Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottieni dettagli sui dati e sulla loro qualità
Utilizza il Report della qualità e dei dettagli dei dati per eseguire un'analisi dei dati che hai importato in Data Wrangler. Si consiglia di creare il report dopo l'importazione del set di dati. Puoi utilizzare il report per aiutarti a pulire ed elaborare i tuoi dati. Il report fornisce informazioni come il numero di valori mancanti e il numero di valori anomali. In caso di problemi con i dati, come la perdita o lo squilibrio di dati di destinazione, il report sulle informazioni può richiamare l'attenzione su tali problemi.
Utilizza la procedura seguente per creare un report Qualità e dettagli dei dati. Si presuppone che tu abbia già importato un set di dati nel flusso di Data Wrangler.
Per creare un report Qualità e dettagli dei dati
-
Scegli un + accanto a un nodo nel flusso di Data Wrangler.
-
Seleziona Ottieni dettagli dei dati.
-
In Nome dell'analisi, specifica un nome per il report dei dettagli.
-
(Facoltativo) Nella colonna Destinazione, specifica la colonna di destinazione.
-
In Tipo di problema, specifica Regressione o Classificazione.
-
In Dimensione dei dati, specifica uno dei seguenti valori:
-
50 K: utilizza le prime 50.000 righe del set di dati importato per creare il report.
-
Intero set di dati: utilizza l'intero set di dati che hai importato per creare il report.
Nota
La creazione di un report Data Quality and Insights sull'intero set di dati utilizza un processo di SageMaker elaborazione Amazon. Un SageMaker processo di elaborazione fornisce le risorse di elaborazione aggiuntive necessarie per ottenere informazioni dettagliate su tutti i tuoi dati. Per ulteriori informazioni sui SageMaker processi di elaborazione, vedereCarichi di lavoro di trasformazione dei dati con Processing SageMaker.
-
-
Scegli Create (Crea).
I seguenti argomenti mostrano le sezioni del report:
Puoi scaricare il report o visualizzarlo online. Per scaricare il report, scegli il pulsante di download nell'angolo in alto a destra dello schermo. L'immagine che segue mostra il pulsante.

Riepilogo
Il report dei dettagli contiene un breve riepilogo dei dati che include informazioni generali come valori mancanti, valori non validi, tipi di funzionalità, conteggi dei valori anomali e altro ancora. Può anche includere avvisi di elevata gravità che indicano probabili problemi con i dati. Si consiglia di esaminare gi avvisi.
Di seguito è riportato un esempio di un riepilogo del report.

Colonna di destinazione
Quando crei il report di qualità e dettagli dei dati, Data Wrangler ti offre la possibilità di selezionare una colonna di destinazione. Una colonna di destinazione è una colonna che stai cercando di prevedere. Quando scegli una colonna di destinazione, Data Wrangler crea automaticamente un'analisi della colonna di destinazione. Inoltre classifica le funzionalità in base al loro potere predittivo. Quando selezioni una colonna di destinazione, devi specificare se stai cercando di risolvere una regressione o un problema di classificazione.
Per la classificazione, Data Wrangler mostra una tabella e un istogramma delle classi più comuni. Una classe è una categoria. Presenta inoltre osservazioni, o righe, con un valore di destinazione mancante o non valido.
L'immagine seguente mostra un esempio di analisi della colonna di destinazione per un problema di classificazione.
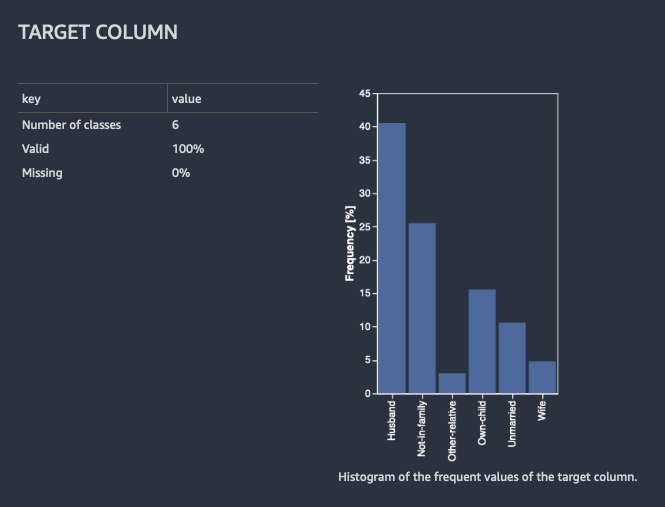
Per la regressione, Data Wrangler mostra un istogramma di tutti i valori nella colonna di destinazione. Presenta inoltre osservazioni, o righe, con un valore obiettivo mancante, non valido o anomalo.
L'immagine seguente mostra un esempio di analisi della colonna di destinazione per un problema di regressione.
