Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risultati dell'analisi
Al termine di un processo di elaborazione di SageMaker Clarify, è possibile scaricare i file di output per esaminarli oppure visualizzare i risultati in Studio Classic. SageMaker L'argomento seguente descrive i risultati dell'analisi generati da SageMaker Clarify, ad esempio lo schema e il report generati dall'analisi dei pregiudizi, dall'analisi, dall'analisi della spiegabilità della visione artificiale e dall'SHAPanalisi dei grafici di dipendenza parziali (). PDPs Se l'analisi della configurazione contiene parametri per calcolare più analisi, i risultati vengono aggregati in un'unica analisi e in un unico file di report.
La directory di output del processo di elaborazione di SageMaker Clarify contiene i seguenti file:
-
analysis.json— Un file che contiene le metriche di distorsione e l'importanza delle funzionalità nel formato. JSON -
report.ipynb: un notebook statico che contiene codice per aiutarti a visualizzare le metriche di bias e l'importanza della funzionalità. -
explanations_shap/out.csv: una directory creata che contiene file generati automaticamente in base alle configurazioni di analisi specifiche dell'utente. Ad esempio, se si attiva ilsave_local_shap_valuesparametro, i SHAP valori locali per istanza verranno salvati nella directory.explanations_shapCome altro esempio, seanalysis configurationnon contiene un valore per il parametro di SHAP base, il job di spiegabilità di SageMaker Clarify calcola una linea di base raggruppando il set di dati di input. Quindi salva la linea di base generata nella directory.
Per informazioni più dettagliate, consultate le seguenti sezioni.
Argomenti
Analisi dei bias
Amazon SageMaker Clarify utilizza la terminologia documentata in Amazon SageMaker chiarisce i termini relativi a parzialità ed equità per discutere di pregiudizi e correttezza.
Schema per il file di analisi
Il file di analisi è in JSON formato ed è organizzato in due sezioni: metriche dei pregiudizi prima dell'allenamento e metriche dei pregiudizi post-allenamento. I parametri per le metriche di bias pre-addestramento e post-addestramento sono i seguenti.
-
pre_training_bias_metrics: parametri per le metriche di bias pre-addestramento. Per ulteriori informazioni, consulta Metriche di bias pre-addestramento e File di configurazione dell'analisi.
-
label: il nome dell'etichetta ground truth definita dal parametro
labeldella configurazione dell'analisi. -
label_value_or_threshold: una stringa contenente i valori delle etichette o l'intervallo definito dal parametro
label_values_or_thresholddella configurazione dell'analisi. Ad esempio, se il valore1viene fornito per un problema di classificazione binaria, la stringa sarà1. Se vengono forniti più valori[1,2]per un problema multiclasse, la stringa sarà1,2. Se viene fornita una soglia40per un problema di regressione, la stringa sarà interna come(40, 68]in cui68è il valore massimo dell'etichetta nel set di dati di input. -
facets: la sezione contiene diverse coppie chiave-valore, in cui la chiave corrisponde al nome del facet definito dal parametro
name_or_indexdella configurazione del facet e il valore è una matrice di oggetti facet. Ciascun oggetto facet presenta i seguenti membri:-
value_or_threshold: una stringa contenente i valori del facet o l'intervallo definito dal parametro
value_or_thresholddella configurazione del facet. -
metrics: la sezione contiene una matrice di elementi metrica di bias e ogni elemento metrica di bias ha i seguenti attributi:
-
name: il nome breve della metrica di bias. Ad esempio
CI. -
description: il nome completo della metrica di bias. Ad esempio
Class Imbalance (CI). -
valore: il valore della metrica di distorsione o il valore JSON nullo se la metrica di distorsione non viene calcolata per un motivo particolare. I valori ±∞ sono rappresentati rispettivamente come stringhe
∞e-∞. -
error: un messaggio di errore opzionale che spiega perché la metrica di bias non è stata calcolata.
-
-
-
-
post_training_bias_metrics: la sezione contiene le metriche di bias post-addestramento e segue un layout e una struttura simili a quelli della sezione pre-addestramento. Per ulteriori informazioni, consulta Dati post-allenamento e metriche di distorsione dei modelli.
Di seguito è riportato un esempio di configurazione dell'analisi che calcolerà le metriche di bias pre- e post-addestramento.
