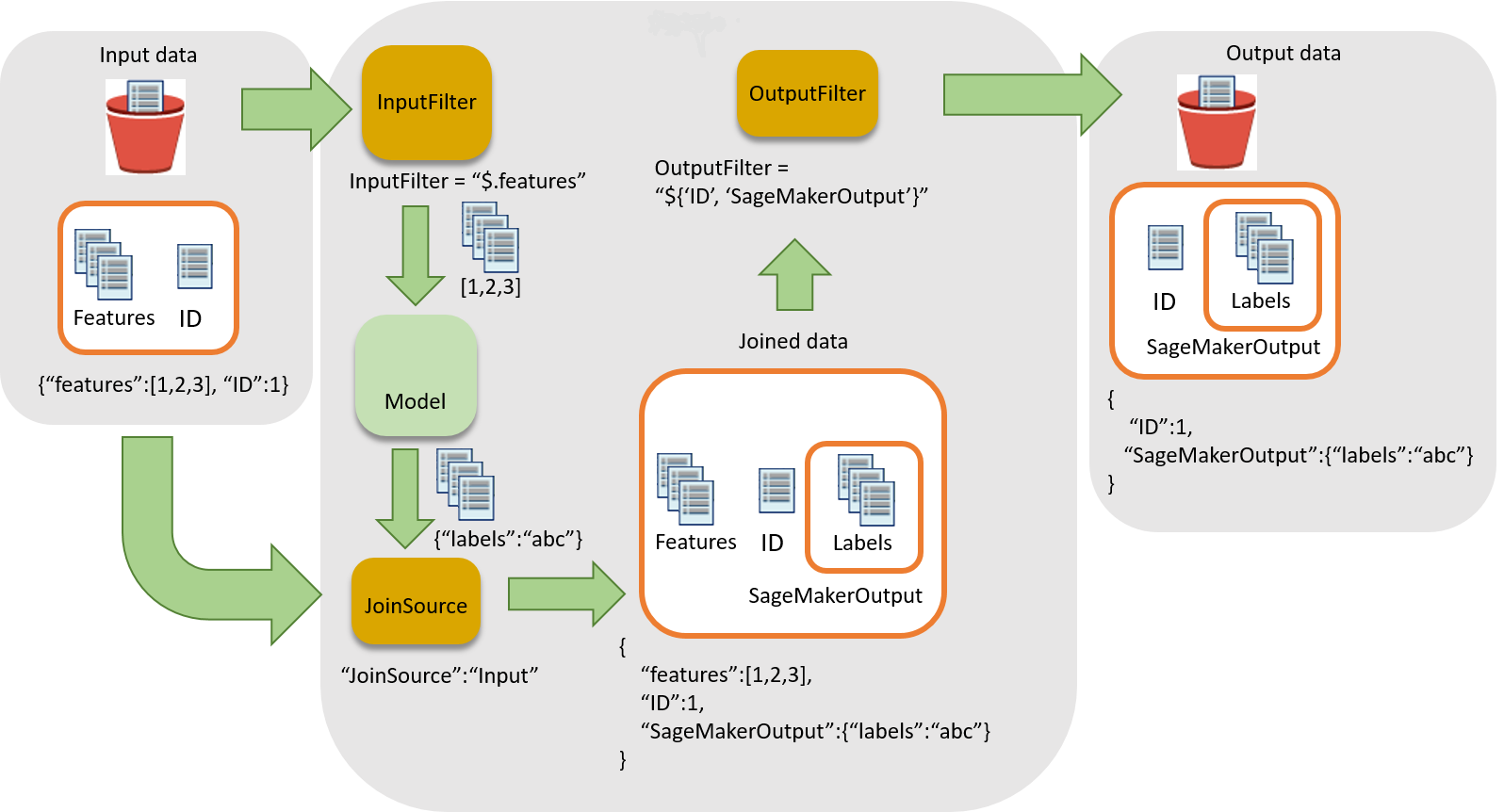
L'associazione delle inferenze ai dati di input prevede tre fasi:
-
Filtrare i dati di input non necessari per l'inferenza prima di passarli al processo di trasformazione in batch. Utilizzare il parametro
InputFilterper determinare quali attributi utilizzare come input per il modello. -
Associare i dati di input ai risultati dell'inferenza. Utilizzare il parametro
JoinSourceper combinare i dati di input con l'inferenza. -
Filtrare i dati collegati per mantenere gli input necessari a fornire un contesto per l'interpretazione delle previsioni nei report. Utilizzare
OutputFilterper archiviare la porzione specificata del set di dati completo nel file di output.