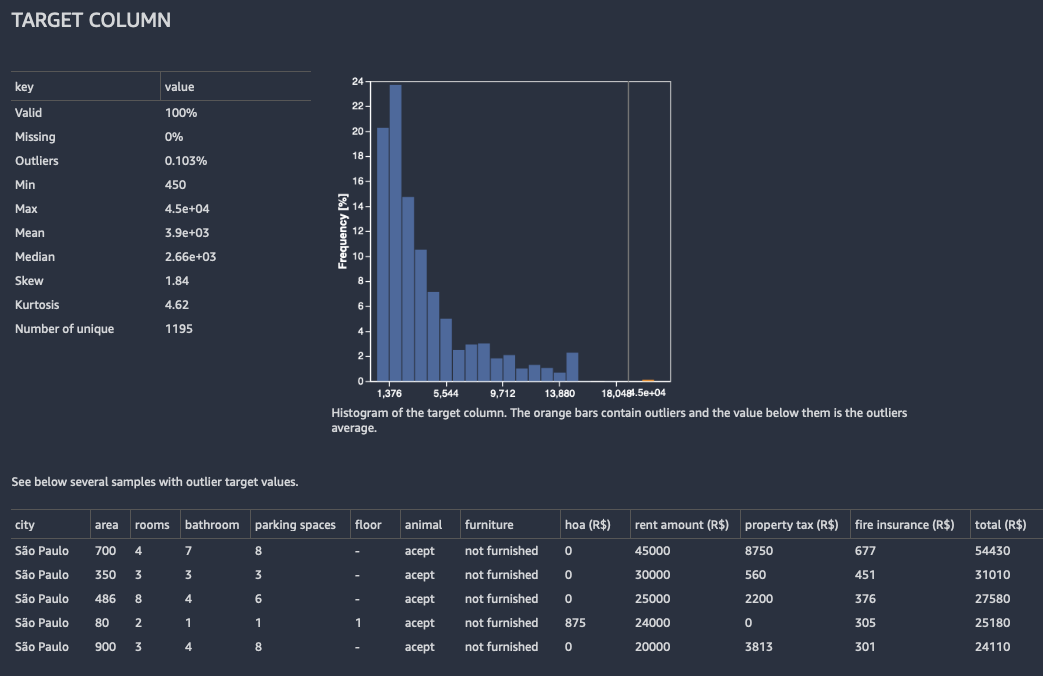
Modello rapido
Il modello rapido fornisce una stima della qualità prevista di un modello che si addestra sulla base dei dati.
Data Wrangler suddivide i dati in file di addestramento e convalida. Utilizza l'80% dei campioni per l’addestramento e il 20% dei valori per la convalida. Per la classificazione, il campione viene suddiviso in strati. Per una suddivisione stratificata, ogni partizione di dati ha la stessa percentuale di etichette. Per problemi di classificazione, è importante avere la stessa percentuale di etichette tra i fold di addestramento e di classificazione. Data Wrangler addestra il modello XGBoost con gli iperparametri predefiniti. Applica l'arresto anticipato dei dati di convalida ed esegue una preelaborazione minima delle funzionalità.
Per i modelli di classificazione, Data Wrangler restituisce sia un riepilogo del modello che una matrice di confusione.
Di seguito è riportato un esempio di riepilogo del modello di classificazione. Per ulteriori informazioni sulle informazioni che restituisce, consulta Definizioni.
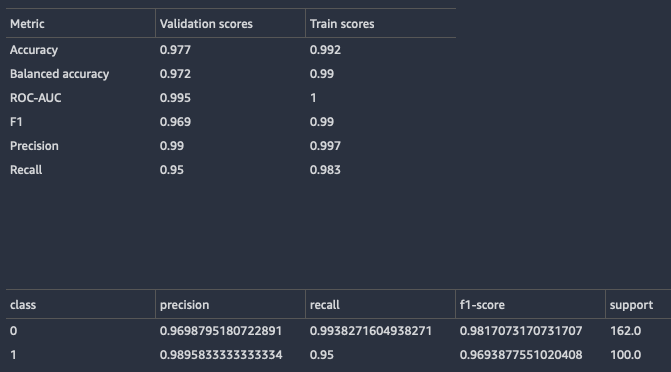
Di seguito è riportato un esempio di matrice di confusione restituita dal modello rapido.

Una matrice di confusione fornisce le seguenti informazioni:
-
Il numero di volte in cui l'etichetta prevista corrisponde all'etichetta vera.
-
Il numero di volte in cui l'etichetta prevista non corrisponde all'etichetta vera.
L'etichetta vera rappresenta un'osservazione effettiva nei dati. Ad esempio, se utilizzi un modello per rilevare transazioni fraudolente, la vera etichetta rappresenta una transazione che è effettivamente fraudolenta o non fraudolenta. L'etichetta prevista rappresenta l'etichetta che il modello assegna ai dati.
Puoi utilizzare la matrice di confusione per vedere quanto bene il modello prevede la presenza o l'assenza di una condizione. Se prevedi transazioni fraudolente, puoi utilizzare la matrice di confusione per avere un'idea sia della sensibilità che della specificità del modello. La sensibilità si riferisce alla capacità del modello di rilevare transazioni fraudolente. La specificità si riferisce alla capacità del modello di evitare di rilevare transazioni non fraudolente come fraudolente.