{ "version": "1.0", "pre_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "CDDL", "description": "Conditional Demographic Disparity in Labels (CDDL)", "value": -0.06 }, { "name": "CI", "description": "Class Imbalance (CI)", "value": 0.6 }, ... ] }] } }, "post_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "AD", "description": "Accuracy Difference (AD)", "value": -0.13 }, { "name": "CDDPL", "description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)", "value": 0.04 }, ... ] }] } } }
Report di analisi dei bias
Il report di analisi dei bias include diverse tabelle e diagrammi che contengono spiegazioni e descrizioni dettagliate. Questi includono, a titolo esemplificativo, la distribuzione dei valori delle etichette, la distribuzione dei valori di facet, il diagramma delle prestazioni del modello di alto livello, una tabella delle metriche di bias e le relative descrizioni. Per ulteriori informazioni sulle metriche di distorsione e su come interpretarle, consulta la sezione Scopri come Amazon SageMaker Clarify aiuta a
SHAPanalisi
SageMaker I processi di elaborazione di Clarify utilizzano l'SHAPalgoritmo Kernel per calcolare le attribuzioni delle funzionalità. Il processo di elaborazione SageMaker Clarify produce valori sia locali che globali. SHAP Questi aiutano a determinare il contributo di ciascuna funzionalità alle previsioni dei modelli. SHAPI valori locali rappresentano l'importanza delle funzionalità per ogni singola istanza, mentre SHAP i valori globali aggregano i SHAP valori locali in tutte le istanze del set di dati. Per ulteriori informazioni sui SHAP valori e su come interpretarli, consulta. Caratterizzazione delle attribuzioni che utilizzano i valori Shapley
Schema per il file di SHAP analisi
I risultati SHAP dell'analisi globale vengono memorizzati nella sezione delle spiegazioni del file di analisi, sotto il kernel_shap metodo. I diversi parametri del file di SHAP analisi sono i seguenti:
-
explanations: la sezione del file di analisi che contiene i risultati dell'analisi dell'importanza della funzionalità.
-
kernal_shap — La sezione del file di analisi che contiene il risultato dell'analisi globale. SHAP
-
global_shap_values: una sezione del file di analisi che contiene diverse coppie chiave-valore. Ogni chiave nella coppia chiave-valore rappresenta un nome di funzionalità dal set di dati di input. Ogni valore nella coppia chiave-valore corrisponde al valore globale della feature. SHAP Il SHAP valore globale si ottiene aggregando i SHAP valori per istanza della funzionalità utilizzando la configurazione.
agg_methodSe la configurazioneuse_logitè attivata, il valore viene calcolato utilizzando i coefficienti di regressione logistica, che possono essere interpretati come rapporti log-odds. -
expected_value: la previsione media del set di dati di base. Se la configurazione
use_logitè attivata, il valore viene calcolato utilizzando i coefficienti di regressione logistica. -
global_top_shap_text — Utilizzato per l'analisi della spiegabilità. NLP Una sezione del file di analisi che include un set di coppie chiave-valore. SageMaker I processi di elaborazione di Clarify aggregano i SHAP valori di ciascun token e quindi selezionano i token migliori in base ai rispettivi valori globali. SHAP La configurazione
max_top_tokensdefinisce il numero di token da selezionare.Ognuno dei token principali selezionati ha una coppia chiave-valore. La chiave nella coppia chiave-valore corrisponde al nome della funzionalità testuale di un token principale. Ogni valore nella coppia chiave-valore è il SHAP valore globale del token principale. Per un esempio di coppia
global_top_shap_textchiave-valore, vedete il seguente output.
-
-
L'esempio seguente mostra l'output dell'SHAPanalisi di un set di dati tabulare.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Age": 0.022486410860333206, "Gender": 0.007381025261958729, "Income": 0.006843906804137847, "Occupation": 0.006843906804137847, ... }, "expected_value": 0.508233428001 } } } }
L'esempio seguente mostra l'output dell'SHAPanalisi di un set di dati di testo. L'output corrispondente alla colonna Comments è un esempio di output generato dopo l'analisi di una funzionalità testuale.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Rating": 0.022486410860333206, "Comments": 0.058612104851485144, ... }, "expected_value": 0.46700941970297033, "global_top_shap_text": { "charming": 0.04127962903247833, "brilliant": 0.02450240786522321, "enjoyable": 0.024093569652715457, ... } } } } }
Schema per il file di base generato
Quando non viene fornita una configurazione di SHAP base, il processo di elaborazione SageMaker Clarify genera un set di dati di base. SageMaker Clarify utilizza un algoritmo di clustering basato sulla distanza per generare un set di dati di base dai cluster creati dal set di dati di input. Il set di dati di base risultante viene salvato in un file, situato in. CSV explanations_shap/baseline.csv Questo file di output contiene una riga di intestazione e diverse istanze basate sul parametro num_clusters specificato nella configurazione dell'analisi. Il set di dati di base è costituito solo da colonne di funzionalità. L'esempio seguente mostra una linea di base creata raggruppando il set di dati di input.