Utilizzare l'elaborazione dati nei processi di trasformazione in batch
Per elaborare i dati durante la creazione di un processo di trasformazione in batch con CreateTransformJob:
-
Specificare la porzione di input da passare al modello con il parametro
InputFilternella struttura datiDataProcessing. -
Collegare i dati di input grezzi ai dati trasformati con il parametro
JoinSource. -
Specificare quale porzione dell'input collegato e dei dati trasformati dal processo di trasformazione in batch includere nel file di output con il parametro
OutputFilter. -
Scegli tra JSON o CSV-formatted file per l'input:
-
Per i file di Lines-formatted input JSON o JSON, SageMaker AI aggiunge l'
SageMakerOutputattributo al file di input o crea un nuovo file di output JSON con gli attributi and.SageMakerInputSageMakerOutputPer ulteriori informazioni, consultaDataProcessing. -
Per i file CSV-formatted di input, i dati di input uniti sono seguiti dai dati trasformati e l'output è un file CSV.
-
Se si utilizza un algoritmo con la struttura DataProcessing, è necessario che supporti il formato scelto sia per i file di input che per quelli di output. Ad esempio, con il campo TransformOutput dell'API CreateTransformJob, è necessario impostare entrambi i parametri ContentType e Accept su uno dei seguenti valori: text/csv, application/json o application/jsonlines. La sintassi per specificare le colonne in un file CSV e quella per specificare gli attributi in un file JSON sono diverse. L'utilizzo della sintassi sbagliata genera un errore. Per ulteriori informazioni, consulta Esempi di trasformazione in batch. Per ulteriori informazioni sui formati di file di input e output per gli algoritmi integrati, consulta Built-in algoritmi e modelli preaddestrati in Amazon SageMaker.
Anche i delimitatori di record per l'input e l'output devono essere coerenti con il file di input scelto. Il parametro SplitType indica come suddividere i record nel set di dati di input. Il parametro AssembleWith indica come riassemblare i record dell'output. Se si impostano i formati in ingresso e in uscita a text/csv, è necessario anche impostare i parametri SplitType e AssembleWith al valore line. Se si impostano i formati in ingresso e in uscita a application/jsonlines, è possibile impostare i parametri SplitType e AssembleWith su line.
Per i file CSV, non è possibile utilizzare caratteri di nuova riga incorporati. In caso di file JSON, nel file di output il nome dell'attributo SageMakerOutput è riservato. Il file di input JSON non può contenere un attributo con questo nome. In caso contrario, i dati del file di input potrebbero essere sovrascritti.
Operatori JSONPath supportati
Per filtrare e collegare i dati di input e le inferenze, utilizzare una sottoespressione JSONPath. SageMaker L'IA supporta solo un sottoinsieme degli operatori JsonPath definiti. La tabella seguente elenca gli operatori JSONPath supportati. Per i dati CSV, ogni riga viene presa come un array JSON, quindi è possibile applicare solo JSONPath basato sugli indici, ad esempio $[0], $[1:]. I dati CSV dovrebbero anche seguire il formato RFC
| Operatore JSONPath | Description | Esempio |
|---|---|---|
$ |
L'elemento radice di una query. Questo operatore è obbligatorio all'inizio di ogni espressione di percorso. |
$ |
. |
Un elemento figlio in notazione "a punto". |
|
* |
Carattere jolly Utilizzato al posto di un nome di attributo o di un valore numerico. |
|
[' |
Un elemento o molteplici elementi figli in notazione "a parentesi graffa". |
|
[ |
Un indice o una matrice di indici. Sono supportati anche valori di indice negativi. L'indice |
|
[ |
Un operatore di sezionamento della matrice. Il metodo array slice () estrae una sezione di un array e restituisce un nuovo array. Se ometti |
|
Quando si utilizza la notazione in parentesi per specificare più elementi figlio di un dato del campo, l'ulteriore nidificazione di elementi secondari tra parentesi non è supportata. Ad esempio, $.field1.['child1','child2'] è supportato mentre non lo è $.field1.['child1','child2.grandchild'].
Per ulteriori informazioni sugli operatori JsonPath, consulta on. JsonPath
Esempi di trasformazione in batch
I seguenti esempi mostrano alcune procedure comuni per collegare i dati di input con i risultati della predizione.
Argomenti
Esempio: generazione solo di inferenze
Per impostazione predefinita, il parametro DataProcessing non collega i risultati dell'inferenza all'input. Genera solo i risultati dell'inferenza come output.