Di seguito è riportato un esempio di output del modello rapido per un problema di regressione.
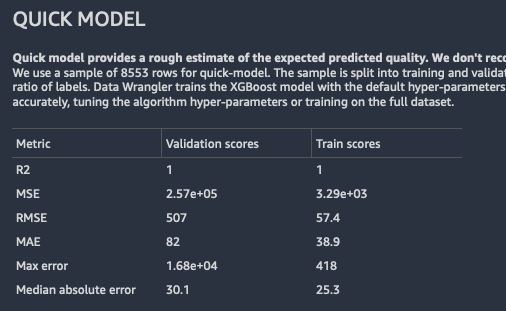
Sintesi delle funzionalità
Quando specifichi una colonna di destinazione, Data Wrangler ordina le funzionalità in base alla loro potenza di previsione. La potenza di previsione viene misurata sui dati dopo averli suddivisi in fold di addestramento all'80% e di convalida al 20%. Data Wrangler inserisce un modello per ogni funzionalità separatamente nella cartella di addestramento. Applica una preelaborazione minima delle funzionalità e misura le prestazioni di previsione sui dati di convalida.
Normalizza i punteggi nell'intervallo [0,1]. I punteggi di previsione più alti indicano le colonne più utili per prevedere da sole l'obiettivo. I punteggi più bassi indicano colonne che non sono predittive della colonna di destinazione.
È raro che una colonna che di per sé non è predittiva lo sia quando viene utilizzata insieme ad altre colonne. Puoi utilizzare con sicurezza i punteggi di previsione per determinare se una funzionalità del tuo set di dati è predittiva.
Un punteggio basso di solito indica che la funzionalità è ridondante. Un punteggio pari a 1 implica capacità predittive perfette, il che spesso indica una perdita dei dati di destinazione. La perdita dei dati di destinazione si verifica in genere quando il set di dati contiene una colonna che non è disponibile al momento della previsione. Ad esempio, potrebbe essere un duplicato della colonna di destinazione.
Di seguito sono riportati alcuni esempi della tabella e dell'istogramma che mostrano il valore di previsione di ciascuna funzionalità.
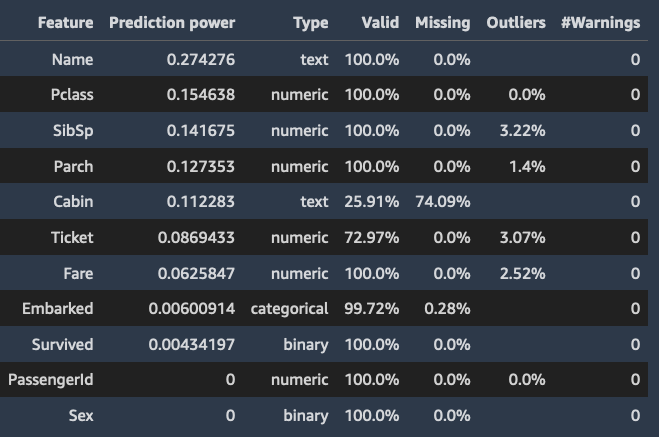

Esempi
Data Wrangler fornisce informazioni sull'eventuale presenza di campioni anomali o duplicati nel set di dati.
Data Wrangler rileva campioni anomali utilizzando l'algoritmo della foresta di isolamento. La foresta di isolamento associa un punteggio di anomalia a ciascun campione (riga) del set di dati. Punteggi di anomalia bassi indicano campioni anomali. I punteggi più alti sono associati a campioni non anomali. I campioni con un punteggio di anomalia negativo sono generalmente considerati anomali e i campioni con un punteggio di anomalia positivo sono considerati non anomali.
Quando si esamina un campione che potrebbe essere anomalo, si consiglia di prestare attenzione ai valori insoliti. Ad esempio, potresti avere valori anomali derivanti da errori nella raccolta e nell'elaborazione dei dati. Consigliamo di utilizzare la conoscenza del dominio e la logica aziendale quando esamini i campioni anomali.
Data Wrangler rileva le righe duplicate e calcola il rapporto tra le righe duplicate nei dati. Alcune origini dati potrebbero includere duplicati validi. Altre origini dati potrebbero avere duplicati che indicano problemi nella raccolta dei dati. I campioni duplicati derivanti da una raccolta errata dei dati potrebbero interferire con i processi di machine learning che si basano sulla suddivisione dei dati in moduli di addestramento e convalida indipendenti.
Di seguito sono riportati alcuni elementi del rapporto di approfondimento che possono essere influenzati da campioni duplicati:
-
Modello rapido
-
Stima della potenza di previsione
-
Ottimizzazione automatica degli iperparametri
È possibile rimuovere campioni duplicati dal set di dati utilizzando la trasformazione Elimina duplicati in Gestisci righe. Data Wrangler mostra le righe duplicate più frequentemente.
Definizioni
Di seguito sono riportate le definizioni dei termini tecnici utilizzati nel report di analisi dei dati.