Age,Gender,Income,Occupation 35,0,2883,1 40,1,6178,2 42,0,4621,0
Schema per i SHAP valori locali derivanti dall'analisi della spiegabilità dei set di dati tabulari
Per i set di dati tabulari, se viene utilizzata una singola istanza di calcolo, il processo di elaborazione SageMaker Clarify salva i valori locali in un file denominato. SHAP CSV explanations_shap/out.csv Se si utilizzano più istanze di calcolo, i SHAP valori locali vengono salvati in diversi file nella directory. CSV explanations_shap
Un file di output contenente SHAP valori locali ha una riga contenente i SHAP valori locali per ogni colonna definita dalle intestazioni. Le intestazioni seguono la convenzione di denominazione Feature_Label, nella quale al nome della funzionalità viene aggiunto un trattino basso, seguito dal nome della variabile di destinazione.
Per problemi multiclasse, i nomi delle funzionalità nell'intestazione variano prima, poi le etichette. Ad esempio, due funzionalità F1, F2 e due classi L1 e L2, nelle intestazioni sono F1_L1, F2_L1, F1_L2 e F2_L2. Se la configurazione dell'analisi contiene un valore per il parametro joinsource_name_or_index, la colonna della chiave utilizzata nella join viene aggiunta alla fine del nome dell'intestazione. Ciò consente la mappatura dei SHAP valori locali alle istanze del set di dati di input. Segue un esempio di file di output contenente SHAP valori.
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
Schema per SHAP i valori locali derivanti dall'analisi della NLP spiegabilità
Per l'analisi della NLP spiegabilità, se viene utilizzata una singola istanza di calcolo, il processo di elaborazione SageMaker Clarify salva i SHAP valori locali in un file Lines denominato. JSON explanations_shap/out.jsonl Se si utilizzano più istanze di calcolo, i SHAP valori locali vengono salvati in diversi JSON file Lines nella directory. explanations_shap
Ogni file contenente SHAP valori locali ha diverse righe di dati e ogni riga è un oggetto validoJSON. L'JSONoggetto ha i seguenti attributi:
-
spiegazioni — La sezione del file di analisi che contiene una serie di SHAP spiegazioni del kernel per una singola istanza. Ciascun elemento della matrice dispone dei seguenti membri:
-
feature_name: il nome dell'intestazione delle funzionalità fornite dalla configurazione delle intestazioni.
-
data_type — Il tipo di funzionalità dedotto dal processo di elaborazione di Clarify. SageMaker I valori validi per le funzionalità testuali includono
numerical,categoricalefree_text(per le funzionalità testuali). -
attributions: una matrice di oggetti di attribuzione specifici per una funzionalità. Una funzionalità testuale può avere più oggetti di attribuzione, ciascuno per un'unità definita dalla configurazione
granularity. L'oggetto attribuzione ha i seguenti membri:-
attribution: una matrice di valori di probabilità specifica per classe.
-
description: (per le funzionalità testuali) la descrizione delle unità di testo.
-
partial_text — La parte del testo spiegata dal processo di elaborazione di Clarify. SageMaker
-
start_idx: un indice a base zero per identificare la posizione della matrice che indica l'inizio del frammento di testo parziale.
-
-
-
Di seguito è riportato un esempio di una singola riga di un file di SHAP valori locali, abbellita per migliorarne la leggibilità.