Se desideri specificare in modo esplicito di non unire i risultati con l'input, usa l'SDK Amazon SageMaker Python
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
Per generare inferenze utilizzando l' AWS SDK per Python, aggiungi il codice seguente alla tua richiesta. CreateTransformJob Il codice seguente mostra il comportamento predefinito.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Esempio: inferenze di uscita collegate a dati di input
Se utilizzi l'SDK Amazon SageMaker Pythonaccept parametri assemble_with and durante l'inizializzazione dell'oggetto transformer. Quando utilizzi la chiamata di trasformazione, specifica Input per il parametro join_source e specifica anche i parametri split_type e content_type. Il parametro split_type deve avere lo stesso valore di assemble_with e il parametro content_type deve avere lo stesso valore di accept. Per ulteriori informazioni sui parametri e sui relativi valori accettati, consulta la pagina Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
Se stai usando l' AWS SDK per Python (Boto 3), unisci tutti i dati di input con l'inferenza aggiungendo il codice seguente alla tua richiesta. CreateTransformJob Devono corrispondere i valori per Accept e ContentType come pure i valori per AssembleWith e SplitType.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Per i file di input JSON o JSON Lines, i risultati sono contenuti all'interno della chiave SageMakerOutput nel file di input JSON. Ad esempio, se il file di input è un file JSON che contiene la coppia chiave-valore {"key":1}, il risultato della trasformazione dei dati potrebbe essere {"label":1}.
SageMaker AI li memorizza entrambi nel file di input della chiave. SageMakerInput
{ "key":1, "SageMakerOutput":{"label":1} }
Nota
Il risultato del collegamento per il file JSON deve essere un oggetto composto da una coppia chiave-valore. Se l'input non è un oggetto di coppia chiave-valore, SageMaker AI crea un nuovo file JSON. Nel nuovo file JSON, i dati di input vengono memorizzati nella chiave SageMakerInput e i risultati vengono memorizzati come valore di SageMakerOutput.
In caso di file CSV, ad esempio, se il record è [1,2,3] e l'etichetta risultante è [1], il file di output conterrà [1,2,3,1].
Esempio: genera inferenze collegate ai dati di input ed esclude la colonna ID dall'input (CSV)
Se utilizzi l'SDK Amazon SageMaker Pythoninput_filter Ad esempio, se i dati di input includono cinque colonne e la prima è la colonna ID, usa la seguente richiesta di trasformazione per selezionare tutte le colonne tranne la colonna ID come caratteristiche. Il trasformatore genera in uscita comunque tutte le colonne di input collegate alle inferenze. Per ulteriori informazioni sui parametri e sui relativi valori accettati, consulta la pagina Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
Se stai usando l' AWS SDK per Python (Boto 3), aggiungi il codice seguente alla tua richiesta.
CreateTransformJob
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Per specificare le colonne in SageMaker AI, usa l'indice degli elementi dell'array. La prima colonna è l'indice 0, la seconda colonna è l'indice 1 e la sesta colonna è l'indice 5.
Per escludere la prima colonna dall'input, imposta InputFilter su "$[1:]". I due punti (:) indicano all' SageMaker IA di includere tutti gli elementi tra due valori, inclusi. Ad esempio, $[1:4] specifica dalla seconda alla quinta colonna.
Se si omette il numero dopo i due punti, ad esempio [5:], il sottoinsieme include tutte le colonne dalla sesta fino all'ultima. Se si omette il numero prima dei due punti, ad esempio [:5], il sottoinsieme include tutte le colonne dalla prima colonna (indice 0) alla sesta colonna.
Esempio: inferenze di output collegate a una colonna ID ed esclusione della colonna ID dall'input (CSV)
Se utilizzi l'SDK Amazon SageMaker Pythonoutput_filter output_filter utilizza una sottoespressione JSONPath per specificare quali colonne restituire come output dopo aver collegato i dati di input ai risultati dell'inferenza. La richiesta seguente mostra come è possibile fare previsioni escludendo una colonna ID e quindi collegare la colonna ID alle inferenze. Nota che nell'esempio seguente, l'ultima colonna (-1) dell'output contiene le inferenze. Se utilizzi file JSON, SageMaker AI memorizza i risultati dell'inferenza nell'attributo. SageMakerOutput Per ulteriori informazioni sui parametri e sui relativi valori accettati, consulta la pagina Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
Se stai usando l' AWS SDK per Python (Boto 3), unisci solo la colonna ID con le inferenze aggiungendo il seguente codice alla tua richiesta. CreateTransformJob
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
avvertimento
Se stai usando un file di JSON-formatted input, il file non può contenere il nome dell'attributo. SageMakerOutput Questo nome di attributo è riservato per le inferenze nel file di output. Se il file JSON-formatted di input contiene un attributo con questo nome, i valori nel file di input potrebbero essere sovrascritti dall'inferenza.