{ "explanations": [ { "feature_name": "Rating", "data_type": "categorical", "attributions": [ { "attribution": [0.00342270632248735] } ] }, { "feature_name": "Comments", "data_type": "free_text", "attributions": [ { "attribution": [0.005260534499999983], "description": { "partial_text": "It's", "start_idx": 0 } }, { "attribution": [0.00424190349999996], "description": { "partial_text": "a", "start_idx": 5 } }, { "attribution": [0.010247314500000014], "description": { "partial_text": "good", "start_idx": 6 } }, { "attribution": [0.006148907500000005], "description": { "partial_text": "product", "start_idx": 10 } } ] } ] }
SHAPrapporto di analisi
Il rapporto di SHAP analisi fornisce un grafico a barre con un massimo di SHAP valori globali 10 principali. Il seguente esempio di grafico mostra i SHAP valori per le 4 funzionalità principali.
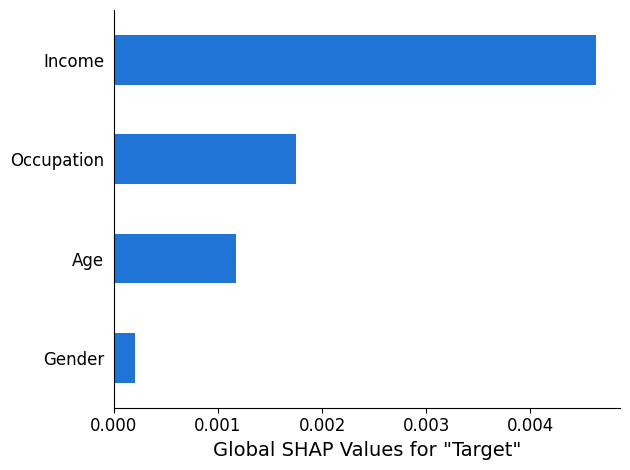
Analisi della spiegabilità della visione artificiale (CV)
SageMaker Clarify Computer Vision Explainability utilizza un set di dati composto da immagini e tratta ogni immagine come una raccolta di super pixel. Dopo l'analisi, il processo di elaborazione di SageMaker Clarify genera un set di dati di immagini in cui ogni immagine mostra la mappa termica dei super pixel.
L'esempio seguente mostra un segno di limite di velocità di ingresso sulla sinistra e una mappa termica mostra l'entità dei SHAP valori sulla destra. Questi SHAP valori sono stati calcolati da un modello Resnet-18 di riconoscimento delle immagini addestrato a riconoscere i segnali stradali tedeschi

Per ulteriori informazioni, consulta i taccuini di esempio Explaining Image Classification with SageMaker Clarify e Explaining object detection
PDPsAnalisi dei grafici di dipendenza parziale ()
I grafici di dipendenza parziale mostrano la dipendenza della risposta della destinazione prevista da una serie di funzionalità di input di interesse. Queste sono marginalizzate rispetto ai valori di tutte le altre funzionalità di input e vengono chiamate funzionalità complementari. In modo intuitivo, è possibile interpretare la dipendenza parziale come la risposta della destinazione, che è attesa come una funzione di ciascuna funzionalità di input di interesse.
Schema per il file di analisi
I PDP valori vengono memorizzati nella explanations sezione del file di analisi sotto il pdp metodo. I parametri per explanations sono come riportato di seguito:
-
explanations: la sezione dei file di analisi che contiene i risultati dell'analisi dell'importanza della funzionalità.
-
pdp — La sezione del file di analisi che contiene una serie di PDP spiegazioni per una singola istanza. Ciascun elemento della matrice dispone dei seguenti membri:
-
feature_name: il nome dell'intestazione delle funzionalità fornite dalla configurazione
headers. -
data_type — Il tipo di funzionalità dedotto dal processo di elaborazione di Clarify. SageMaker I valori validi per
data_typeincludono valori numerici e categorici. -
feature_values: contiene i valori presenti nella funzionalità. Se quello
data_typededotto da SageMaker Clarify è categorico,feature_valuescontiene tutti i valori univoci che potrebbe essere la funzionalità. Se quellodata_typededotto da SageMaker Clarify è numerico,feature_valuescontiene un elenco del valore centrale dei bucket generati. Il parametrogrid_resolutiondetermina il numero di bucket utilizzati per raggruppare i valori di colonna delle funzionalità. -
data_distribution: una matrice di percentuali, in cui ogni valore è la percentuale di istanze contenute in un bucket. Il parametro
grid_resolutiondetermina il numero di bucket. I valori di colonna delle funzionalità sono raggruppati in questi bucket. -
model_predictions: una matrice di previsioni del modello, in cui ogni elemento è una matrice di previsioni che corrisponde a una classe nell'output del modello.
label_headers: le intestazioni delle etichette fornite dalla configurazione
label_headers. -
error — Un messaggio di errore generato se i PDP valori non vengono calcolati per un motivo particolare. Questo messaggio di errore sostituisce il contenuto nei campi
feature_values,data_distributionsemodel_predictions.
-
-
Di seguito è riportato un esempio di output da un file di analisi contenente un risultato PDP dell'analisi.
{ "version": "1.0", "explanations": { "pdp": [ { "feature_name": "Income", "data_type": "numerical", "feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1], "data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01], "model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]], "label_headers": ["Target"] }, ... ] } }
PDPrapporto di analisi
È possibile generare un rapporto di analisi contenente un PDP grafico per ogni feature. Il PDP grafico viene tracciato feature_values lungo l'asse x e model_predictions lungo l'asse y. Per i modelli multiclasse, model_predictions è una matrice e ogni elemento di questa matrice corrisponde a una delle classi di previsione del modello.
Di seguito è riportato un esempio di PDP grafico relativo alla feature. Age Nell'output di esempio, PDP mostra il numero di valori delle funzionalità raggruppati in secchi. Il numero di bucket è determinato da grid_resolution. I bucket di valori delle funzionalità vengono tracciati sulla base delle previsioni del modello. In questo esempio, i valori più alti delle funzionalità hanno gli stessi valori di previsione del modello.

Valori asimmetrici di Shapley
SageMaker I processi di elaborazione di Clarify utilizzano l'algoritmo di valori asimmetrico di Shapley per calcolare le attribuzioni delle spiegazioni dei modelli di previsione delle serie temporali. Questo algoritmo determina il contributo delle funzionalità di input in ogni fase temporale verso le previsioni previste.
Schema per il file di analisi asimmetrico dei valori Shapley
I risultati asimmetrici del valore Shapley vengono archiviati in un bucket Amazon S3. Puoi trovare la posizione di questo bucket nelle spiegazioni della sezione del file di analisi. Questa sezione contiene i risultati dell'analisi dell'importanza delle feature. I seguenti parametri sono inclusi nel file di analisi dei valori Shapley asimmetrico.
asymmetric_shapley_value — La sezione del file di analisi che contiene i metadati sui risultati del lavoro di spiegazione, tra cui:
explanation_results_path — La posizione Amazon S3 con i risultati della spiegazione
direction — La configurazione fornita dall'utente per il valore di configurazione di
directiongranularità: la configurazione fornita dall'utente per il valore di configurazione di
granularity
Il seguente frammento mostra i parametri menzionati in precedenza in un file di analisi di esempio:
{ "version": "1.0", "explanations": { "asymmetric_shapley_value": { "explanation_results_path": EXPLANATION_RESULTS_S3_URI, "direction": "chronological", "granularity": "timewise", } } }
Le sezioni seguenti descrivono come la struttura dei risultati della spiegazione dipenda dal valore di granularity nella configurazione.
Granularità temporale
Quando la granularità è, timewise l'output è rappresentato nella seguente struttura. Il scores valore rappresenta l'attribuzione per ogni timestamp. Il offset valore rappresenta la previsione del modello sui dati di base e descrive il comportamento del modello quando non riceve dati.
Il frammento seguente mostra un esempio di output per un modello che effettua previsioni per due fasi temporali. Pertanto, tutte le attribuzioni sono un elenco di due elementi in cui la prima voce si riferisce alla prima fase temporale prevista.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]}, ] } { "item_id": "item2", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]}, ] }
Granularità a grana fine
L'esempio seguente mostra i risultati dell'attribuzione quando la granularità è. fine_grained Il offset valore ha lo stesso significato descritto nella sezione precedente. Le attribuzioni vengono calcolate per ogni feature di input in ogni timestamp per una serie temporale di destinazione e le relative serie temporali, se disponibili, e per ogni covariata statica, se disponibile.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]}, {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "static_covariate_1", "scores": [0.6, 0.1]}, {"feature_name": "static_covariate_2", "scores": [0.1, 0.3]}, ] }
In entrambi i casi fine-grained d'uso, timewise i risultati vengono archiviati in JSON formato Lines (.jsonl).
